 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Selectively Transfer: Reinforced Transfer Learning for Deep Text Matching
Dec 30, 2018
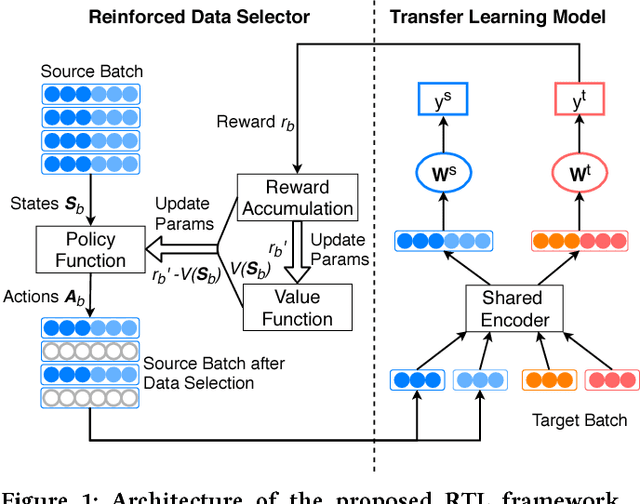
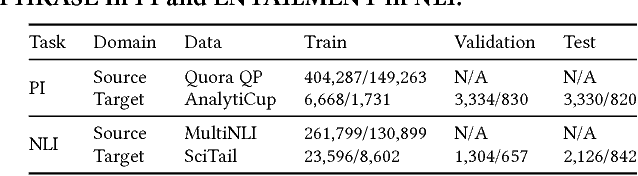
Deep text matching approaches have been widely studied for many applications including question answering and information retrieval systems. To deal with a domain that has insufficient labeled data, these approaches can be used in a Transfer Learning (TL) setting to leverage labeled data from a resource-rich source domain. To achieve better performance, source domain data selection is essential in this process to prevent the "negative transfer" problem. However, the emerging deep transfer models do not fit well with most existing data selection methods, because the data selection policy and the transfer learning model are not jointly trained, leading to sub-optimal training efficiency. In this paper, we propose a novel reinforced data selector to select high-quality source domain data to help the TL model. Specifically, the data selector "acts" on the source domain data to find a subset for optimization of the TL model, and the performance of the TL model can provide "rewards" in turn to update the selector. We build the reinforced data selector based on the actor-critic framework and integrate it to a DNN based transfer learning model, resulting in a Reinforced Transfer Learning (RTL) method. We perform a thorough experimental evaluation on two major tasks for text matching, namely, paraphrase identification and natural language inference. Experimental results show the proposed RTL can significantly improve the performance of the TL model. We further investigate different settings of states, rewards, and policy optimization methods to examine the robustness of our method. Last, we conduct a case study on the selected data and find our method is able to select source domain data whose Wasserstein distance is close to the target domain data. This is reasonable and intuitive as such source domain data can provide more transferability power to the model.
Improving Multilingual Semantic Textual Similarity with Shared Sentence Encoder for Low-resource Languages
Oct 30, 2018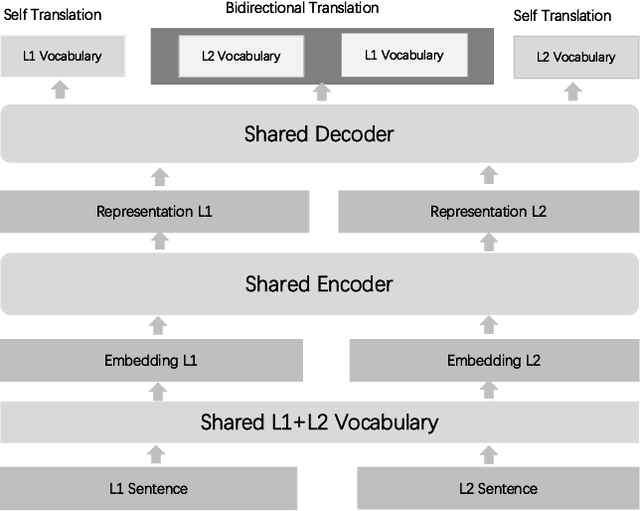

Measuring the semantic similarity between two sentences (or Semantic Textual Similarity - STS) is fundamental in many NLP applications. Despite the remarkable results in supervised settings with adequate labeling, little attention has been paid to this task in low-resource languages with insufficient labeling. Existing approaches mostly leverage machine translation techniques to translate sentences into rich-resource language. These approaches either beget language biases, or be impractical in industrial applications where spoken language scenario is more often and rigorous efficiency is required. In this work, we propose a multilingual framework to tackle the STS task in a low-resource language e.g. Spanish, Arabic , Indonesian and Thai, by utilizing the rich annotation data in a rich resource language, e.g. English. Our approach is extended from a basic monolingual STS framework to a shared multilingual encoder pretrained with translation task to incorporate rich-resource language data. By exploiting the nature of a shared multilingual encoder, one sentence can have multiple representations for different target translation language, which are used in an ensemble model to improve similarity evaluation. We demonstrate the superiority of our method over other state of the art approaches on SemEval STS task by its significant improvement on non-MT method, as well as an online industrial product where MT method fails to beat baseline while our approach still has consistently improvements.
Probabilistic Ensemble of Collaborative Filters
Aug 14, 2018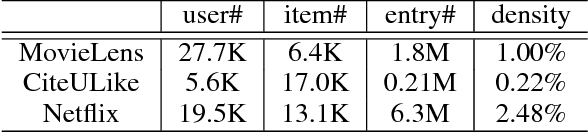

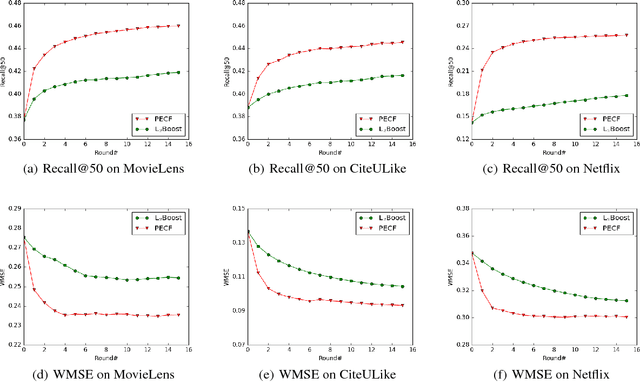
Collaborative filtering is an important technique for recommendation. Whereas it has been repeatedly shown to be effective in previous work, its performance remains unsatisfactory in many real-world applications, especially those where the items or users are highly diverse. In this paper, we explore an ensemble-based framework to enhance the capability of a recommender in handling diverse data. Specifically, we formulate a probabilistic model which integrates the items, the users, as well as the associations between them into a generative process. On top of this formulation, we further derive a progressive algorithm to construct an ensemble of collaborative filters. In each iteration, a new filter is derived from re-weighted entries and incorporated into the ensemble. It is noteworthy that while the algorithmic procedure of our algorithm is apparently similar to boosting, it is derived from an essentially different formulation and thus differs in several key technical aspects. We tested the proposed method on three large datasets, and observed substantial improvement over the state of the art, including L2Boost, an effective method based on boosting.