 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025



Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024



Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
MIRAGE-Bench: Automatic Multilingual Benchmark Arena for Retrieval-Augmented Generation Systems
Oct 17, 2024



Traditional Retrieval-Augmented Generation (RAG) benchmarks rely on different heuristic-based metrics for evaluation, but these require human preferences as ground truth for reference. In contrast, arena-based benchmarks, where two models compete each other, require an expensive Large Language Model (LLM) as a judge for a reliable evaluation. We present an easy and efficient technique to get the best of both worlds. The idea is to train a learning to rank model as a "surrogate" judge using RAG-based evaluation heuristics as input, to produce a synthetic arena-based leaderboard. Using this idea, We develop MIRAGE-Bench, a standardized arena-based multilingual RAG benchmark for 18 diverse languages on Wikipedia. The benchmark is constructed using MIRACL, a retrieval dataset, and extended for multilingual generation evaluation. MIRAGE-Bench evaluates RAG extensively coupling both heuristic features and LLM as a judge evaluator. In our work, we benchmark 19 diverse multilingual-focused LLMs, and achieve a high correlation (Kendall Tau ($\tau$) = 0.909) using our surrogate judge learned using heuristic features with pairwise evaluations and between GPT-4o as a teacher on the MIRAGE-Bench leaderboard using the Bradley-Terry framework. We observe proprietary and large open-source LLMs currently dominate in multilingual RAG. MIRAGE-Bench is available at: https://github.com/vectara/mirage-bench.
Steal My Artworks for Fine-tuning? A Watermarking Framework for Detecting Art Theft Mimicry in Text-to-Image Models
Nov 22, 2023The advancement in text-to-image models has led to astonishing artistic performances. However, several studios and websites illegally fine-tune these models using artists' artworks to mimic their styles for profit, which violates the copyrights of artists and diminishes their motivation to produce original works. Currently, there is a notable lack of research focusing on this issue. In this paper, we propose a novel watermarking framework that detects mimicry in text-to-image models through fine-tuning. This framework embeds subtle watermarks into digital artworks to protect their copyrights while still preserving the artist's visual expression. If someone takes watermarked artworks as training data to mimic an artist's style, these watermarks can serve as detectable indicators. By analyzing the distribution of these watermarks in a series of generated images, acts of fine-tuning mimicry using stolen victim data will be exposed. In various fine-tune scenarios and against watermark attack methods, our research confirms that analyzing the distribution of watermarks in artificially generated images reliably detects unauthorized mimicry.
Generative Steganographic Flow
May 10, 2023



Generative steganography (GS) is a new data hiding manner, featuring direct generation of stego media from secret data. Existing GS methods are generally criticized for their poor performances. In this paper, we propose a novel flow based GS approach -- Generative Steganographic Flow (GSF), which provides direct generation of stego images without cover image. We take the stego image generation and secret data recovery process as an invertible transformation, and build a reversible bijective mapping between input secret data and generated stego images. In the forward mapping, secret data is hidden in the input latent of Glow model to generate stego images. By reversing the mapping, hidden data can be extracted exactly from generated stego images. Furthermore, we propose a novel latent optimization strategy to improve the fidelity of stego images. Experimental results show our proposed GSF has far better performances than SOTA works.
DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely
Dec 20, 2022Summary quality assessment metrics have two categories: reference-based and reference-free. Reference-based metrics are theoretically more accurate but are limited by the availability and quality of the human-written references, which are both difficulty to ensure. This inspires the development of reference-free metrics, which are independent from human-written references, in the past few years. However, existing reference-free metrics cannot be both zero-shot and accurate. In this paper, we propose a zero-shot but accurate reference-free approach in a sneaky way: feeding documents, based upon which summaries generated, as references into reference-based metrics. Experimental results show that this zero-shot approach can give us the best-performing reference-free metrics on nearly all aspects on several recently-released datasets, even beating reference-free metrics specifically trained for this task sometimes. We further investigate what reference-based metrics can benefit from such repurposing and whether our additional tweaks help.
Generative Steganography Network
Aug 14, 2022
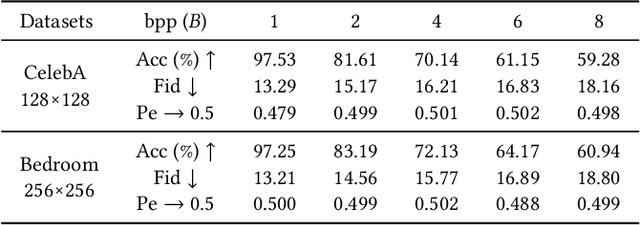
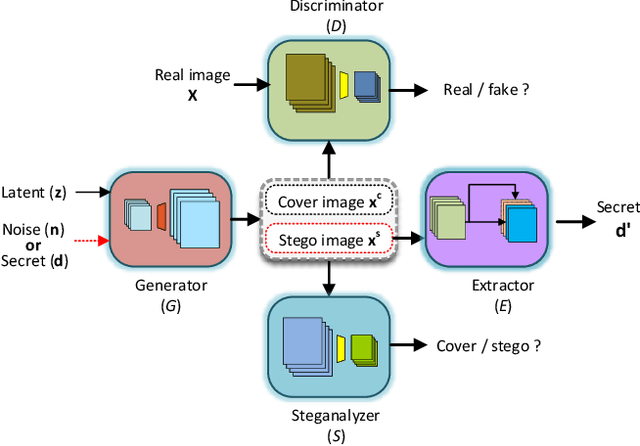
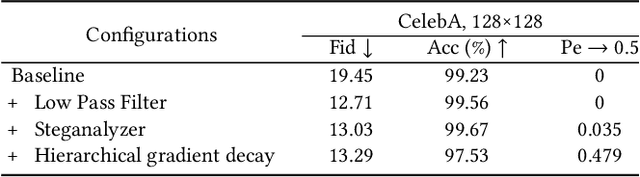
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images. We firstly introduce the mutual information mechanism in GS, which helps to achieve high secret extraction accuracy. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual quality and security of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by concealing the function of generating stego images in a normal generator. A module named secret block is designed to hide secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay (HGD) skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
End-to-end Semantics-based Summary Quality Assessment for Single-document Summarization
May 13, 2020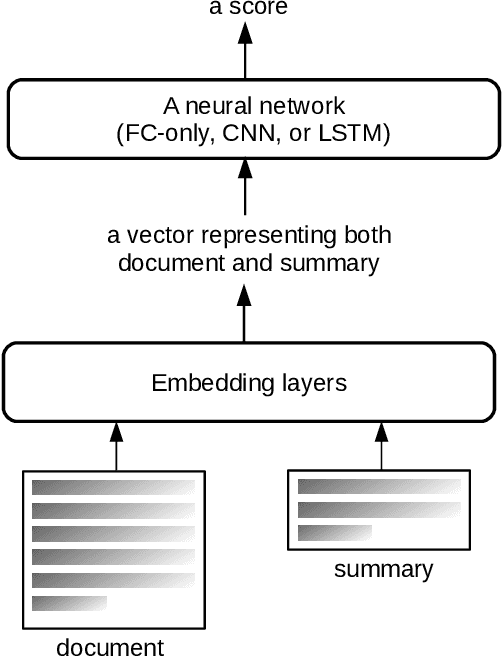
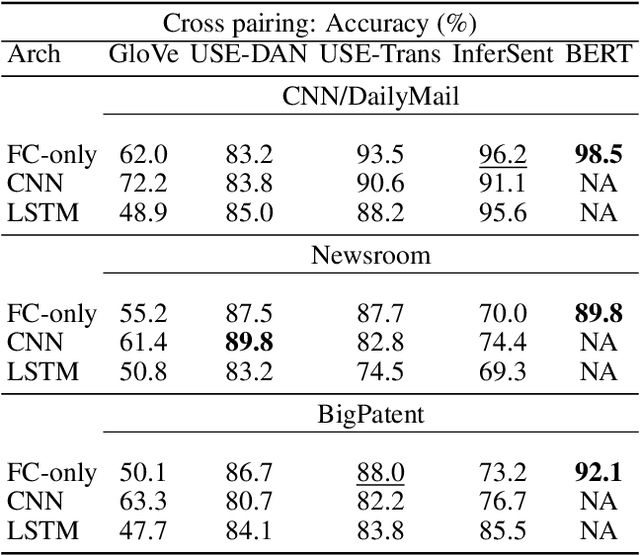

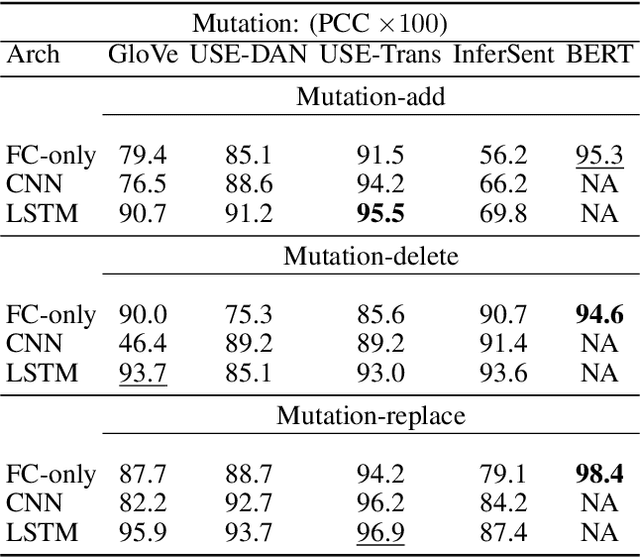
ROUGE is the de facto criterion for summarization research. However, its two major drawbacks limit the research and application of automated summarization systems. First, ROUGE favors lexical similarity instead of semantic similarity, making it especially unfit for abstractive summarization. Second, ROUGE cannot function without a reference summary, which is expensive or impossible to obtain in many cases. Therefore, we introduce a new end-to-end metric system for summary quality assessment by leveraging the semantic similarities of words and/or sentences in deep learning. Models trained in our framework can evaluate a summary directly against the input document, without the need of a reference summary. The proposed approach exhibits very promising results on gold-standard datasets and suggests its great potential to future summarization research. The scores from our models have correlation coefficients up to 0.54 with human evaluations on machine generated summaries in TAC2010. Its performance is also very close to ROUGE metrics'.