 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAD: Self-Evolving Agent for Multi-Turn Service Dialogue
Feb 03, 2026Large Language Models have demonstrated remarkable capabilities in open-domain dialogues. However, current methods exhibit suboptimal performance in service dialogues, as they rely on noisy, low-quality human conversation data. This limitation arises from data scarcity and the difficulty of simulating authentic, goal-oriented user behaviors. To address these issues, we propose SEAD (Self-Evolving Agent for Service Dialogue), a framework that enables agents to learn effective strategies without large-scale human annotations. SEAD decouples user modeling into two components: a Profile Controller that generates diverse user states to manage training curriculum, and a User Role-play Model that focuses on realistic role-playing. This design ensures the environment provides adaptive training scenarios rather than acting as an unfair adversary. Experiments demonstrate that SEAD significantly outperforms Open-source Foundation Models and Closed-source Commercial Models, improving task completion rate by 17.6% and dialogue efficiency by 11.1%. Code is available at: https://github.com/Da1yuqin/SEAD.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Heterogeneous Uncertainty-Guided Composed Image Retrieval with Fine-Grained Probabilistic Learning
Jan 16, 2026Composed Image Retrieval (CIR) enables image search by combining a reference image with modification text. Intrinsic noise in CIR triplets incurs intrinsic uncertainty and threatens the model's robustness. Probabilistic learning approaches have shown promise in addressing such issues; however, they fall short for CIR due to their instance-level holistic modeling and homogeneous treatment of queries and targets. This paper introduces a Heterogeneous Uncertainty-Guided (HUG) paradigm to overcome these limitations. HUG utilizes a fine-grained probabilistic learning framework, where queries and targets are represented by Gaussian embeddings that capture detailed concepts and uncertainties. We customize heterogeneous uncertainty estimations for multi-modal queries and uni-modal targets. Given a query, we capture uncertainties not only regarding uni-modal content quality but also multi-modal coordination, followed by a provable dynamic weighting mechanism to derive comprehensive query uncertainty. We further design uncertainty-guided objectives, including query-target holistic contrast and fine-grained contrasts with comprehensive negative sampling strategies, which effectively enhance discriminative learning. Experiments on benchmarks demonstrate HUG's effectiveness beyond state-of-the-art baselines, with faithful analysis justifying the technical contributions.
Towards Efficient Low-rate Image Compression with Frequency-aware Diffusion Prior Refinement
Jan 15, 2026Recent advancements in diffusion-based generative priors have enabled visually plausible image compression at extremely low bit rates. However, existing approaches suffer from slow sampling processes and suboptimal bit allocation due to fragmented training paradigms. In this work, we propose Accelerate \textbf{Diff}usion-based Image Compression via \textbf{C}onsistency Prior \textbf{R}efinement (DiffCR), a novel compression framework for efficient and high-fidelity image reconstruction. At the heart of DiffCR is a Frequency-aware Skip Estimation (FaSE) module that refines the $ε$-prediction prior from a pre-trained latent diffusion model and aligns it with compressed latents at different timesteps via Frequency Decoupling Attention (FDA). Furthermore, a lightweight consistency estimator enables fast \textbf{two-step decoding} by preserving the semantic trajectory of diffusion sampling. Without updating the backbone diffusion model, DiffCR achieves substantial bitrate savings (27.2\% BD-rate (LPIPS) and 65.1\% BD-rate (PSNR)) and over $10\times$ speed-up compared to SOTA diffusion-based compression baselines.
Structured Personality Control and Adaptation for LLM Agents
Jan 15, 2026Large Language Models (LLMs) are increasingly shaping human-computer interaction (HCI), from personalized assistants to social simulations. Beyond language competence, researchers are exploring whether LLMs can exhibit human-like characteristics that influence engagement, decision-making, and perceived realism. Personality, in particular, is critical, yet existing approaches often struggle to achieve both nuanced and adaptable expression. We present a framework that models LLM personality via Jungian psychological types, integrating three mechanisms: a dominant-auxiliary coordination mechanism for coherent core expression, a reinforcement-compensation mechanism for temporary adaptation to context, and a reflection mechanism that drives long-term personality evolution. This design allows the agent to maintain nuanced traits while dynamically adjusting to interaction demands and gradually updating its underlying structure. Personality alignment is evaluated using Myers-Briggs Type Indicator questionnaires and tested under diverse challenge scenarios as a preliminary structured assessment. Findings suggest that evolving, personality-aware LLMs can support coherent, context-sensitive interactions, enabling naturalistic agent design in HCI.
Large Foundation Model for Ads Recommendation
Aug 20, 2025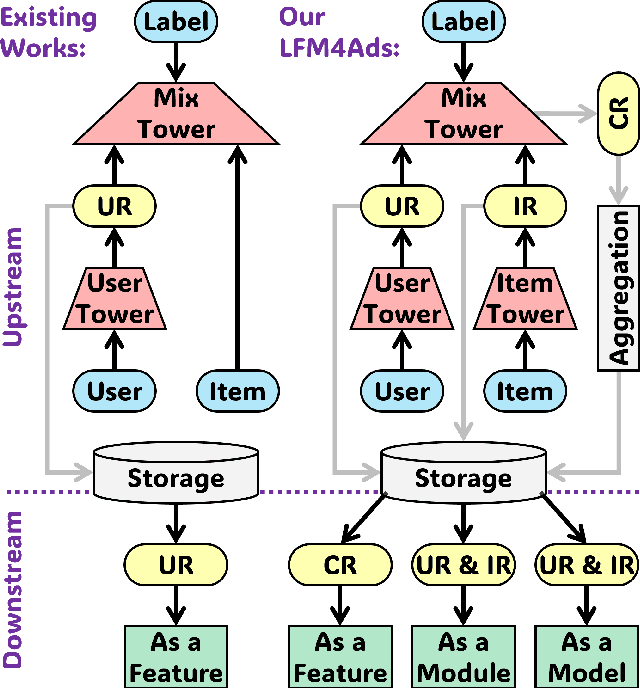
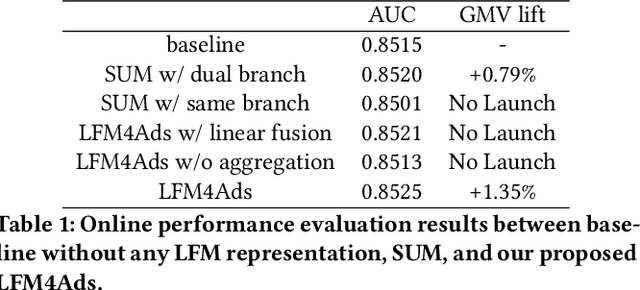
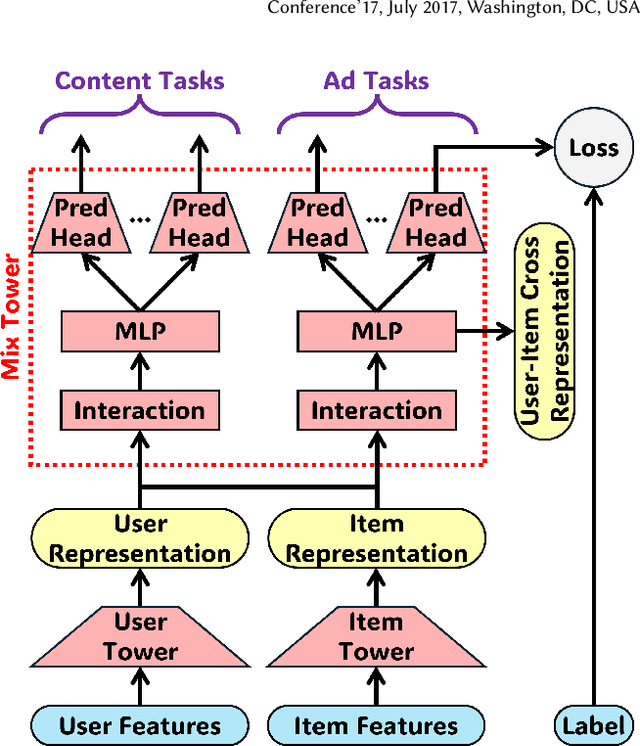
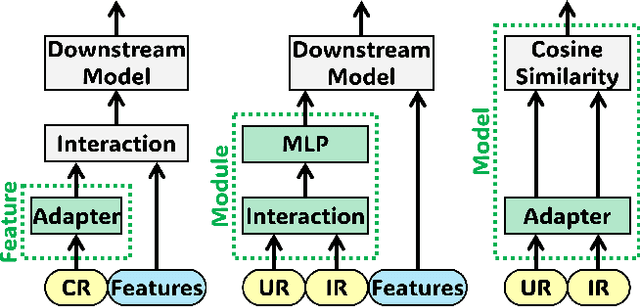
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
PMA: Towards Parameter-Efficient Point Cloud Understanding via Point Mamba Adapter
May 27, 2025Applying pre-trained models to assist point cloud understanding has recently become a mainstream paradigm in 3D perception. However, existing application strategies are straightforward, utilizing only the final output of the pre-trained model for various task heads. It neglects the rich complementary information in the intermediate layer, thereby failing to fully unlock the potential of pre-trained models. To overcome this limitation, we propose an orthogonal solution: Point Mamba Adapter (PMA), which constructs an ordered feature sequence from all layers of the pre-trained model and leverages Mamba to fuse all complementary semantics, thereby promoting comprehensive point cloud understanding. Constructing this ordered sequence is non-trivial due to the inherent isotropy of 3D space. Therefore, we further propose a geometry-constrained gate prompt generator (G2PG) shared across different layers, which applies shared geometric constraints to the output gates of the Mamba and dynamically optimizes the spatial order, thus enabling more effective integration of multi-layer information. Extensive experiments conducted on challenging point cloud datasets across various tasks demonstrate that our PMA elevates the capability for point cloud understanding to a new level by fusing diverse complementary intermediate features. Code is available at https://github.com/zyh16143998882/PMA.
EvdCLIP: Improving Vision-Language Retrieval with Entity Visual Descriptions from Large Language Models
May 24, 2025Vision-language retrieval (VLR) has attracted significant attention in both academia and industry, which involves using text (or images) as queries to retrieve corresponding images (or text). However, existing methods often neglect the rich visual semantics knowledge of entities, thus leading to incorrect retrieval results. To address this problem, we propose the Entity Visual Description enhanced CLIP (EvdCLIP), designed to leverage the visual knowledge of entities to enrich queries. Specifically, since humans recognize entities through visual cues, we employ a large language model (LLM) to generate Entity Visual Descriptions (EVDs) as alignment cues to complement textual data. These EVDs are then integrated into raw queries to create visually-rich, EVD-enhanced queries. Furthermore, recognizing that EVD-enhanced queries may introduce noise or low-quality expansions, we develop a novel, trainable EVD-aware Rewriter (EaRW) for vision-language retrieval tasks. EaRW utilizes EVD knowledge and the generative capabilities of the language model to effectively rewrite queries. With our specialized training strategy, EaRW can generate high-quality and low-noise EVD-enhanced queries. Extensive quantitative and qualitative experiments on image-text retrieval benchmarks validate the superiority of EvdCLIP on vision-language retrieval tasks.
Action is All You Need: Dual-Flow Generative Ranking Network for Recommendation
May 22, 2025We introduce the Dual-Flow Generative Ranking Network (DFGR), a two-stream architecture designed for recommendation systems. DFGR integrates innovative interaction patterns between real and fake flows within the QKV modules of the self-attention mechanism, enhancing both training and inference efficiency. This approach effectively addresses a key limitation observed in Meta's proposed HSTU generative recommendation approach, where heterogeneous information volumes are mapped into identical vector spaces, leading to training instability. Unlike traditional recommendation models, DFGR only relies on user history behavior sequences and minimal attribute information, eliminating the need for extensive manual feature engineering. Comprehensive evaluations on open-source and industrial datasets reveal DFGR's superior performance compared to established baselines such as DIN, DCN, DIEN, and DeepFM. We also investigate optimal parameter allocation strategies under computational constraints, establishing DFGR as an efficient and effective next-generation generate ranking paradigm.
LARES: Latent Reasoning for Sequential Recommendation
May 22, 2025Sequential recommender systems have become increasingly important in real-world applications that model user behavior sequences to predict their preferences. However, existing sequential recommendation methods predominantly rely on non-reasoning paradigms, which may limit the model's computational capacity and result in suboptimal recommendation performance. To address these limitations, we present LARES, a novel and scalable LAtent REasoning framework for Sequential recommendation that enhances model's representation capabilities through increasing the computation density of parameters by depth-recurrent latent reasoning. Our proposed approach employs a recurrent architecture that allows flexible expansion of reasoning depth without increasing parameter complexity, thereby effectively capturing dynamic and intricate user interest patterns. A key difference of LARES lies in refining all input tokens at each implicit reasoning step to improve the computation utilization. To fully unlock the model's reasoning potential, we design a two-phase training strategy: (1) Self-supervised pre-training (SPT) with dual alignment objectives; (2) Reinforcement post-training (RPT). During the first phase, we introduce trajectory-level alignment and step-level alignment objectives, which enable the model to learn recommendation-oriented latent reasoning patterns without requiring supplementary annotated data. The subsequent phase utilizes reinforcement learning (RL) to harness the model's exploratory ability, further refining its reasoning capabilities. Comprehensive experiments on real-world benchmarks demonstrate our framework's superior performance. Notably, LARES exhibits seamless compatibility with existing advanced models, further improving their recommendation performance.