 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvdCLIP: Improving Vision-Language Retrieval with Entity Visual Descriptions from Large Language Models
May 24, 2025Vision-language retrieval (VLR) has attracted significant attention in both academia and industry, which involves using text (or images) as queries to retrieve corresponding images (or text). However, existing methods often neglect the rich visual semantics knowledge of entities, thus leading to incorrect retrieval results. To address this problem, we propose the Entity Visual Description enhanced CLIP (EvdCLIP), designed to leverage the visual knowledge of entities to enrich queries. Specifically, since humans recognize entities through visual cues, we employ a large language model (LLM) to generate Entity Visual Descriptions (EVDs) as alignment cues to complement textual data. These EVDs are then integrated into raw queries to create visually-rich, EVD-enhanced queries. Furthermore, recognizing that EVD-enhanced queries may introduce noise or low-quality expansions, we develop a novel, trainable EVD-aware Rewriter (EaRW) for vision-language retrieval tasks. EaRW utilizes EVD knowledge and the generative capabilities of the language model to effectively rewrite queries. With our specialized training strategy, EaRW can generate high-quality and low-noise EVD-enhanced queries. Extensive quantitative and qualitative experiments on image-text retrieval benchmarks validate the superiority of EvdCLIP on vision-language retrieval tasks.
UniBiomed: A Universal Foundation Model for Grounded Biomedical Image Interpretation
Apr 30, 2025Multi-modal interpretation of biomedical images opens up novel opportunities in biomedical image analysis. Conventional AI approaches typically rely on disjointed training, i.e., Large Language Models (LLMs) for clinical text generation and segmentation models for target extraction, which results in inflexible real-world deployment and a failure to leverage holistic biomedical information. To this end, we introduce UniBiomed, the first universal foundation model for grounded biomedical image interpretation. UniBiomed is based on a novel integration of Multi-modal Large Language Model (MLLM) and Segment Anything Model (SAM), which effectively unifies the generation of clinical texts and the segmentation of corresponding biomedical objects for grounded interpretation. In this way, UniBiomed is capable of tackling a wide range of biomedical tasks across ten diverse biomedical imaging modalities. To develop UniBiomed, we curate a large-scale dataset comprising over 27 million triplets of images, annotations, and text descriptions across ten imaging modalities. Extensive validation on 84 internal and external datasets demonstrated that UniBiomed achieves state-of-the-art performance in segmentation, disease recognition, region-aware diagnosis, visual question answering, and report generation. Moreover, unlike previous models that rely on clinical experts to pre-diagnose images and manually craft precise textual or visual prompts, UniBiomed can provide automated and end-to-end grounded interpretation for biomedical image analysis. This represents a novel paradigm shift in clinical workflows, which will significantly improve diagnostic efficiency. In summary, UniBiomed represents a novel breakthrough in biomedical AI, unlocking powerful grounded interpretation capabilities for more accurate and efficient biomedical image analysis.
FreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
ConceptCLIP: Towards Trustworthy Medical AI via Concept-Enhanced Contrastive Langauge-Image Pre-training
Jan 26, 2025Trustworthiness is essential for the precise and interpretable application of artificial intelligence (AI) in medical imaging. Traditionally, precision and interpretability have been addressed as separate tasks, namely medical image analysis and explainable AI, each developing its own models independently. In this study, for the first time, we investigate the development of a unified medical vision-language pre-training model that can achieve both accurate analysis and interpretable understanding of medical images across various modalities. To build the model, we construct MedConcept-23M, a large-scale dataset comprising 23 million medical image-text pairs extracted from 6.2 million scientific articles, enriched with concepts from the Unified Medical Language System (UMLS). Based on MedConcept-23M, we introduce ConceptCLIP, a medical AI model utilizing concept-enhanced contrastive language-image pre-training. The pre-training of ConceptCLIP involves two primary components: image-text alignment learning (IT-Align) and patch-concept alignment learning (PC-Align). This dual alignment strategy enhances the model's capability to associate specific image regions with relevant concepts, thereby improving both the precision of analysis and the interpretability of the AI system. We conducted extensive experiments on 5 diverse types of medical image analysis tasks, spanning 51 subtasks across 10 image modalities, with the broadest range of downstream tasks. The results demonstrate the effectiveness of the proposed vision-language pre-training model. Further explainability analysis across 6 modalities reveals that ConceptCLIP achieves superior performance, underscoring its robust ability to advance explainable AI in medical imaging. These findings highlight ConceptCLIP's capability in promoting trustworthy AI in the field of medicine.
MedDr: Diagnosis-Guided Bootstrapping for Large-Scale Medical Vision-Language Learning
Apr 23, 2024



The rapid advancement of large-scale vision-language models has showcased remarkable capabilities across various tasks. However, the lack of extensive and high-quality image-text data in medicine has greatly hindered the development of large-scale medical vision-language models. In this work, we present a diagnosis-guided bootstrapping strategy that exploits both image and label information to construct vision-language datasets. Based on the constructed dataset, we developed MedDr, a generalist foundation model for healthcare capable of handling diverse medical data modalities, including radiology, pathology, dermatology, retinography, and endoscopy. Moreover, during inference, we propose a simple but effective retrieval-augmented medical diagnosis strategy, which enhances the model's generalization ability. Extensive experiments on visual question answering, medical report generation, and medical image diagnosis demonstrate the superiority of our method.
Examining User-Friendly and Open-Sourced Large GPT Models: A Survey on Language, Multimodal, and Scientific GPT Models
Aug 27, 2023Generative pre-trained transformer (GPT) models have revolutionized the field of natural language processing (NLP) with remarkable performance in various tasks and also extend their power to multimodal domains. Despite their success, large GPT models like GPT-4 face inherent limitations such as considerable size, high computational requirements, complex deployment processes, and closed development loops. These constraints restrict their widespread adoption and raise concerns regarding their responsible development and usage. The need for user-friendly, relatively small, and open-sourced alternative GPT models arises from the desire to overcome these limitations while retaining high performance. In this survey paper, we provide an examination of alternative open-sourced models of large GPTs, focusing on user-friendly and relatively small models that facilitate easier deployment and accessibility. Through this extensive survey, we aim to equip researchers, practitioners, and enthusiasts with a thorough understanding of user-friendly and relatively small open-sourced models of large GPTs, their current state, challenges, and future research directions, inspiring the development of more efficient, accessible, and versatile GPT models that cater to the broader scientific community and advance the field of general artificial intelligence. The source contents are continuously updating in https://github.com/GPT-Alternatives/gpt_alternatives.
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation
Aug 08, 2023



Temporal sentence grounding (TSG) aims to locate a specific moment from an untrimmed video with a given natural language query. Recently, weakly supervised methods still have a large performance gap compared to fully supervised ones, while the latter requires laborious timestamp annotations. In this study, we aim to reduce the annotation cost yet keep competitive performance for TSG task compared to fully supervised ones. To achieve this goal, we investigate a recently proposed glance-supervised temporal sentence grounding task, which requires only single frame annotation (referred to as glance annotation) for each query. Under this setup, we propose a Dynamic Gaussian prior based Grounding framework with Glance annotation (D3G), which consists of a Semantic Alignment Group Contrastive Learning module (SA-GCL) and a Dynamic Gaussian prior Adjustment module (DGA). Specifically, SA-GCL samples reliable positive moments from a 2D temporal map via jointly leveraging Gaussian prior and semantic consistency, which contributes to aligning the positive sentence-moment pairs in the joint embedding space. Moreover, to alleviate the annotation bias resulting from glance annotation and model complex queries consisting of multiple events, we propose the DGA module, which adjusts the distribution dynamically to approximate the ground truth of target moments. Extensive experiments on three challenging benchmarks verify the effectiveness of the proposed D3G. It outperforms the state-of-the-art weakly supervised methods by a large margin and narrows the performance gap compared to fully supervised methods. Code is available at https://github.com/solicucu/D3G.
Vision-Language Pre-training with Object Contrastive Learning for 3D Scene Understanding
May 18, 2023In recent years, vision language pre-training frameworks have made significant progress in natural language processing and computer vision, achieving remarkable performance improvement on various downstream tasks. However, when extended to point cloud data, existing works mainly focus on building task-specific models, and fail to extract universal 3D vision-language embedding that generalize well. We carefully investigate three common tasks in semantic 3D scene understanding, and derive key insights into the development of a pre-training model. Motivated by these observations, we propose a vision-language pre-training framework 3DVLP (3D vision-language pre-training with object contrastive learning), which transfers flexibly on 3D vision-language downstream tasks. 3DVLP takes visual grounding as the proxy task and introduces Object-level IoU-guided Detection (OID) loss to obtain high-quality proposals in the scene. Moreover, we design Object-level Cross-Contrastive alignment (OCC) task and Object-level Self-Contrastive learning (OSC) task to align the objects with descriptions and distinguish different objects in the scene, respectively. Extensive experiments verify the excellent performance of 3DVLP on three 3D vision-language tasks, reflecting its superiority in semantic 3D scene understanding.
VLMAE: Vision-Language Masked Autoencoder
Aug 19, 2022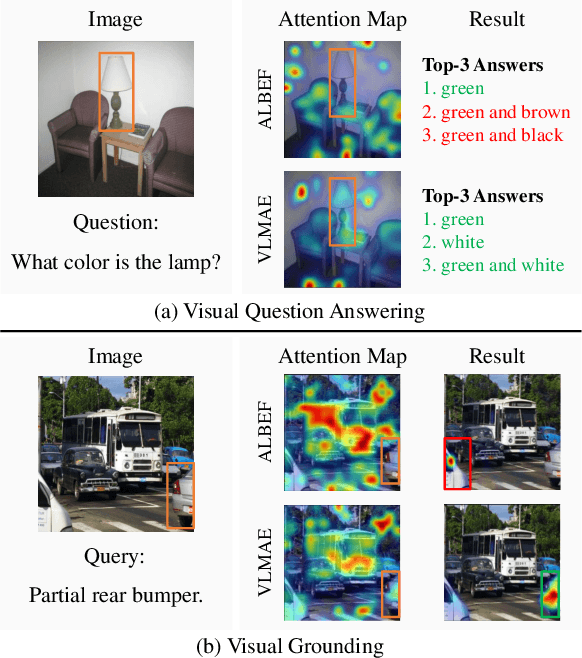
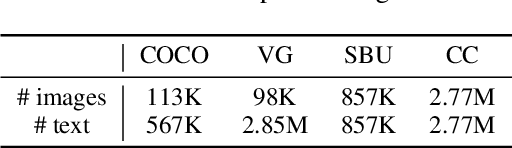
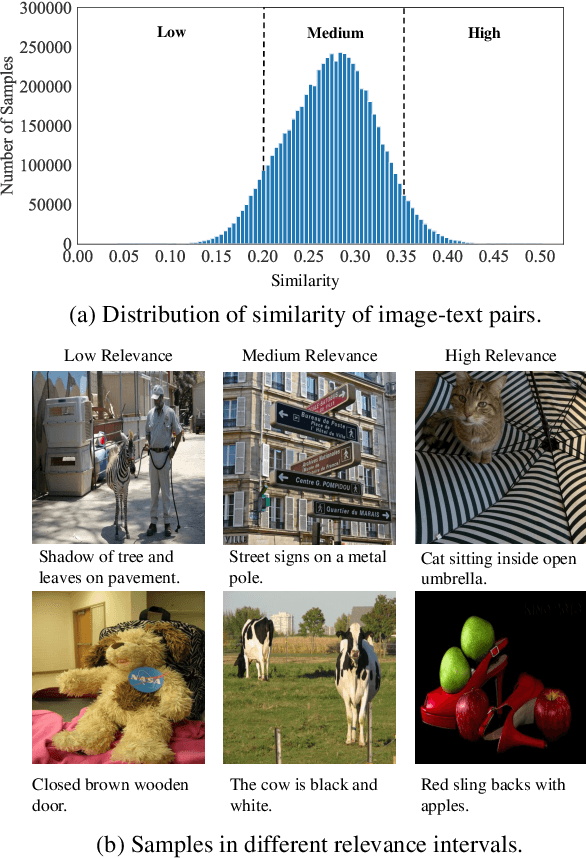
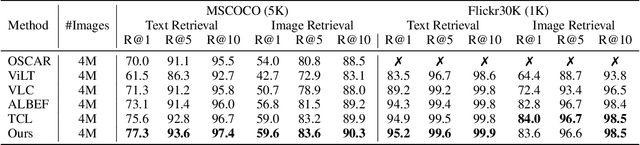
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.
Exploiting Feature Diversity for Make-up Temporal Video Grounding
Aug 12, 2022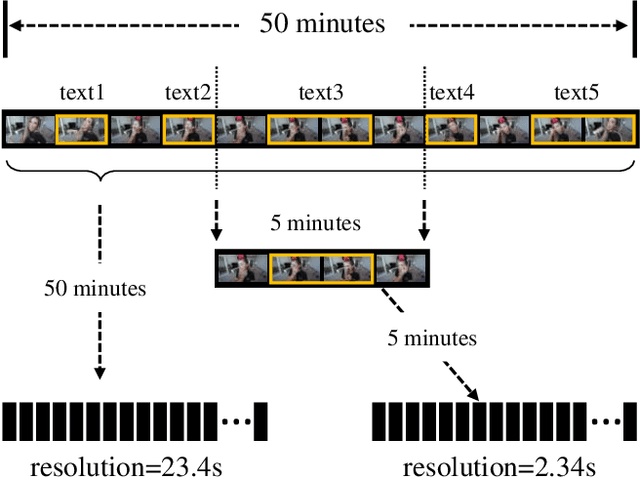
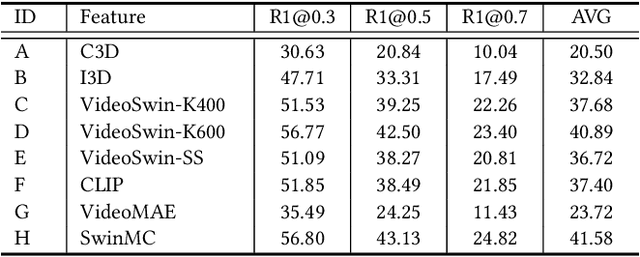
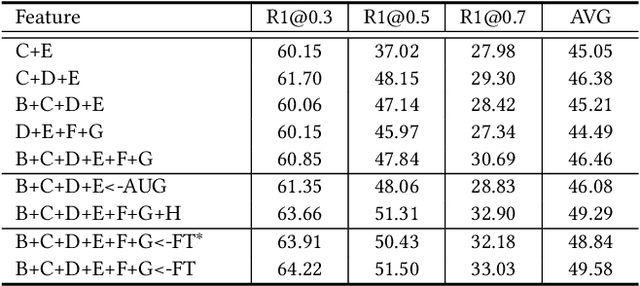

This technical report presents the 3rd winning solution for MTVG, a new task introduced in the 4-th Person in Context (PIC) Challenge at ACM MM 2022. MTVG aims at localizing the temporal boundary of the step in an untrimmed video based on a textual description. The biggest challenge of this task is the fi ne-grained video-text semantics of make-up steps. However, current methods mainly extract video features using action-based pre-trained models. As actions are more coarse-grained than make-up steps, action-based features are not sufficient to provide fi ne-grained cues. To address this issue,we propose to achieve fi ne-grained representation via exploiting feature diversities. Specifically, we proposed a series of methods from feature extraction, network optimization, to model ensemble. As a result, we achieved 3rd place in the MTVG competition.