 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA machine learning model for skillful climate system prediction
May 06, 2025Climate system models (CSMs), through integrating cross-sphere interactions among the atmosphere, ocean, land, and cryosphere, have emerged as pivotal tools for deciphering climate dynamics and improving forecasting capabilities. Recent breakthroughs in artificial intelligence (AI)-driven meteorological modeling have demonstrated remarkable success in single-sphere systems and partially spheres coupled systems. However, the development of a fully coupled AI-based climate system model encompassing atmosphere-ocean-land-sea ice interactions has remained an unresolved challenge. This paper introduces FengShun-CSM, an AI-based CSM model that provides 60-day global daily forecasts for 29 critical variables across atmospheric, oceanic, terrestrial, and cryospheric domains. The model significantly outperforms the European Centre for Medium-Range Weather Forecasts (ECMWF) subseasonal-to-seasonal (S2S) model in predicting most variables, particularly precipitation, land surface, and oceanic components. This enhanced capability is primarily attributed to its improved representation of intra-seasonal variability modes, most notably the Madden-Julian Oscillation (MJO). Remarkably, FengShun-CSM exhibits substantial potential in predicting subseasonal extreme events. Such breakthroughs will advance its applications in meteorological disaster mitigation, marine ecosystem conservation, and agricultural productivity enhancement. Furthermore, it validates the feasibility of developing AI-powered CSMs through machine learning technologies, establishing a transformative paradigm for next-generation Earth system modeling.
How to systematically develop an effective AI-based bias correction model?
Apr 21, 2025



This study introduces ReSA-ConvLSTM, an artificial intelligence (AI) framework for systematic bias correction in numerical weather prediction (NWP). We propose three innovations by integrating dynamic climatological normalization, ConvLSTM with temporal causality constraints, and residual self-attention mechanisms. The model establishes a physics-aware nonlinear mapping between ECMWF forecasts and ERA5 reanalysis data. Using 41 years (1981-2021) of global atmospheric data, the framework reduces systematic biases in 2-m air temperature (T2m), 10-m winds (U10/V10), and sea-level pressure (SLP), achieving up to 20% RMSE reduction over 1-7 day forecasts compared to operational ECMWF outputs. The lightweight architecture (10.6M parameters) enables efficient generalization to multiple variables and downstream applications, reducing retraining time by 85% for cross-variable correction while improving ocean model skill through bias-corrected boundary conditions. The ablation experiments demonstrate that our innovations significantly improve the model's correction performance, suggesting that incorporating variable characteristics into the model helps enhance forecasting skills.
Efficient Distributed Retrieval-Augmented Generation for Enhancing Language Model Performance
Apr 16, 2025



Small language models (SLMs) support efficient deployments on resource-constrained edge devices, but their limited capacity compromises inference performance. Retrieval-augmented generation (RAG) is a promising solution to enhance model performance by integrating external databases, without requiring intensive on-device model retraining. However, large-scale public databases and user-specific private contextual documents are typically located on the cloud and the device separately, while existing RAG implementations are primarily centralized. To bridge this gap, we propose DRAGON, a distributed RAG framework to enhance on-device SLMs through both general and personal knowledge without the risk of leaking document privacy. Specifically, DRAGON decomposes multi-document RAG into multiple parallel token generation processes performed independently and locally on the cloud and the device, and employs a newly designed Speculative Aggregation, a dual-side speculative algorithm to avoid frequent output synchronization between the cloud and device. A new scheduling algorithm is further introduced to identify the optimal aggregation side based on real-time network conditions. Evaluations on real-world hardware testbed demonstrate a significant performance improvement of DRAGON-up to 1.9x greater gains over standalone SLM compared to the centralized RAG, substantial reduction in per-token latency, and negligible Time to First Token (TTFT) overhead.
Seedream 3.0 Technical Report
Apr 16, 2025



We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
DreamFuse: Adaptive Image Fusion with Diffusion Transformer
Apr 11, 2025



Image fusion seeks to seamlessly integrate foreground objects with background scenes, producing realistic and harmonious fused images. Unlike existing methods that directly insert objects into the background, adaptive and interactive fusion remains a challenging yet appealing task. It requires the foreground to adjust or interact with the background context, enabling more coherent integration. To address this, we propose an iterative human-in-the-loop data generation pipeline, which leverages limited initial data with diverse textual prompts to generate fusion datasets across various scenarios and interactions, including placement, holding, wearing, and style transfer. Building on this, we introduce DreamFuse, a novel approach based on the Diffusion Transformer (DiT) model, to generate consistent and harmonious fused images with both foreground and background information. DreamFuse employs a Positional Affine mechanism to inject the size and position of the foreground into the background, enabling effective foreground-background interaction through shared attention. Furthermore, we apply Localized Direct Preference Optimization guided by human feedback to refine DreamFuse, enhancing background consistency and foreground harmony. DreamFuse achieves harmonious fusion while generalizing to text-driven attribute editing of the fused results. Experimental results demonstrate that our method outperforms state-of-the-art approaches across multiple metrics.
A Convex and Global Solution for the P$n$P Problem in 2D Forward-Looking Sonar
Apr 10, 2025



The perspective-$n$-point (P$n$P) problem is important for robotic pose estimation. It is well studied for optical cameras, but research is lacking for 2D forward-looking sonar (FLS) in underwater scenarios due to the vastly different imaging principles. In this paper, we demonstrate that, despite the nonlinearity inherent in sonar image formation, the P$n$P problem for 2D FLS can still be effectively addressed within a point-to-line (PtL) 3D registration paradigm through orthographic approximation. The registration is then resolved by a duality-based optimal solver, ensuring the global optimality. For coplanar cases, a null space analysis is conducted to retrieve the solutions from the dual formulation, enabling the methods to be applied to more general cases. Extensive simulations have been conducted to systematically evaluate the performance under different settings. Compared to non-reprojection-optimized state-of-the-art (SOTA) methods, the proposed approach achieves significantly higher precision. When both methods are optimized, ours demonstrates comparable or slightly superior precision.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
Quantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
Mar 07, 2025Robustness has become a critical attribute for the deployment of RAG systems in real-world applications. Existing research focuses on robustness to explicit noise (e.g., document semantics) but overlooks spurious features (a.k.a. implicit noise). While previous works have explored spurious features in LLMs, they are limited to specific features (e.g., formats) and narrow scenarios (e.g., ICL). In this work, we statistically confirm the presence of spurious features in the RAG paradigm, a robustness problem caused by the sensitivity of LLMs to semantic-agnostic features. Moreover, we provide a comprehensive taxonomy of spurious features and empirically quantify their impact through controlled experiments. Further analysis reveals that not all spurious features are harmful and they can even be beneficial sometimes. Extensive evaluation results across multiple LLMs suggest that spurious features are a widespread and challenging problem in the field of RAG. The code and dataset will be released to facilitate future research. We release all codes and data at: $\\\href{https://github.com/maybenotime/RAG-SpuriousFeatures}{https://github.com/maybenotime/RAG-SpuriousFeatures}$.
IterPref: Focal Preference Learning for Code Generation via Iterative Debugging
Mar 04, 2025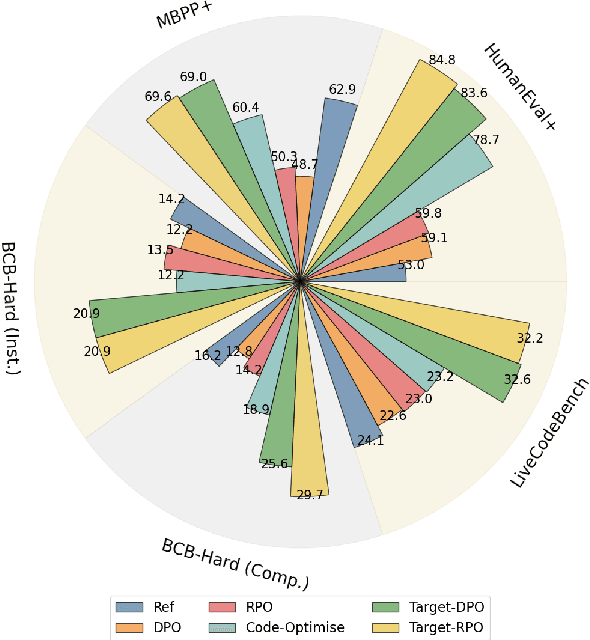
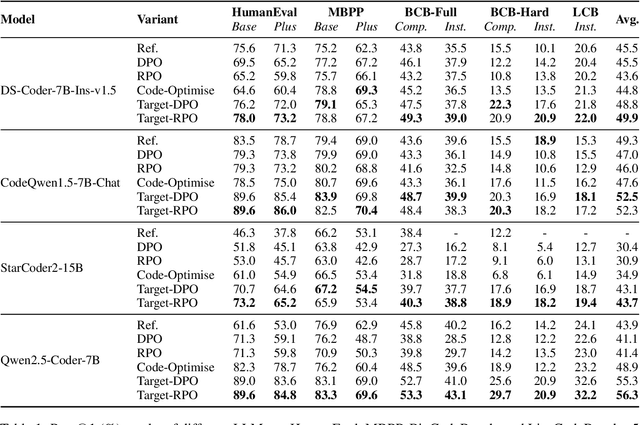
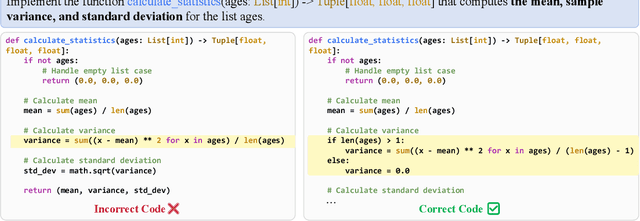

Preference learning enhances Code LLMs beyond supervised fine-tuning by leveraging relative quality comparisons. Existing methods construct preference pairs from candidates based on test case success, treating the higher pass rate sample as positive and the lower as negative. However, this approach does not pinpoint specific errors in the code, which prevents the model from learning more informative error correction patterns, as aligning failing code as a whole lacks the granularity needed to capture meaningful error-resolution relationships. To address these issues, we propose IterPref, a new preference alignment framework that mimics human iterative debugging to refine Code LLMs. IterPref explicitly locates error regions and aligns the corresponding tokens via a tailored DPO algorithm. To generate informative pairs, we introduce the CodeFlow dataset, where samples are iteratively refined until passing tests, with modifications capturing error corrections. Extensive experiments show that a diverse suite of Code LLMs equipped with IterPref achieves significant performance gains in code generation and improves on challenging tasks like BigCodeBench. In-depth analysis reveals that IterPref yields fewer errors. Our code and data will be made publicaly available.