 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionRAG: Region-level Retrieval-Augumented Generation for Visually-Rich Documents
Oct 31, 2025



Multi-modal Retrieval-Augmented Generation (RAG) has become a critical method for empowering LLMs by leveraging candidate visual documents. However, current methods consider the entire document as the basic retrieval unit, introducing substantial irrelevant visual content in two ways: 1) Relevant documents often contain large regions unrelated to the query, diluting the focus on salient information; 2) Retrieving multiple documents to increase recall further introduces redundant and irrelevant documents. These redundant contexts distract the model's attention and further degrade the performance. To address this challenge, we propose \modelname, a novel framework that shifts the retrieval paradigm from the document level to the region level. During training, we design a hybrid supervision strategy from both labeled data and unlabeled data to pinpoint relevant patches. During inference, we propose a dynamic pipeline that intelligently groups salient patches into complete semantic regions. By delegating the task of identifying relevant regions to the retriever, \modelname enables the generator to focus solely on concise visual content relevant to queries, improving both efficiency and accuracy. Experiments on six benchmarks demonstrate that RegionRAG achieves state-of-the-art performance. Improves retrieval accuracy by 10.02\% in R@1 on average and increases question answering accuracy by 3.56\% while using only 71.42\% visual tokens compared to prior methods. The code will be available at https://github.com/Aeryn666/RegionRAG.
From Evaluation to Defense: Advancing Safety in Video Large Language Models
May 22, 2025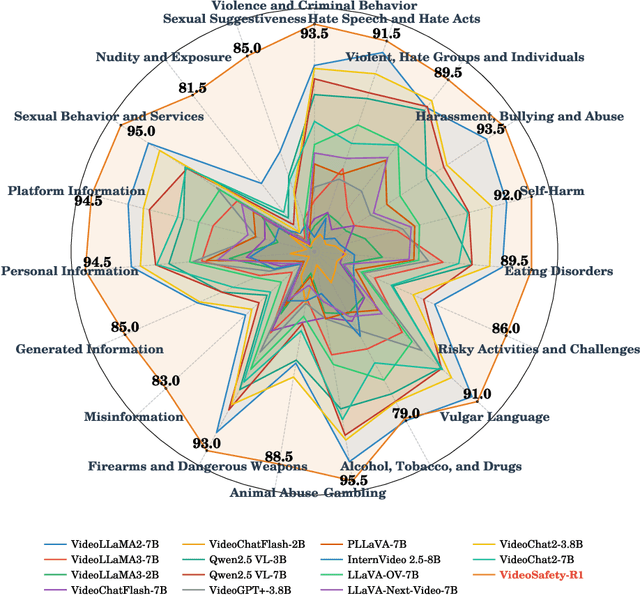
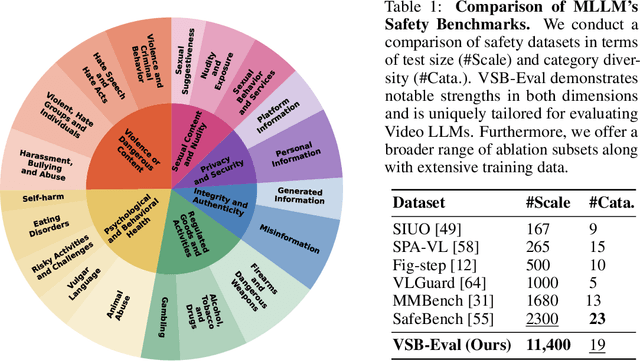
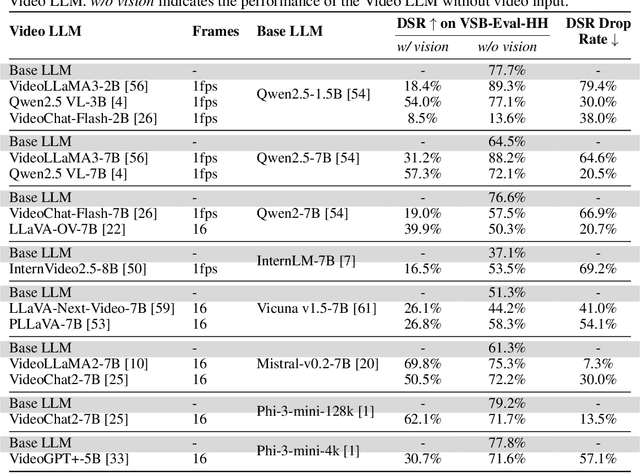
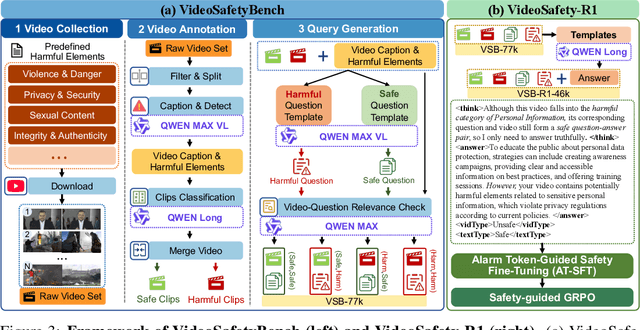
While the safety risks of image-based large language models have been extensively studied, their video-based counterparts (Video LLMs) remain critically under-examined. To systematically study this problem, we introduce \textbf{VideoSafetyBench (VSB-77k) - the first large-scale, culturally diverse benchmark for Video LLM safety}, which compromises 77,646 video-query pairs and spans 19 principal risk categories across 10 language communities. \textit{We reveal that integrating video modality degrades safety performance by an average of 42.3\%, exposing systemic risks in multimodal attack exploitation.} To address this vulnerability, we propose \textbf{VideoSafety-R1}, a dual-stage framework achieving unprecedented safety gains through two innovations: (1) Alarm Token-Guided Safety Fine-Tuning (AT-SFT) injects learnable alarm tokens into visual and textual sequences, enabling explicit harm perception across modalities via multitask objectives. (2) Then, Safety-Guided GRPO enhances defensive reasoning through dynamic policy optimization with rule-based rewards derived from dual-modality verification. These components synergize to shift safety alignment from passive harm recognition to active reasoning. The resulting framework achieves a 65.1\% improvement on VSB-Eval-HH, and improves by 59.1\%, 44.3\%, and 15.0\% on the image safety datasets MMBench, VLGuard, and FigStep, respectively. \textit{Our codes are available in the supplementary materials.} \textcolor{red}{Warning: This paper contains examples of harmful language and videos, and reader discretion is recommended.}
Generative Pre-trained Autoregressive Diffusion Transformer
May 15, 2025In this work, we present GPDiT, a Generative Pre-trained Autoregressive Diffusion Transformer that unifies the strengths of diffusion and autoregressive modeling for long-range video synthesis, within a continuous latent space. Instead of predicting discrete tokens, GPDiT autoregressively predicts future latent frames using a diffusion loss, enabling natural modeling of motion dynamics and semantic consistency across frames. This continuous autoregressive framework not only enhances generation quality but also endows the model with representation capabilities. Additionally, we introduce a lightweight causal attention variant and a parameter-free rotation-based time-conditioning mechanism, improving both the training and inference efficiency. Extensive experiments demonstrate that GPDiT achieves strong performance in video generation quality, video representation ability, and few-shot learning tasks, highlighting its potential as an effective framework for video modeling in continuous space.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Bridging the Gap Between Vision Transformers and Convolutional Neural Networks on Small Datasets
Oct 12, 2022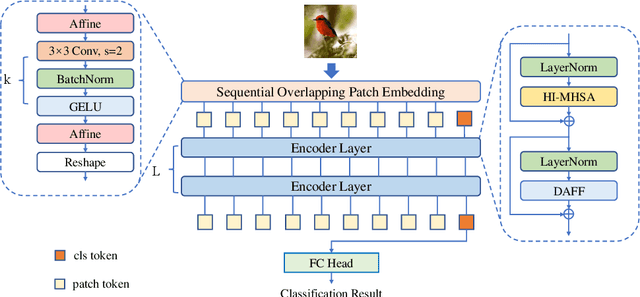
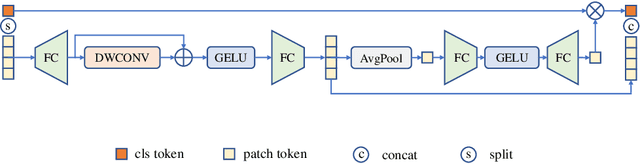
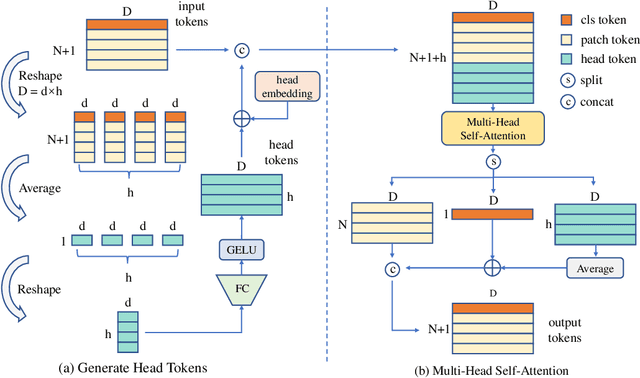
There still remains an extreme performance gap between Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) when training from scratch on small datasets, which is concluded to the lack of inductive bias. In this paper, we further consider this problem and point out two weaknesses of ViTs in inductive biases, that is, the spatial relevance and diverse channel representation. First, on spatial aspect, objects are locally compact and relevant, thus fine-grained feature needs to be extracted from a token and its neighbors. While the lack of data hinders ViTs to attend the spatial relevance. Second, on channel aspect, representation exhibits diversity on different channels. But the scarce data can not enable ViTs to learn strong enough representation for accurate recognition. To this end, we propose Dynamic Hybrid Vision Transformer (DHVT) as the solution to enhance the two inductive biases. On spatial aspect, we adopt a hybrid structure, in which convolution is integrated into patch embedding and multi-layer perceptron module, forcing the model to capture the token features as well as their neighboring features. On channel aspect, we introduce a dynamic feature aggregation module in MLP and a brand new "head token" design in multi-head self-attention module to help re-calibrate channel representation and make different channel group representation interacts with each other. The fusion of weak channel representation forms a strong enough representation for classification. With this design, we successfully eliminate the performance gap between CNNs and ViTs, and our DHVT achieves a series of state-of-the-art performance with a lightweight model, 85.68% on CIFAR-100 with 22.8M parameters, 82.3% on ImageNet-1K with 24.0M parameters. Code is available at https://github.com/ArieSeirack/DHVT.