 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
RewardDance: Reward Scaling in Visual Generation
Sep 10, 2025Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.
KLIPA: A Knowledge Graph and LLM-Driven QA Framework for IP Analysis
Sep 09, 2025



Effectively managing intellectual property is a significant challenge. Traditional methods for patent analysis depend on labor-intensive manual searches and rigid keyword matching. These approaches are often inefficient and struggle to reveal the complex relationships hidden within large patent datasets, hindering strategic decision-making. To overcome these limitations, we introduce KLIPA, a novel framework that leverages a knowledge graph and a large language model (LLM) to significantly advance patent analysis. Our approach integrates three key components: a structured knowledge graph to map explicit relationships between patents, a retrieval-augmented generation(RAG) system to uncover contextual connections, and an intelligent agent that dynamically determines the optimal strategy for resolving user queries. We validated KLIPA on a comprehensive, real-world patent database, where it demonstrated substantial improvements in knowledge extraction, discovery of novel connections, and overall operational efficiency. This combination of technologies enhances retrieval accuracy, reduces reliance on domain experts, and provides a scalable, automated solution for any organization managing intellectual property, including technology corporations and legal firms, allowing them to better navigate the complexities of strategic innovation and competitive intelligence.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025



Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Decoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
Inference-Time Alignment Control for Diffusion Models with Reinforcement Learning Guidance
Aug 28, 2025Denoising-based generative models, particularly diffusion and flow matching algorithms, have achieved remarkable success. However, aligning their output distributions with complex downstream objectives, such as human preferences, compositional accuracy, or data compressibility, remains challenging. While reinforcement learning (RL) fine-tuning methods, inspired by advances in RL from human feedback (RLHF) for large language models, have been adapted to these generative frameworks, current RL approaches are suboptimal for diffusion models and offer limited flexibility in controlling alignment strength after fine-tuning. In this work, we reinterpret RL fine-tuning for diffusion models through the lens of stochastic differential equations and implicit reward conditioning. We introduce Reinforcement Learning Guidance (RLG), an inference-time method that adapts Classifier-Free Guidance (CFG) by combining the outputs of the base and RL fine-tuned models via a geometric average. Our theoretical analysis shows that RLG's guidance scale is mathematically equivalent to adjusting the KL-regularization coefficient in standard RL objectives, enabling dynamic control over the alignment-quality trade-off without further training. Extensive experiments demonstrate that RLG consistently improves the performance of RL fine-tuned models across various architectures, RL algorithms, and downstream tasks, including human preferences, compositional control, compressibility, and text rendering. Furthermore, RLG supports both interpolation and extrapolation, thereby offering unprecedented flexibility in controlling generative alignment. Our approach provides a practical and theoretically sound solution for enhancing and controlling diffusion model alignment at inference. The source code for RLG is publicly available at the Github: https://github.com/jinluo12345/Reinforcement-learning-guidance.
ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models
Aug 25, 20253D inpainting often relies on multi-view 2D image inpainting, where the inherent inconsistencies across different inpainted views can result in blurred textures, spatial discontinuities, and distracting visual artifacts. These inconsistencies pose significant challenges when striving for accurate and realistic 3D object completion, particularly in applications that demand high fidelity and structural coherence. To overcome these limitations, we propose ObjFiller-3D, a novel method designed for the completion and editing of high-quality and consistent 3D objects. Instead of employing a conventional 2D image inpainting model, our approach leverages a curated selection of state-of-the-art video editing model to fill in the masked regions of 3D objects. We analyze the representation gap between 3D and videos, and propose an adaptation of a video inpainting model for 3D scene inpainting. In addition, we introduce a reference-based 3D inpainting method to further enhance the quality of reconstruction. Experiments across diverse datasets show that compared to previous methods, ObjFiller-3D produces more faithful and fine-grained reconstructions (PSNR of 26.6 vs. NeRFiller (15.9) and LPIPS of 0.19 vs. Instant3dit (0.25)). Moreover, it demonstrates strong potential for practical deployment in real-world 3D editing applications. Project page: https://objfiller3d.github.io/ Code: https://github.com/objfiller3d/ObjFiller-3D .
SurveyGen-I: Consistent Scientific Survey Generation with Evolving Plans and Memory-Guided Writing
Aug 20, 2025Survey papers play a critical role in scientific communication by consolidating progress across a field. Recent advances in Large Language Models (LLMs) offer a promising solution by automating key steps in the survey-generation pipeline, such as retrieval, structuring, and summarization. However, existing LLM-based approaches often struggle with maintaining coherence across long, multi-section surveys and providing comprehensive citation coverage. To address these limitations, we introduce SurveyGen-I, an automatic survey generation framework that combines coarse-to-fine retrieval, adaptive planning, and memory-guided generation. SurveyGen-I first performs survey-level retrieval to construct the initial outline and writing plan, and then dynamically refines both during generation through a memory mechanism that stores previously written content and terminology, ensuring coherence across subsections. When the system detects insufficient context, it triggers fine-grained subsection-level retrieval. During generation, SurveyGen-I leverages this memory mechanism to maintain coherence across subsections. Experiments across four scientific domains demonstrate that SurveyGen-I consistently outperforms previous works in content quality, consistency, and citation coverage.
UGM2N: An Unsupervised and Generalizable Mesh Movement Network via M-Uniform Loss
Aug 12, 2025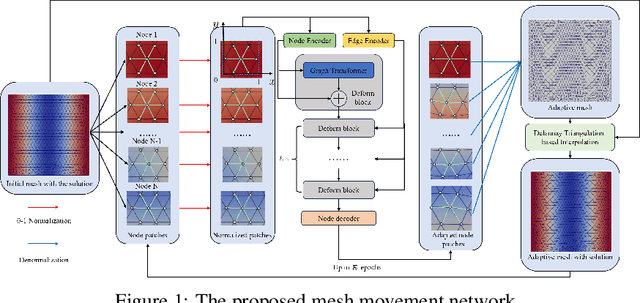
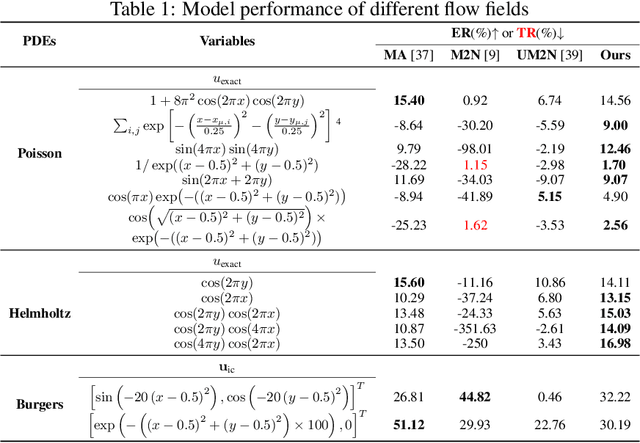
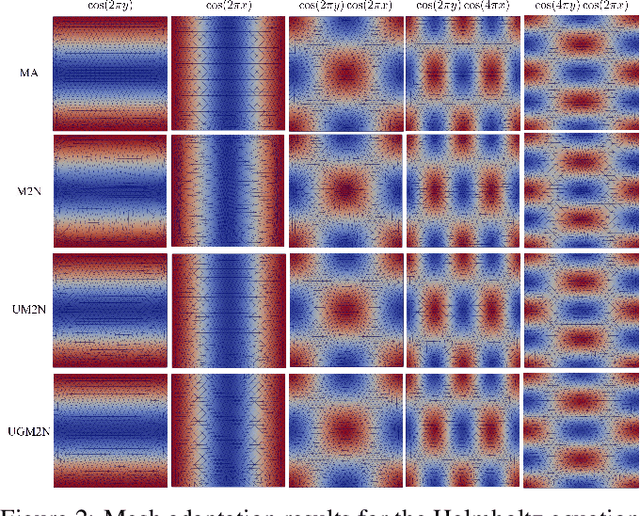
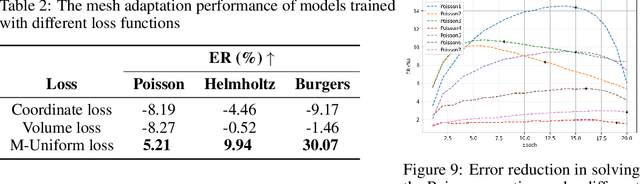
Partial differential equations (PDEs) form the mathematical foundation for modeling physical systems in science and engineering, where numerical solutions demand rigorous accuracy-efficiency tradeoffs. Mesh movement techniques address this challenge by dynamically relocating mesh nodes to rapidly-varying regions, enhancing both simulation accuracy and computational efficiency. However, traditional approaches suffer from high computational complexity and geometric inflexibility, limiting their applicability, and existing supervised learning-based approaches face challenges in zero-shot generalization across diverse PDEs and mesh topologies.In this paper, we present an Unsupervised and Generalizable Mesh Movement Network (UGM2N). We first introduce unsupervised mesh adaptation through localized geometric feature learning, eliminating the dependency on pre-adapted meshes. We then develop a physics-constrained loss function, M-Uniform loss, that enforces mesh equidistribution at the nodal level.Experimental results demonstrate that the proposed network exhibits equation-agnostic generalization and geometric independence in efficient mesh adaptation. It demonstrates consistent superiority over existing methods, including robust performance across diverse PDEs and mesh geometries, scalability to multi-scale resolutions and guaranteed error reduction without mesh tangling.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.