 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Guided Symbolic Regression: Towards Scientific Consistency in Equation Discovery
Feb 16, 2026Symbolic Regression (SR) aims to discover interpretable equations from observational data, with the potential to reveal underlying principles behind natural phenomena. However, existing approaches often fall into the Pseudo-Equation Trap: producing equations that fit observations well but remain inconsistent with fundamental scientific principles. A key reason is that these approaches are dominated by empirical risk minimization, lacking explicit constraints to ensure scientific consistency. To bridge this gap, we propose PG-SR, a prior-guided SR framework built upon a three-stage pipeline consisting of warm-up, evolution, and refinement. Throughout the pipeline, PG-SR introduces a prior constraint checker that explicitly encodes domain priors as executable constraint programs, and employs a Prior Annealing Constrained Evaluation (PACE) mechanism during the evolution stage to progressively steer discovery toward scientifically consistent regions. Theoretically, we prove that PG-SR reduces the Rademacher complexity of the hypothesis space, yielding tighter generalization bounds and establishing a guarantee against pseudo-equations. Experimentally, PG-SR outperforms state-of-the-art baselines across diverse domains, maintaining robustness to varying prior quality, noisy data, and data scarcity.
UGM2N: An Unsupervised and Generalizable Mesh Movement Network via M-Uniform Loss
Aug 12, 2025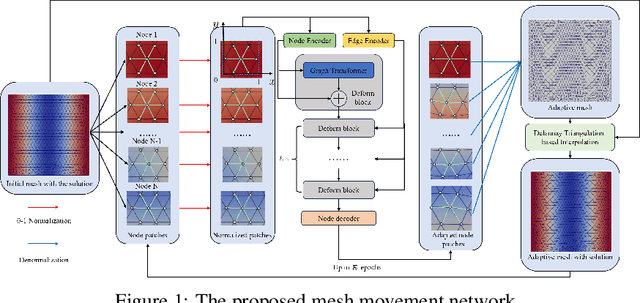
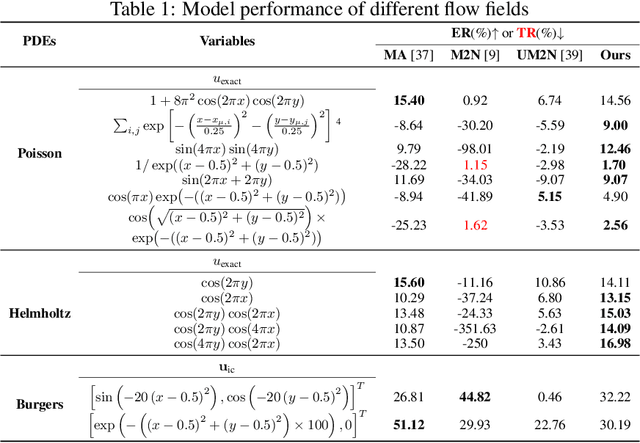
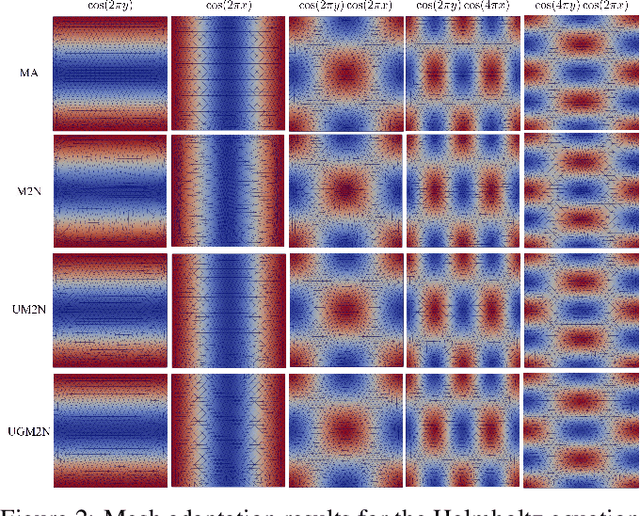
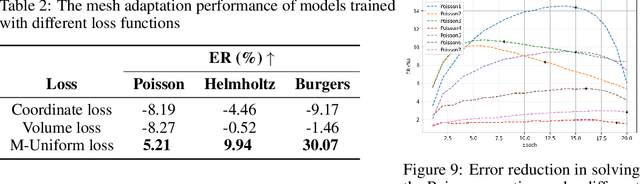
Partial differential equations (PDEs) form the mathematical foundation for modeling physical systems in science and engineering, where numerical solutions demand rigorous accuracy-efficiency tradeoffs. Mesh movement techniques address this challenge by dynamically relocating mesh nodes to rapidly-varying regions, enhancing both simulation accuracy and computational efficiency. However, traditional approaches suffer from high computational complexity and geometric inflexibility, limiting their applicability, and existing supervised learning-based approaches face challenges in zero-shot generalization across diverse PDEs and mesh topologies.In this paper, we present an Unsupervised and Generalizable Mesh Movement Network (UGM2N). We first introduce unsupervised mesh adaptation through localized geometric feature learning, eliminating the dependency on pre-adapted meshes. We then develop a physics-constrained loss function, M-Uniform loss, that enforces mesh equidistribution at the nodal level.Experimental results demonstrate that the proposed network exhibits equation-agnostic generalization and geometric independence in efficient mesh adaptation. It demonstrates consistent superiority over existing methods, including robust performance across diverse PDEs and mesh geometries, scalability to multi-scale resolutions and guaranteed error reduction without mesh tangling.
State-space Decomposition Model for Video Prediction Considering Long-term Motion Trend
Apr 17, 2024Stochastic video prediction enables the consideration of uncertainty in future motion, thereby providing a better reflection of the dynamic nature of the environment. Stochastic video prediction methods based on image auto-regressive recurrent models need to feed their predictions back into the latent space. Conversely, the state-space models, which decouple frame synthesis and temporal prediction, proves to be more efficient. However, inferring long-term temporal information about motion and generalizing to dynamic scenarios under non-stationary assumptions remains an unresolved challenge. In this paper, we propose a state-space decomposition stochastic video prediction model that decomposes the overall video frame generation into deterministic appearance prediction and stochastic motion prediction. Through adaptive decomposition, the model's generalization capability to dynamic scenarios is enhanced. In the context of motion prediction, obtaining a prior on the long-term trend of future motion is crucial. Thus, in the stochastic motion prediction branch, we infer the long-term motion trend from conditional frames to guide the generation of future frames that exhibit high consistency with the conditional frames. Experimental results demonstrate that our model outperforms baselines on multiple datasets.