 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMPO: Scaling Test-time Training for Large Reasoning Models
Apr 21, 2026Test-time training (TTT) adapts model parameters on unlabeled test instances during inference time, which continuously extends capabilities beyond the reach of offline training. Despite initial gains, existing TTT methods for LRMs plateau quickly and do not benefit from additional test-time compute. Without external calibration, the self-generated reward signal increasingly drifts as the policy model evolves, leading to both performance plateaus and diversity collapse. We propose TEMPO, a TTT framework that interleaves policy refinement on unlabeled questions with periodic critic recalibration on a labeled dataset. By formalizing this alternating procedure through the Expectation-Maximization (EM) algorithm, we reveal that prior methods can be interpreted as incomplete variants that omit the crucial recalibration step. Reintroducing this step tightens the evidence lower bound (ELBO) and enables sustained improvement. Across diverse model families (Qwen3 and OLMO3) and reasoning tasks, TEMPO improves OLMO3-7B on AIME 2024 from 33.0% to 51.1% and Qwen3-14B from 42.3% to 65.8%, while maintaining high diversity.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
Self-Guided Function Calling in Large Language Models via Stepwise Experience Recall
Aug 21, 2025Function calling enables large language models (LLMs) to interact with external systems by leveraging tools and APIs. When faced with multi-step tool usage, LLMs still struggle with tool selection, parameter generation, and tool-chain planning. Existing methods typically rely on manually designing task-specific demonstrations, or retrieving from a curated library. These approaches demand substantial expert effort and prompt engineering becomes increasingly complex and inefficient as tool diversity and task difficulty scale. To address these challenges, we propose a self-guided method, Stepwise Experience Recall (SEER), which performs fine-grained, stepwise retrieval from a continually updated experience pool. Instead of relying on static or manually curated library, SEER incrementally augments the experience pool with past successful trajectories, enabling continuous expansion of the pool and improved model performance over time. Evaluated on the ToolQA benchmark, SEER achieves an average improvement of 6.1\% on easy and 4.7\% on hard questions. We further test SEER on $\tau$-bench, which includes two real-world domains. Powered by Qwen2.5-7B and Qwen2.5-72B models, SEER demonstrates substantial accuracy gains of 7.44\% and 23.38\%, respectively.
UGM2N: An Unsupervised and Generalizable Mesh Movement Network via M-Uniform Loss
Aug 12, 2025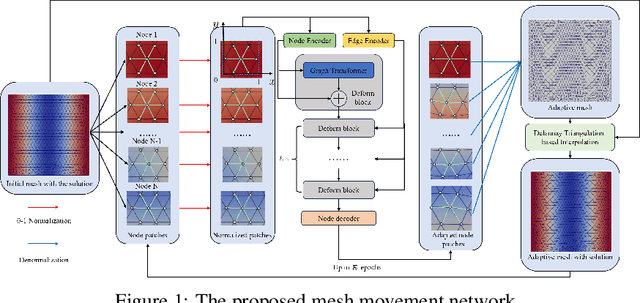
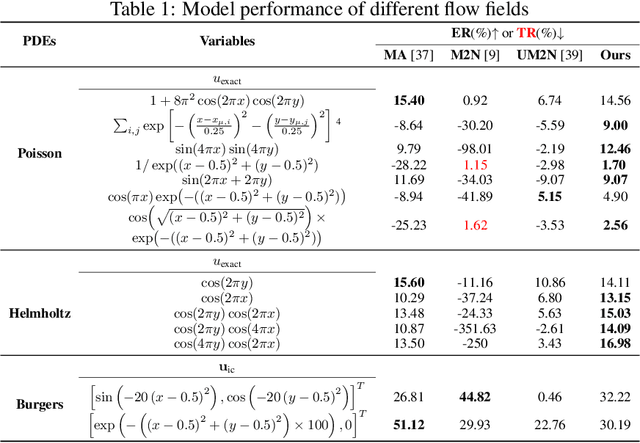
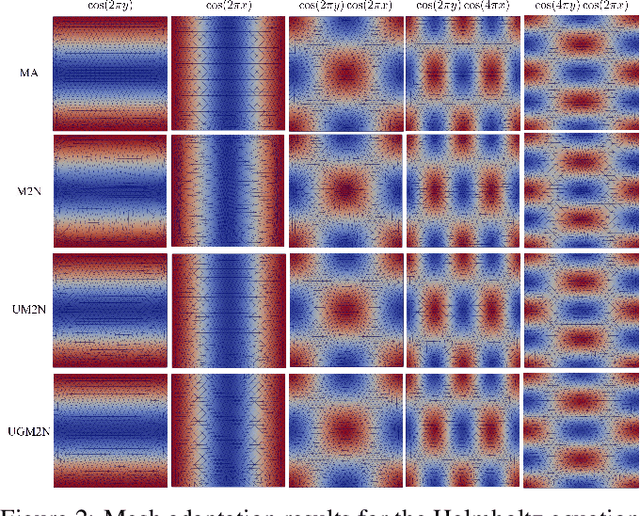
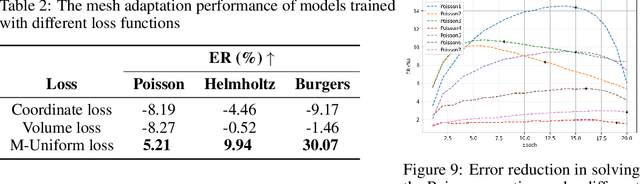
Partial differential equations (PDEs) form the mathematical foundation for modeling physical systems in science and engineering, where numerical solutions demand rigorous accuracy-efficiency tradeoffs. Mesh movement techniques address this challenge by dynamically relocating mesh nodes to rapidly-varying regions, enhancing both simulation accuracy and computational efficiency. However, traditional approaches suffer from high computational complexity and geometric inflexibility, limiting their applicability, and existing supervised learning-based approaches face challenges in zero-shot generalization across diverse PDEs and mesh topologies.In this paper, we present an Unsupervised and Generalizable Mesh Movement Network (UGM2N). We first introduce unsupervised mesh adaptation through localized geometric feature learning, eliminating the dependency on pre-adapted meshes. We then develop a physics-constrained loss function, M-Uniform loss, that enforces mesh equidistribution at the nodal level.Experimental results demonstrate that the proposed network exhibits equation-agnostic generalization and geometric independence in efficient mesh adaptation. It demonstrates consistent superiority over existing methods, including robust performance across diverse PDEs and mesh geometries, scalability to multi-scale resolutions and guaranteed error reduction without mesh tangling.
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
Apr 08, 2025



While large language models (LLMs) have demonstrated exceptional capabilities in challenging tasks such as mathematical reasoning, existing methods to enhance reasoning ability predominantly rely on supervised fine-tuning (SFT) followed by reinforcement learning (RL) on reasoning-specific data after pre-training. However, these approaches critically depend on external supervisions--such as human labelled reasoning traces, verified golden answers, or pre-trained reward models--which limits scalability and practical applicability. In this work, we propose Entropy Minimized Policy Optimization (EMPO), which makes an early attempt at fully unsupervised LLM reasoning incentivization. EMPO does not require any supervised information for incentivizing reasoning capabilities (i.e., neither verifiable reasoning traces, problems with golden answers, nor additional pre-trained reward models). By continuously minimizing the predictive entropy of LLMs on unlabeled user queries in a latent semantic space, EMPO enables purely self-supervised evolution of reasoning capabilities with strong flexibility and practicality. Our experiments demonstrate competitive performance of EMPO on both mathematical reasoning and free-form commonsense reasoning tasks. Specifically, without any supervised signals, EMPO boosts the accuracy of Qwen2.5-Math-7B Base from 30.7\% to 48.1\% on mathematical benchmarks and improves truthfulness accuracy of Qwen2.5-7B Instruct from 87.16\% to 97.25\% on TruthfulQA.
Educator Attention: How computational tools can systematically identify the distribution of a key resource for students
Feb 27, 2025



Educator attention is critical for student success, yet how educators distribute their attention across students remains poorly understood due to data and methodological constraints. This study presents the first large-scale computational analysis of educator attention patterns, leveraging over 1 million educator utterances from virtual group tutoring sessions linked to detailed student demographic and academic achievement data. Using natural language processing techniques, we systematically examine the recipient and nature of educator attention. Our findings reveal that educators often provide more attention to lower-achieving students. However, disparities emerge across demographic lines, particularly by gender. Girls tend to receive less attention when paired with boys, even when they are the lower achieving student in the group. Lower-achieving female students in mixed-gender pairs receive significantly less attention than their higher-achieving male peers, while lower-achieving male students receive significantly and substantially more attention than their higher-achieving female peers. We also find some differences by race and English learner (EL) status, with low-achieving Black students receiving additional attention only when paired with another Black student but not when paired with a non-Black peer. In contrast, higher-achieving EL students receive disproportionately more attention than their lower-achieving EL peers. This work highlights how large-scale interaction data and computational methods can uncover subtle but meaningful disparities in teaching practices, providing empirical insights to inform more equitable and effective educational strategies.
The Best of Both Worlds: On the Dilemma of Out-of-distribution Detection
Oct 12, 2024Out-of-distribution (OOD) detection is essential for model trustworthiness which aims to sensitively identify semantic OOD samples and robustly generalize for covariate-shifted OOD samples. However, we discover that the superior OOD detection performance of state-of-the-art methods is achieved by secretly sacrificing the OOD generalization ability. Specifically, the classification accuracy of these models could deteriorate dramatically when they encounter even minor noise. This phenomenon contradicts the goal of model trustworthiness and severely restricts their applicability in real-world scenarios. What is the hidden reason behind such a limitation? In this work, we theoretically demystify the ``\textit{sensitive-robust}'' dilemma that lies in many existing OOD detection methods. Consequently, a theory-inspired algorithm is induced to overcome such a dilemma. By decoupling the uncertainty learning objective from a Bayesian perspective, the conflict between OOD detection and OOD generalization is naturally harmonized and a dual-optimal performance could be expected. Empirical studies show that our method achieves superior performance on standard benchmarks. To our best knowledge, this work is the first principled OOD detection method that achieves state-of-the-art OOD detection performance without compromising OOD generalization ability. Our code is available at \href{https://github.com/QingyangZhang/DUL}{https://github.com/QingyangZhang/DUL}.
COME: Test-time adaption by Conservatively Minimizing Entropy
Oct 12, 2024



Machine learning models must continuously self-adjust themselves for novel data distribution in the open world. As the predominant principle, entropy minimization (EM) has been proven to be a simple yet effective cornerstone in existing test-time adaption (TTA) methods. While unfortunately its fatal limitation (i.e., overconfidence) tends to result in model collapse. For this issue, we propose to Conservatively Minimize the Entropy (COME), which is a simple drop-in replacement of traditional EM to elegantly address the limitation. In essence, COME explicitly models the uncertainty by characterizing a Dirichlet prior distribution over model predictions during TTA. By doing so, COME naturally regularizes the model to favor conservative confidence on unreliable samples. Theoretically, we provide a preliminary analysis to reveal the ability of COME in enhancing the optimization stability by introducing a data-adaptive lower bound on the entropy. Empirically, our method achieves state-of-the-art performance on commonly used benchmarks, showing significant improvements in terms of classification accuracy and uncertainty estimation under various settings including standard, life-long and open-world TTA, i.e., up to $34.5\%$ improvement on accuracy and $15.1\%$ on false positive rate.
BURExtract-Llama: An LLM for Clinical Concept Extraction in Breast Ultrasound Reports
Aug 21, 2024



Breast ultrasound is essential for detecting and diagnosing abnormalities, with radiology reports summarizing key findings like lesion characteristics and malignancy assessments. Extracting this critical information is challenging due to the unstructured nature of these reports, with varied linguistic styles and inconsistent formatting. While proprietary LLMs like GPT-4 are effective, they are costly and raise privacy concerns when handling protected health information. This study presents a pipeline for developing an in-house LLM to extract clinical information from radiology reports. We first use GPT-4 to create a small labeled dataset, then fine-tune a Llama3-8B model on it. Evaluated on clinician-annotated reports, our model achieves an average F1 score of 84.6%, which is on par with GPT-4. Our findings demonstrate the feasibility of developing an in-house LLM that not only matches GPT-4's performance but also offers cost reductions and enhanced data privacy.