 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
ELITE: Embedding-Less retrieval with Iterative Text Exploration
May 17, 2025Large Language Models (LLMs) have achieved impressive progress in natural language processing, but their limited ability to retain long-term context constrains performance on document-level or multi-turn tasks. Retrieval-Augmented Generation (RAG) mitigates this by retrieving relevant information from an external corpus. However, existing RAG systems often rely on embedding-based retrieval trained on corpus-level semantic similarity, which can lead to retrieving content that is semantically similar in form but misaligned with the question's true intent. Furthermore, recent RAG variants construct graph- or hierarchy-based structures to improve retrieval accuracy, resulting in significant computation and storage overhead. In this paper, we propose an embedding-free retrieval framework. Our method leverages the logical inferencing ability of LLMs in retrieval using iterative search space refinement guided by our novel importance measure and extend our retrieval results with logically related information without explicit graph construction. Experiments on long-context QA benchmarks, including NovelQA and Marathon, show that our approach outperforms strong baselines while reducing storage and runtime by over an order of magnitude.
Data-driven Clustering in Ad-hoc Networks based on Community Detection
Aug 09, 2021
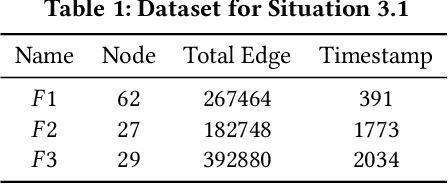
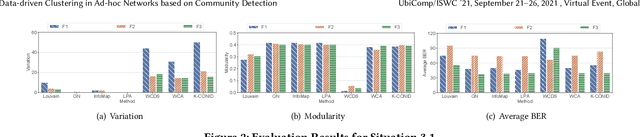

High demands for industrial networks lead to increasingly large sensor networks. However, the complexity of networks and demands for accurate data require better stability and communication quality. Conventional clustering methods for ad-hoc networks are based on topology and connectivity, leading to unstable clustering results and low communication quality. In this paper, we focus on two situations: time-evolving networks, and multi-channel ad-hoc networks. We model ad-hoc networks as graphs and introduce community detection methods to both situations. Particularly, in time-evolving networks, our method utilizes the results of community detection to ensure stability. By using similarity or human-in-the-loop measures, we construct a new weighted graph for final clustering. In multi-channel networks, we perform allocations from the results of multiplex community detection. Experiments on real-world datasets show that our method outperforms baselines in both stability and quality.