 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting-Aligned Fine-Tuning for Multilingual Downstream Tasks in Mixture-of-Experts Models
May 27, 2026Mixture-of-Experts (MoE) models have emerged as a dominant paradigm for efficient LLM scaling, yet adapting them to non-English downstream tasks remains challenging. Existing fine-tuning approaches treat MoE models as monolithic learners, ignoring the heterogeneous routing structure that develops during pretraining. We validate across multiple MoE models and downstream tasks that middle layers form a language-universal alignment zone where routing divergence strongly predicts per-language task performance gaps. Building on this observation, we propose RA-MoE (Routing-Aligned MoE Fine-Tuning), a three-stage framework that categorizes parallel task examples into a four-way taxonomy (cc/ci/ic/ii) based on correctness in English and the target language, identifies task-relevant experts in the middle layers, and augments standard SFT with a routing alignment loss that encourages target-language routing on ci-type examples to follow the English task-expert activation pattern. Experiments across three MoE models, three tasks, and six target languages demonstrate that RA-MoE consistently outperforms standard SFT and strong baselines including Routing Steering and RISE, with the ci proportion of a task-language pair serving as a reliable predictor of alignment benefit.
SeaEvo: Advancing Algorithm Discovery with Strategy Space Evolution
Apr 27, 2026LLM-guided evolutionary search has emerged as a promising paradigm for automated algorithm discovery, yet most systems track search progress primarily through executable programs and scalar fitness. Even when natural-language reflection is used, it is often used locally in mutation prompts or stored without an explicit population-level organization of strategic directions. As a result, evolutionary search can struggle to distinguish syntactically different implementations of the same idea, preserve lower-fitness but strategically promising directions, or detect when an entire family of strategies has saturated. We introduce \model, a modular strategy-space layer that elevates natural-language strategy descriptions from transient prompt context to first-class population-level evolutionary state in LLM-driven program search. \model augments each candidate program with an explicit natural language strategy description and uses this representation in three ways: Strategy Articulation turns mutation into a diagnose-direct-implement process; Stratified Experience Retrieval organizes the archive into strategy clusters and selects inspirations by behavioral complementarity; and Strategic Landscape Navigation periodically summarizes effective, saturated, and underexplored strategy families to guide future mutations. Across mathematical algorithm discovery, systems optimization, and agent-scaffold benchmarks, \model improves the underlying evolutionary backbones in most settings, with particularly large gains (21% relative improvement) on open-ended system optimization tasks. These results suggest that persistent strategy representations provide a practical mechanism for improving the robustness and efficiency of LLM-guided evolutionary search, suggesting a path toward compound AI systems that accumulate algorithmic knowledge over time.
FORGE:Fine-grained Multimodal Evaluation for Manufacturing Scenarios
Apr 08, 2026The manufacturing sector is increasingly adopting Multimodal Large Language Models (MLLMs) to transition from simple perception to autonomous execution, yet current evaluations fail to reflect the rigorous demands of real-world manufacturing environments. Progress is hindered by data scarcity and a lack of fine-grained domain semantics in existing datasets. To bridge this gap, we introduce FORGE. Wefirst construct a high-quality multimodal dataset that combines real-world 2D images and 3D point clouds, annotated with fine-grained domain semantics (e.g., exact model numbers). We then evaluate 18 state-of-the-art MLLMs across three manufacturing tasks, namely workpiece verification, structural surface inspection, and assembly verification, revealing significant performance gaps. Counter to conventional understanding, the bottleneck analysis shows that visual grounding is not the primary limiting factor. Instead, insufficient domain-specific knowledge is the key bottleneck, setting a clear direction for future research. Beyond evaluation, we show that our structured annotations can serve as an actionable training resource: supervised fine-tuning of a compact 3B-parameter model on our data yields up to 90.8% relative improvement in accuracy on held-out manufacturing scenarios, providing preliminary evidence for a practical pathway toward domain-adapted manufacturing MLLMs. The code and datasets are available at https://ai4manufacturing.github.io/forge-web.
DR-LoRA: Dynamic Rank LoRA for Mixture-of-Experts Adaptation
Jan 08, 2026Mixture-of-Experts (MoE) has become a prominent paradigm for scaling Large Language Models (LLMs). Parameter-efficient fine-tuning (PEFT), such as LoRA, is widely adopted to adapt pretrained MoE LLMs to downstream tasks. However, existing approaches assign identical LoRA ranks to all experts, overlooking the intrinsic functional specialization within MoE LLMs. This uniform allocation leads to resource mismatch, task-relevant experts are under-provisioned while less relevant ones receive redundant parameters. We propose a Dynamic Rank LoRA framework named DR-LoRA, which dynamically grows expert LoRA ranks during fine-tuning based on task-specific demands. DR-LoRA employs an Expert Saliency Scoring mechanism that integrates expert routing frequency and LoRA rank importance to quantify each expert's demand for additional capacity. Experts with higher saliency scores are prioritized for rank expansion, enabling the automatic formation of a heterogeneous rank distribution tailored to the target task. Experiments on multiple benchmarks demonstrate that DR-LoRA consistently outperforms standard LoRA and static allocation strategies under the same parameter budget, achieving superior task performance with more efficient parameter utilization.
REMA: A Unified Reasoning Manifold Framework for Interpreting Large Language Model
Sep 26, 2025Understanding how Large Language Models (LLMs) perform complex reasoning and their failure mechanisms is a challenge in interpretability research. To provide a measurable geometric analysis perspective, we define the concept of the Reasoning Manifold, a latent low-dimensional geometric structure formed by the internal representations corresponding to all correctly reasoned generations. This structure can be conceptualized as the embodiment of the effective thinking paths that the model has learned to successfully solve a given task. Based on this concept, we build REMA, a framework that explains the origins of failures by quantitatively comparing the spatial relationships of internal model representations corresponding to both erroneous and correct reasoning samples. Specifically, REMA first quantifies the geometric deviation of each erroneous representation by calculating its k-nearest neighbors distance to the approximated manifold formed by correct representations, thereby providing a unified failure signal. It then localizes the divergence points where these deviations first become significant by tracking this deviation metric across the model's layers and comparing it against a baseline of internal fluctuations from correct representations, thus identifying where the reasoning chain begins to go off-track. Our extensive experiments on diverse language and multimodal models and tasks demonstrate the low-dimensional nature of the reasoning manifold and the high separability between erroneous and correct reasoning representations. The results also validate the effectiveness of the REMA framework in analyzing the origins of reasoning failures. This research connects abstract reasoning failures to measurable geometric deviations in representations, providing new avenues for in-depth understanding and diagnosis of the internal computational processes of black-box models.
KLIPA: A Knowledge Graph and LLM-Driven QA Framework for IP Analysis
Sep 09, 2025



Effectively managing intellectual property is a significant challenge. Traditional methods for patent analysis depend on labor-intensive manual searches and rigid keyword matching. These approaches are often inefficient and struggle to reveal the complex relationships hidden within large patent datasets, hindering strategic decision-making. To overcome these limitations, we introduce KLIPA, a novel framework that leverages a knowledge graph and a large language model (LLM) to significantly advance patent analysis. Our approach integrates three key components: a structured knowledge graph to map explicit relationships between patents, a retrieval-augmented generation(RAG) system to uncover contextual connections, and an intelligent agent that dynamically determines the optimal strategy for resolving user queries. We validated KLIPA on a comprehensive, real-world patent database, where it demonstrated substantial improvements in knowledge extraction, discovery of novel connections, and overall operational efficiency. This combination of technologies enhances retrieval accuracy, reduces reliance on domain experts, and provides a scalable, automated solution for any organization managing intellectual property, including technology corporations and legal firms, allowing them to better navigate the complexities of strategic innovation and competitive intelligence.
Reasoning Meets Personalization: Unleashing the Potential of Large Reasoning Model for Personalized Generation
May 23, 2025Personalization is a critical task in modern intelligent systems, with applications spanning diverse domains, including interactions with large language models (LLMs). Recent advances in reasoning capabilities have significantly enhanced LLMs, enabling unprecedented performance in tasks such as mathematics and coding. However, their potential for personalization tasks remains underexplored. In this paper, we present the first systematic evaluation of large reasoning models (LRMs) for personalization tasks. Surprisingly, despite generating more tokens, LRMs do not consistently outperform general-purpose LLMs, especially in retrieval-intensive scenarios where their advantages diminish. Our analysis identifies three key limitations: divergent thinking, misalignment of response formats, and ineffective use of retrieved information. To address these challenges, we propose Reinforced Reasoning for Personalization (\model), a novel framework that incorporates a hierarchical reasoning thought template to guide LRMs in generating structured outputs. Additionally, we introduce a reasoning process intervention method to enforce adherence to designed reasoning patterns, enhancing alignment. We also propose a cross-referencing mechanism to ensure consistency. Extensive experiments demonstrate that our approach significantly outperforms existing techniques.
Privacy in LLM-based Recommendation: Recent Advances and Future Directions
Jun 03, 2024Nowadays, large language models (LLMs) have been integrated with conventional recommendation models to improve recommendation performance. However, while most of the existing works have focused on improving the model performance, the privacy issue has only received comparatively less attention. In this paper, we review recent advancements in privacy within LLM-based recommendation, categorizing them into privacy attacks and protection mechanisms. Additionally, we highlight several challenges and propose future directions for the community to address these critical problems.
Can LLM Substitute Human Labeling? A Case Study of Fine-grained Chinese Address Entity Recognition Dataset for UAV Delivery
Mar 19, 2024



We present CNER-UAV, a fine-grained \textbf{C}hinese \textbf{N}ame \textbf{E}ntity \textbf{R}ecognition dataset specifically designed for the task of address resolution in \textbf{U}nmanned \textbf{A}erial \textbf{V}ehicle delivery systems. The dataset encompasses a diverse range of five categories, enabling comprehensive training and evaluation of NER models. To construct this dataset, we sourced the data from a real-world UAV delivery system and conducted a rigorous data cleaning and desensitization process to ensure privacy and data integrity. The resulting dataset, consisting of around 12,000 annotated samples, underwent human experts and \textbf{L}arge \textbf{L}anguage \textbf{M}odel annotation. We evaluated classical NER models on our dataset and provided in-depth analysis. The dataset and models are publicly available at \url{https://github.com/zhhvvv/CNER-UAV}.
Evaluator for Emotionally Consistent Chatbots
Dec 02, 2021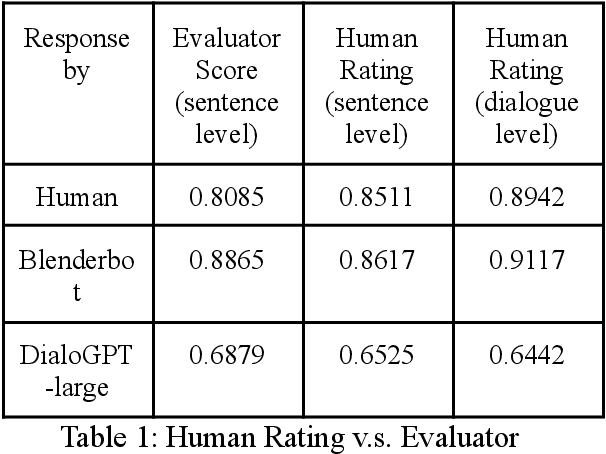
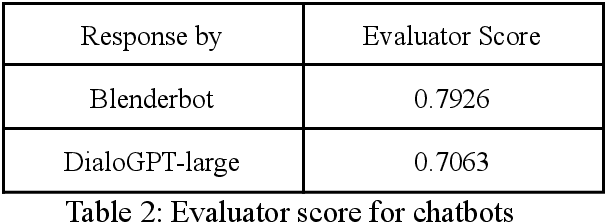

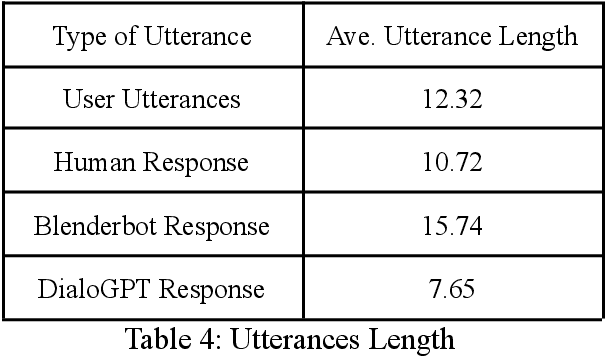
One challenge for evaluating current sequence- or dialogue-level chatbots, such as Empathetic Open-domain Conversation Models, is to determine whether the chatbot performs in an emotionally consistent way. The most recent work only evaluates on the aspects of context coherence, language fluency, response diversity, or logical self-consistency between dialogues. This work proposes training an evaluator to determine the emotional consistency of chatbots.