 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Transformer Networks for Semantic Image Segmentation
Jun 08, 2021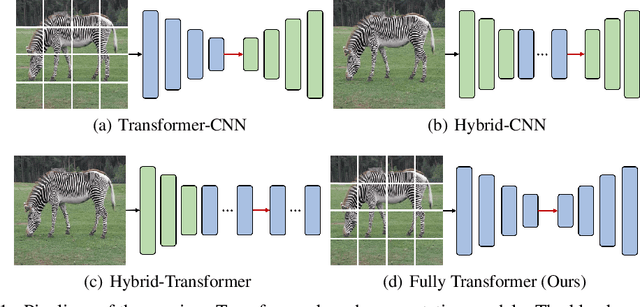
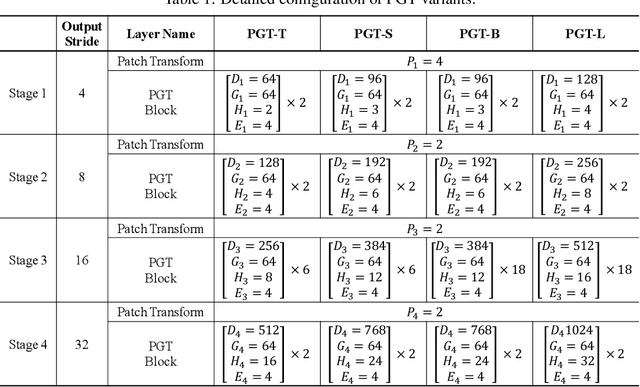
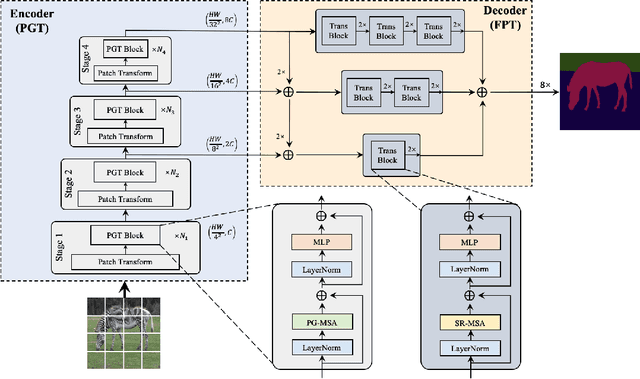
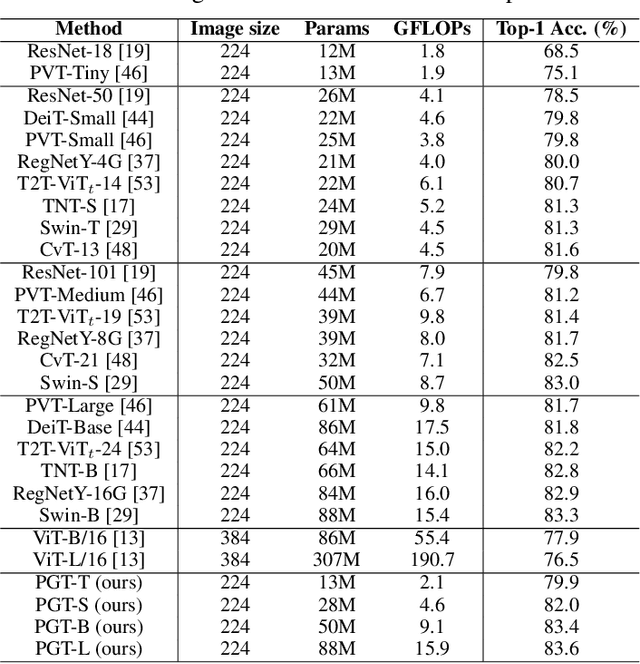
Transformers have shown impressive performance in various natural language processing and computer vision tasks, due to the capability of modeling long-range dependencies. Recent progress has demonstrated to combine such transformers with CNN-based semantic image segmentation models is very promising. However, it is not well studied yet on how well a pure transformer based approach can achieve for image segmentation. In this work, we explore a novel framework for semantic image segmentation, which is encoder-decoder based Fully Transformer Networks (FTN). Specifically, we first propose a Pyramid Group Transformer (PGT) as the encoder for progressively learning hierarchical features, while reducing the computation complexity of the standard visual transformer(ViT). Then, we propose a Feature Pyramid Transformer (FPT) to fuse semantic-level and spatial-level information from multiple levels of the PGT encoder for semantic image segmentation. Surprisingly, this simple baseline can achieve new state-of-the-art results on multiple challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K and COCO-Stuff. The source code will be released upon the publication of this work.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
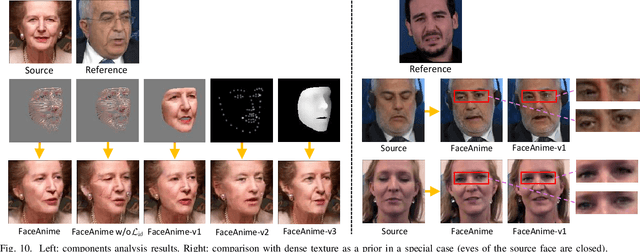
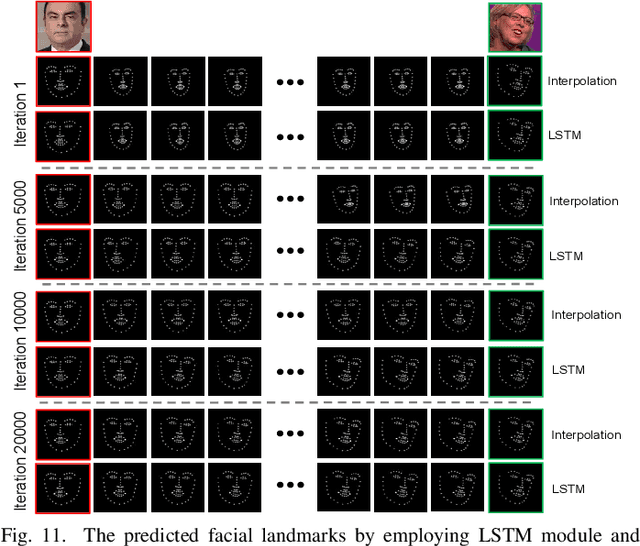
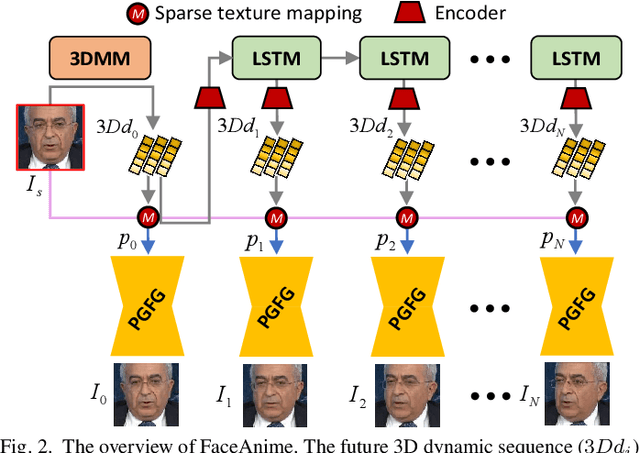
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
Joint Face Image Restoration and Frontalization for Recognition
May 12, 2021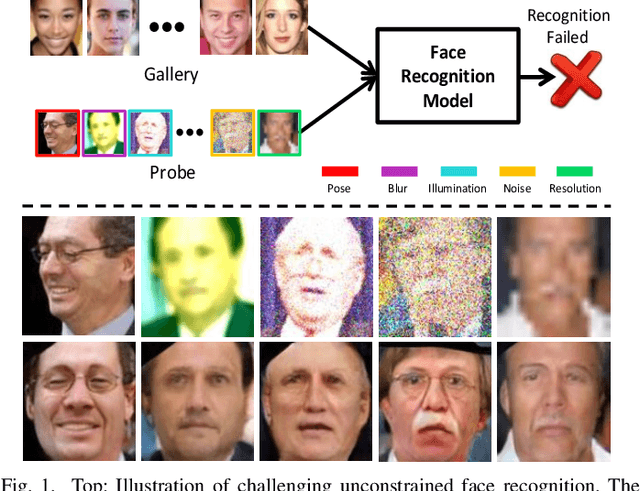
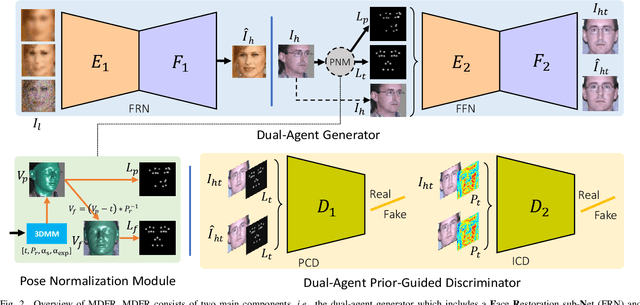
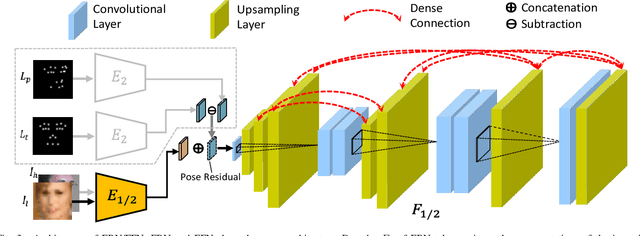
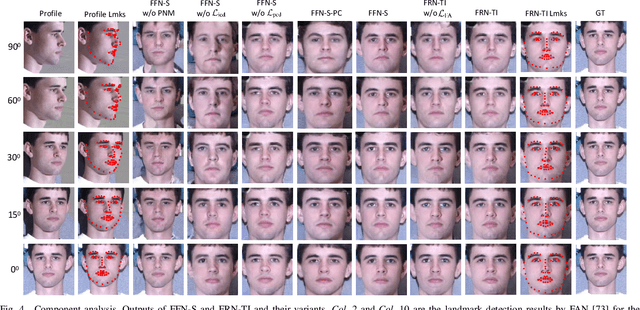
In real-world scenarios, many factors may harm face recognition performance, e.g., large pose, bad illumination,low resolution, blur and noise. To address these challenges, previous efforts usually first restore the low-quality faces to high-quality ones and then perform face recognition. However, most of these methods are stage-wise, which is sub-optimal and deviates from the reality. In this paper, we address all these challenges jointly for unconstrained face recognition. We propose an Multi-Degradation Face Restoration (MDFR) model to restore frontalized high-quality faces from the given low-quality ones under arbitrary facial poses, with three distinct novelties. First, MDFR is a well-designed encoder-decoder architecture which extracts feature representation from an input face image with arbitrary low-quality factors and restores it to a high-quality counterpart. Second, MDFR introduces a pose residual learning strategy along with a 3D-based Pose Normalization Module (PNM), which can perceive the pose gap between the input initial pose and its real-frontal pose to guide the face frontalization. Finally, MDFR can generate frontalized high-quality face images by a single unified network, showing a strong capability of preserving face identity. Qualitative and quantitative experiments on both controlled and in-the-wild benchmarks demonstrate the superiority of MDFR over state-of-the-art methods on both face frontalization and face restoration.
Contrastive Context-Aware Learning for 3D High-Fidelity Mask Face Presentation Attack Detection
Apr 13, 2021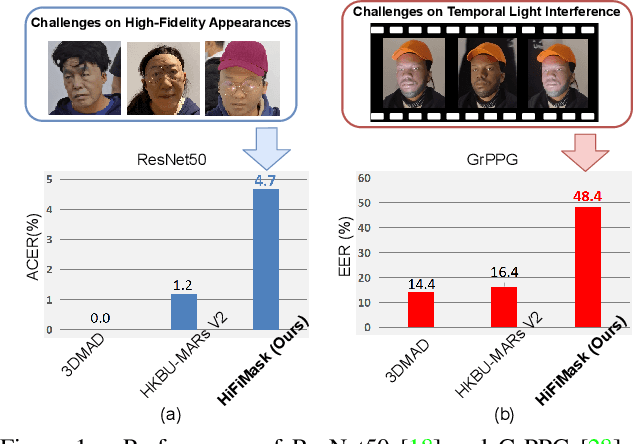
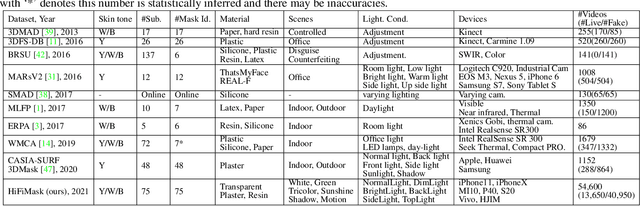

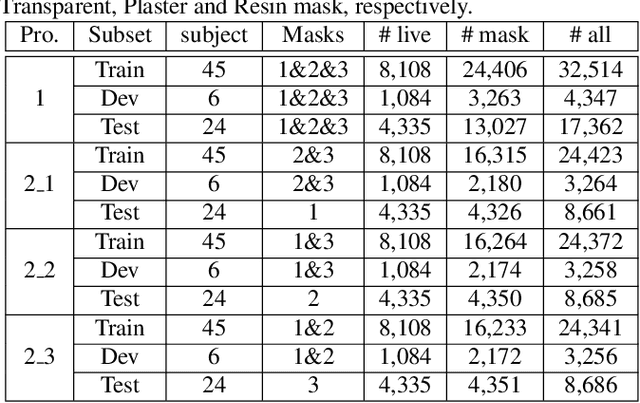
Face presentation attack detection (PAD) is essential to secure face recognition systems primarily from high-fidelity mask attacks. Most existing 3D mask PAD benchmarks suffer from several drawbacks: 1) a limited number of mask identities, types of sensors, and a total number of videos; 2) low-fidelity quality of facial masks. Basic deep models and remote photoplethysmography (rPPG) methods achieved acceptable performance on these benchmarks but still far from the needs of practical scenarios. To bridge the gap to real-world applications, we introduce a largescale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask). Specifically, a total amount of 54,600 videos are recorded from 75 subjects with 225 realistic masks by 7 new kinds of sensors. Together with the dataset, we propose a novel Contrastive Context-aware Learning framework, namely CCL. CCL is a new training methodology for supervised PAD tasks, which is able to learn by leveraging rich contexts accurately (e.g., subjects, mask material and lighting) among pairs of live faces and high-fidelity mask attacks. Extensive experimental evaluations on HiFiMask and three additional 3D mask datasets demonstrate the effectiveness of our method.
Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection
Mar 30, 2021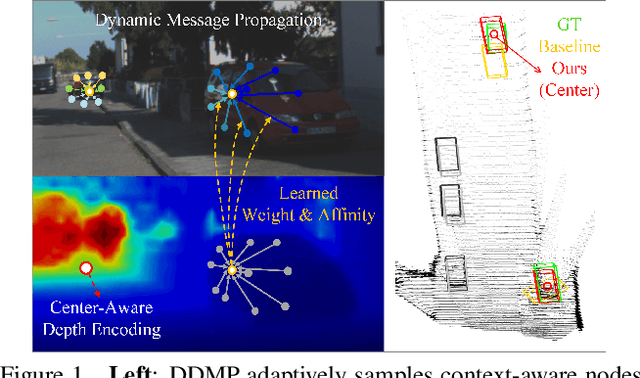
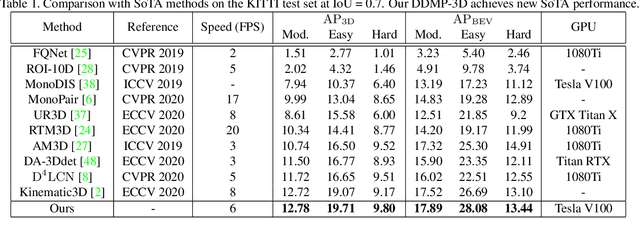
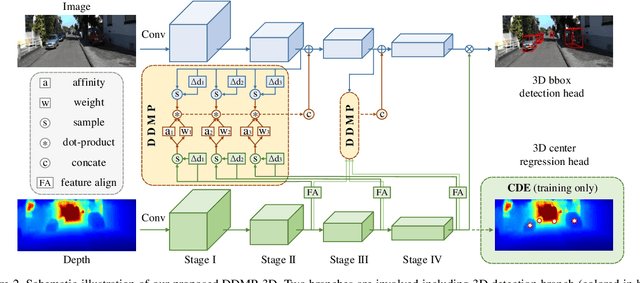
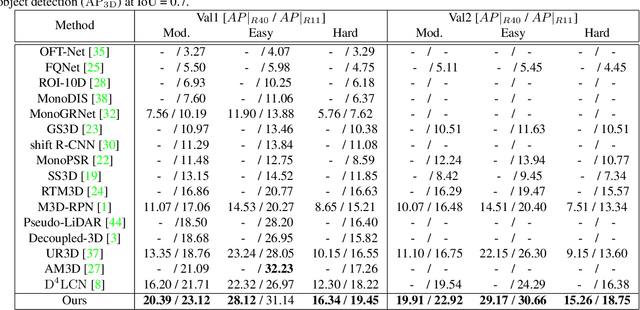
The objective of this paper is to learn context- and depth-aware feature representation to solve the problem of monocular 3D object detection. We make following contributions: (i) rather than appealing to the complicated pseudo-LiDAR based approach, we propose a depth-conditioned dynamic message propagation (DDMP) network to effectively integrate the multi-scale depth information with the image context;(ii) this is achieved by first adaptively sampling context-aware nodes in the image context and then dynamically predicting hybrid depth-dependent filter weights and affinity matrices for propagating information; (iii) by augmenting a center-aware depth encoding (CDE) task, our method successfully alleviates the inaccurate depth prior; (iv) we thoroughly demonstrate the effectiveness of our proposed approach and show state-of-the-art results among the monocular-based approaches on the KITTI benchmark dataset. Particularly, we rank $1^{st}$ in the highly competitive KITTI monocular 3D object detection track on the submission day (November 16th, 2020). Code and models are released at \url{https://github.com/fudan-zvg/DDMP}
Anti-UAV: A Large Multi-Modal Benchmark for UAV Tracking
Feb 08, 2021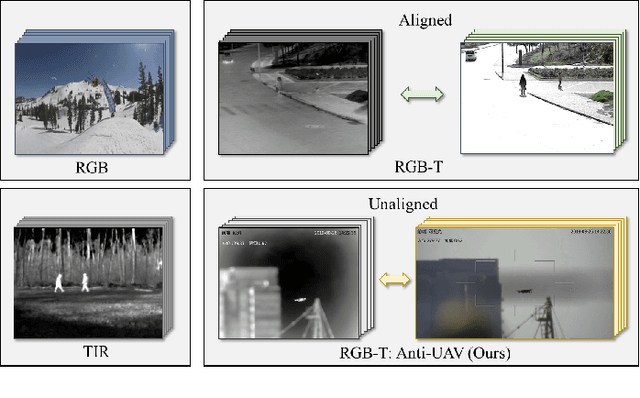

Unmanned Aerial Vehicle (UAV) offers lots of applications in both commerce and recreation. With this, monitoring the operation status of UAVs is crucially important. In this work, we consider the task of tracking UAVs, providing rich information such as location and trajectory. To facilitate research on this topic, we propose a dataset, Anti-UAV, with more than 300 video pairs containing over 580k manually annotated bounding boxes. The releasing of such a large-scale dataset could be a useful initial step in research of tracking UAVs. Furthermore, the advancement of addressing research challenges in Anti-UAV can help the design of anti-UAV systems, leading to better surveillance of UAVs. Besides, a novel approach named dual-flow semantic consistency (DFSC) is proposed for UAV tracking. Modulated by the semantic flow across video sequences, the tracker learns more robust class-level semantic information and obtains more discriminative instance-level features. Experimental results demonstrate that Anti-UAV is very challenging, and the proposed method can effectively improve the tracker's performance. The Anti-UAV benchmark and the code of the proposed approach will be publicly available at https://github.com/ucas-vg/Anti-UAV.
GINet: Graph Interaction Network for Scene Parsing
Sep 14, 2020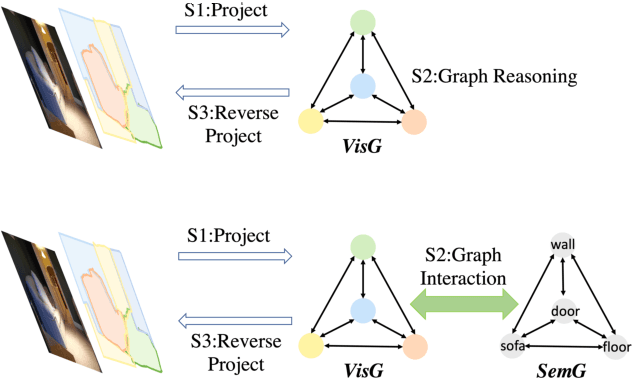
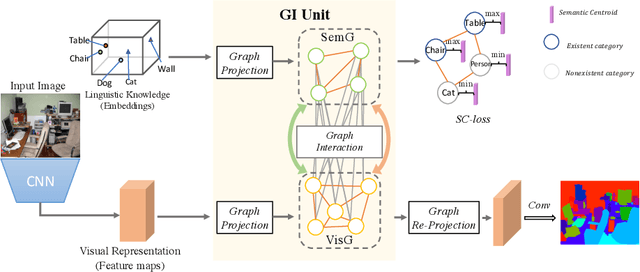

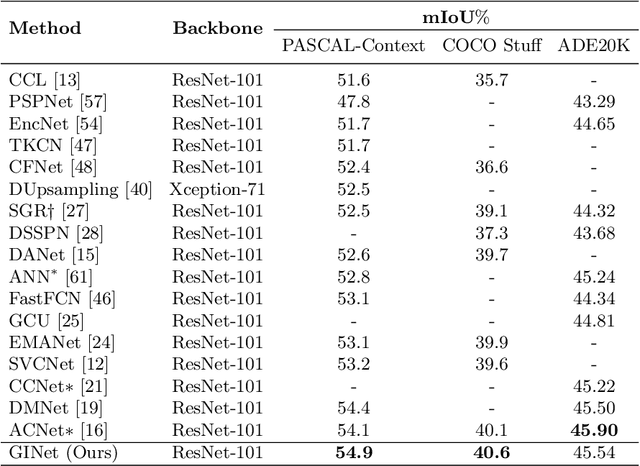
Recently, context reasoning using image regions beyond local convolution has shown great potential for scene parsing. In this work, we explore how to incorporate the linguistic knowledge to promote context reasoning over image regions by proposing a Graph Interaction unit (GI unit) and a Semantic Context Loss (SC-loss). The GI unit is capable of enhancing feature representations of convolution networks over high-level semantics and learning the semantic coherency adaptively to each sample. Specifically, the dataset-based linguistic knowledge is first incorporated in the GI unit to promote context reasoning over the visual graph, then the evolved representations of the visual graph are mapped to each local representation to enhance the discriminated capability for scene parsing. GI unit is further improved by the SC-loss to enhance the semantic representations over the exemplar-based semantic graph. We perform full ablation studies to demonstrate the effectiveness of each component in our approach. Particularly, the proposed GINet outperforms the state-of-the-art approaches on the popular benchmarks, including Pascal-Context and COCO Stuff.
Binarized Neural Architecture Search for Efficient Object Recognition
Sep 08, 2020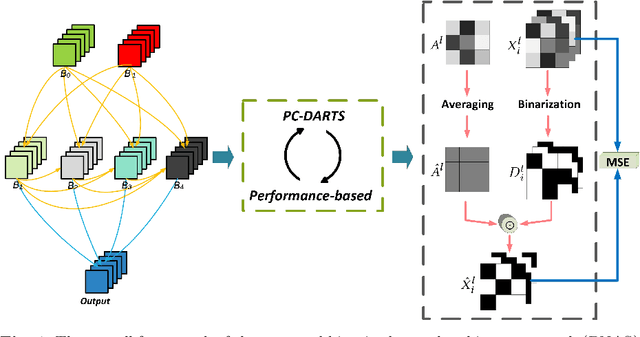

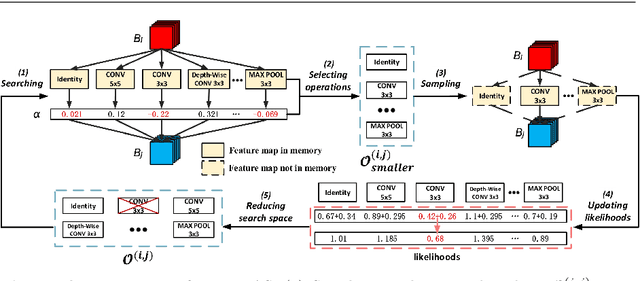
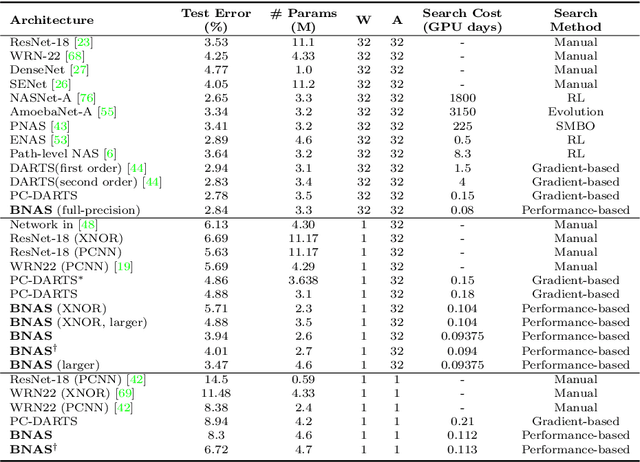
Traditional neural architecture search (NAS) has a significant impact in computer vision by automatically designing network architectures for various tasks. In this paper, binarized neural architecture search (BNAS), with a search space of binarized convolutions, is introduced to produce extremely compressed models to reduce huge computational cost on embedded devices for edge computing. The BNAS calculation is more challenging than NAS due to the learning inefficiency caused by optimization requirements and the huge architecture space, and the performance loss when handling the wild data in various computing applications. To address these issues, we introduce operation space reduction and channel sampling into BNAS to significantly reduce the cost of searching. This is accomplished through a performance-based strategy that is robust to wild data, which is further used to abandon less potential operations. Furthermore, we introduce the Upper Confidence Bound (UCB) to solve 1-bit BNAS. Two optimization methods for binarized neural networks are used to validate the effectiveness of our BNAS. Extensive experiments demonstrate that the proposed BNAS achieves a comparable performance to NAS on both CIFAR and ImageNet databases. An accuracy of $96.53\%$ vs. $97.22\%$ is achieved on the CIFAR-10 dataset, but with a significantly compressed model, and a $40\%$ faster search than the state-of-the-art PC-DARTS. On the wild face recognition task, our binarized models achieve a performance similar to their corresponding full-precision models.
iffDetector: Inference-aware Feature Filtering for Object Detection
Jun 23, 2020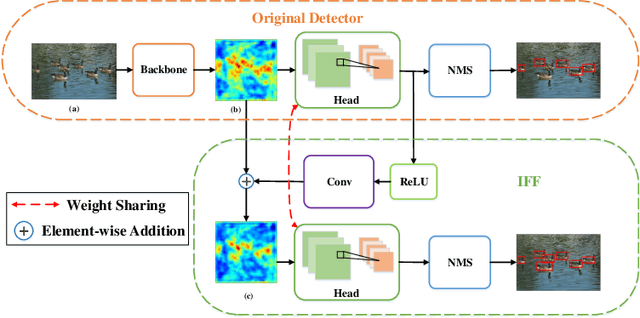

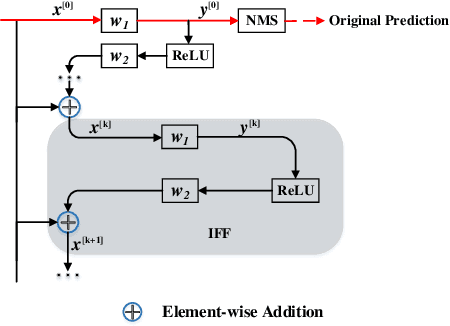
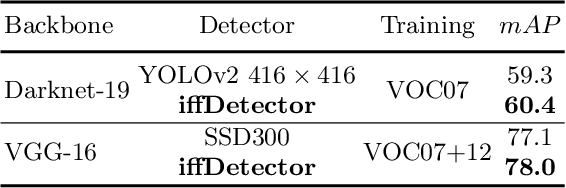
Modern CNN-based object detectors focus on feature configuration during training but often ignore feature optimization during inference. In this paper, we propose a new feature optimization approach to enhance features and suppress background noise in both the training and inference stages. We introduce a generic Inference-aware Feature Filtering (IFF) module that can easily be combined with modern detectors, resulting in our iffDetector. Unlike conventional open-loop feature calculation approaches without feedback, the IFF module performs closed-loop optimization by leveraging high-level semantics to enhance the convolutional features. By applying Fourier transform analysis, we demonstrate that the IFF module acts as a negative feedback that theoretically guarantees the stability of feature learning. IFF can be fused with CNN-based object detectors in a plug-and-play manner with negligible computational cost overhead. Experiments on the PASCAL VOC and MS COCO datasets demonstrate that our iffDetector consistently outperforms state-of-the-art methods by significant margins\footnote{The test code and model are anonymously available in https://github.com/anonymous2020new/iffDetector }.
Self-supervised Video Object Segmentation
Jun 22, 2020
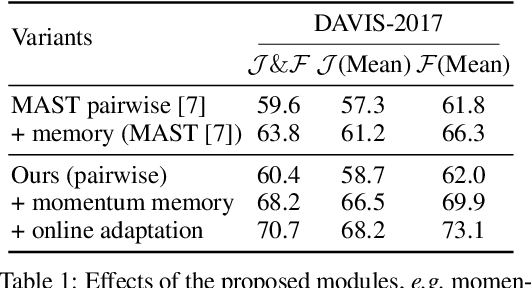
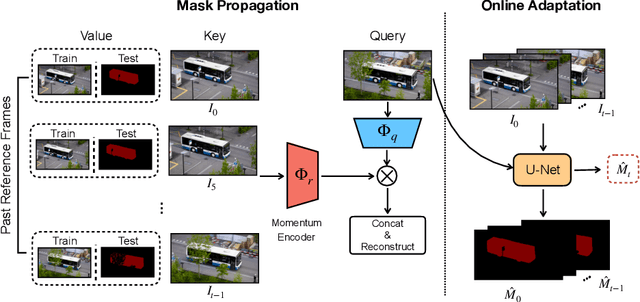

The objective of this paper is self-supervised representation learning, with the goal of solving semi-supervised video object segmentation (a.k.a. dense tracking). We make the following contributions: (i) we propose to improve the existing self-supervised approach, with a simple, yet more effective memory mechanism for long-term correspondence matching, which resolves the challenge caused by the dis-appearance and reappearance of objects; (ii) by augmenting the self-supervised approach with an online adaptation module, our method successfully alleviates tracker drifts caused by spatial-temporal discontinuity, e.g. occlusions or dis-occlusions, fast motions; (iii) we explore the efficiency of self-supervised representation learning for dense tracking, surprisingly, we show that a powerful tracking model can be trained with as few as 100 raw video clips (equivalent to a duration of 11mins), indicating that low-level statistics have already been effective for tracking tasks; (iv) we demonstrate state-of-the-art results among the self-supervised approaches on DAVIS-2017 and YouTube-VOS, as well as surpassing most of methods trained with millions of manual segmentation annotations, further bridging the gap between self-supervised and supervised learning. Codes are released to foster any further research (https://github.com/fangruizhu/self_sup_semiVOS).