 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Proximal Federated Learning for Non-Convex Composite Optimization on Heterogeneous Data
Mar 08, 2026Federated Composite Optimization (FCO) has emerged as a promising framework for training models with structural constraints (e.g., sparsity) in distributed edge networks. However, simultaneously achieving communication efficiency and convergence robustness remains a significant challenge, particularly when dealing with non-smooth regularizers, statistical heterogeneity, and the restrictions of biased compression. To address these issues, we propose FedCEF (Federated Composite Error Feedback), a novel algorithm tailored for non-convex FCO. FedCEF introduces a decoupled proximal update scheme that separates the proximal operator from communication, enabling clients to handle non-smooth terms locally while transmitting compressed information. To mitigate the noise from aggressive quantization and the bias from non-IID data, FedCEF integrates a rigorous error feedback mechanism with control variates. Furthermore, we design a communication-efficient pre-proximal downlink strategy that allows clients to exactly reconstruct global control variables without explicit transmission. We theoretically establish that FedCEF achieves sublinear convergence to a bounded residual error under general non-convexity, which is controllable via the step size and batch size. Extensive experiments on real datasets validate FedCEF maintains competitive model accuracy even under extreme compression ratios (e.g., 1%), significantly reducing the total communication volume compared to uncompressed baselines.
WildGHand: Learning Anti-Perturbation Gaussian Hand Avatars from Monocular In-the-Wild Videos
Feb 24, 2026Despite recent progress in 3D hand reconstruction from monocular videos, most existing methods rely on data captured in well-controlled environments and therefore degrade in real-world settings with severe perturbations, such as hand-object interactions, extreme poses, illumination changes, and motion blur. To tackle these issues, we introduce WildGHand, an optimization-based framework that enables self-adaptive 3D Gaussian splatting on in-the-wild videos and produces high-fidelity hand avatars. WildGHand incorporates two key components: (i) a dynamic perturbation disentanglement module that explicitly represents perturbations as time-varying biases on 3D Gaussian attributes during optimization, and (ii) a perturbation-aware optimization strategy that generates per-frame anisotropic weighted masks to guide optimization. Together, these components allow the framework to identify and suppress perturbations across both spatial and temporal dimensions. We further curate a dataset of monocular hand videos captured under diverse perturbations to benchmark in-the-wild hand avatar reconstruction. Extensive experiments on this dataset and two public datasets demonstrate that WildGHand achieves state-of-the-art performance and substantially improves over its base model across multiple metrics (e.g., up to a $15.8\%$ relative gain in PSNR and a $23.1\%$ relative reduction in LPIPS). Our implementation and dataset are available at https://github.com/XuanHuang0/WildGHand.
Efficient Personalized Federated PCA with Manifold Optimization for IoT Anomaly Detection
Feb 13, 2026Internet of things (IoT) networks face increasing security threats due to their distributed nature and resource constraints. Although federated learning (FL) has gained prominence as a privacy-preserving framework for distributed IoT environments, current federated principal component analysis (PCA) methods lack the integration of personalization and robustness, which are critical for effective anomaly detection. To address these limitations, we propose an efficient personalized federated PCA (FedEP) method for anomaly detection in IoT networks. The proposed model achieves personalization through introducing local representations with the $\ell_1$-norm for element-wise sparsity, while maintaining robustness via enforcing local models with the $\ell_{2,1}$-norm for row-wise sparsity. To solve this non-convex problem, we develop a manifold optimization algorithm based on the alternating direction method of multipliers (ADMM) with rigorous theoretical convergence guarantees. Experimental results confirm that the proposed FedEP outperforms the state-of-the-art FedPG, achieving excellent F1-scores and accuracy in various IoT security scenarios. Our code will be available at \href{https://github.com/xianchaoxiu/FedEP}{https://github.com/xianchaoxiu/FedEP}.
SOFTooth: Semantics-Enhanced Order-Aware Fusion for Tooth Instance Segmentation
Dec 29, 2025Three-dimensional (3D) tooth instance segmentation remains challenging due to crowded arches, ambiguous tooth-gingiva boundaries, missing teeth, and rare yet clinically important third molars. Native 3D methods relying on geometric cues often suffer from boundary leakage, center drift, and inconsistent tooth identities, especially for minority classes and complex anatomies. Meanwhile, 2D foundation models such as the Segment Anything Model (SAM) provide strong boundary-aware semantics, but directly applying them in 3D is impractical in clinical workflows. To address these issues, we propose SOFTooth, a semantics-enhanced, order-aware 2D-3D fusion framework that leverages frozen 2D semantics without explicit 2D mask supervision. First, a point-wise residual gating module injects occlusal-view SAM embeddings into 3D point features to refine tooth-gingiva and inter-tooth boundaries. Second, a center-guided mask refinement regularizes consistency between instance masks and geometric centroids, reducing center drift. Furthermore, an order-aware Hungarian matching strategy integrates anatomical tooth order and center distance into similarity-based assignment, ensuring coherent labeling even under missing or crowded dentitions. On 3DTeethSeg'22, SOFTooth achieves state-of-the-art overall accuracy and mean IoU, with clear gains on cases involving third molars, demonstrating that rich 2D semantics can be effectively transferred to 3D tooth instance segmentation without 2D fine-tuning.
Lightweight Deep Unfolding Networks with Enhanced Robustness for Infrared Small Target Detection
Sep 10, 2025Infrared small target detection (ISTD) is one of the key techniques in image processing. Although deep unfolding networks (DUNs) have demonstrated promising performance in ISTD due to their model interpretability and data adaptability, existing methods still face significant challenges in parameter lightweightness and noise robustness. In this regard, we propose a highly lightweight framework based on robust principal component analysis (RPCA) called L-RPCANet. Technically, a hierarchical bottleneck structure is constructed to reduce and increase the channel dimension in the single-channel input infrared image to achieve channel-wise feature refinement, with bottleneck layers designed in each module to extract features. This reduces the number of channels in feature extraction and improves the lightweightness of network parameters. Furthermore, a noise reduction module is embedded to enhance the robustness against complex noise. In addition, squeeze-and-excitation networks (SENets) are leveraged as a channel attention mechanism to focus on the varying importance of different features across channels, thereby achieving excellent performance while maintaining both lightweightness and robustness. Extensive experiments on the ISTD datasets validate the superiority of our proposed method compared with state-of-the-art methods covering RPCANet, DRPCANet, and RPCANet++. The code will be available at https://github.com/xianchaoxiu/L-RPCANet.
Transformer-Guided Content-Adaptive Graph Learning for Hyperspectral Unmixing
Sep 03, 2025



Hyperspectral unmixing (HU) targets to decompose each mixed pixel in remote sensing images into a set of endmembers and their corresponding abundances. Despite significant progress in this field using deep learning, most methods fail to simultaneously characterize global dependencies and local consistency, making it difficult to preserve both long-range interactions and boundary details. This letter proposes a novel transformer-guided content-adaptive graph unmixing framework (T-CAGU), which overcomes these challenges by employing a transformer to capture global dependencies and introducing a content-adaptive graph neural network to enhance local relationships. Unlike previous work, T-CAGU integrates multiple propagation orders to dynamically learn the graph structure, ensuring robustness against noise. Furthermore, T-CAGU leverages a graph residual mechanism to preserve global information and stabilize training. Experimental results demonstrate its superiority over the state-of-the-art methods. Our code is available at https://github.com/xianchaoxiu/T-CAGU.
STAR-Net: An Interpretable Model-Aided Network for Remote Sensing Image Denoising
May 30, 2025Remote sensing image (RSI) denoising is an important topic in the field of remote sensing. Despite the impressive denoising performance of RSI denoising methods, most current deep learning-based approaches function as black boxes and lack integration with physical information models, leading to limited interpretability. Additionally, many methods may struggle with insufficient attention to non-local self-similarity in RSI and require tedious tuning of regularization parameters to achieve optimal performance, particularly in conventional iterative optimization approaches. In this paper, we first propose a novel RSI denoising method named sparse tensor-aided representation network (STAR-Net), which leverages a low-rank prior to effectively capture the non-local self-similarity within RSI. Furthermore, we extend STAR-Net to a sparse variant called STAR-Net-S to deal with the interference caused by non-Gaussian noise in original RSI for the purpose of improving robustness. Different from conventional iterative optimization, we develop an alternating direction method of multipliers (ADMM)-guided deep unrolling network, in which all regularization parameters can be automatically learned, thus inheriting the advantages of both model-based and deep learning-based approaches and successfully addressing the above-mentioned shortcomings. Comprehensive experiments on synthetic and real-world datasets demonstrate that STAR-Net and STAR-Net-S outperform state-of-the-art RSI denoising methods.
Bi-Level Unsupervised Feature Selection
May 26, 2025Unsupervised feature selection (UFS) is an important task in data engineering. However, most UFS methods construct models from a single perspective and often fail to simultaneously evaluate feature importance and preserve their inherent data structure, thus limiting their performance. To address this challenge, we propose a novel bi-level unsupervised feature selection (BLUFS) method, including a clustering level and a feature level. Specifically, at the clustering level, spectral clustering is used to generate pseudo-labels for representing the data structure, while a continuous linear regression model is developed to learn the projection matrix. At the feature level, the $\ell_{2,0}$-norm constraint is imposed on the projection matrix for more effectively selecting features. To the best of our knowledge, this is the first work to combine a bi-level framework with the $\ell_{2,0}$-norm. To solve the proposed bi-level model, we design an efficient proximal alternating minimization (PAM) algorithm, whose subproblems either have explicit solutions or can be computed by fast solvers. Furthermore, we establish the convergence result and computational complexity. Finally, extensive experiments on two synthetic datasets and eight real datasets demonstrate the superiority of BLUFS in clustering and classification tasks.
Adaptive Multi-Order Graph Regularized NMF with Dual Sparsity for Hyperspectral Unmixing
Mar 25, 2025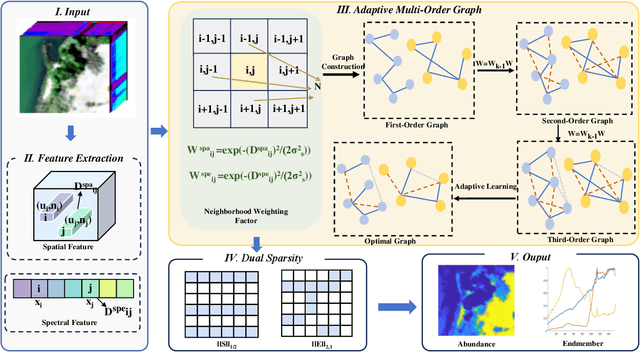
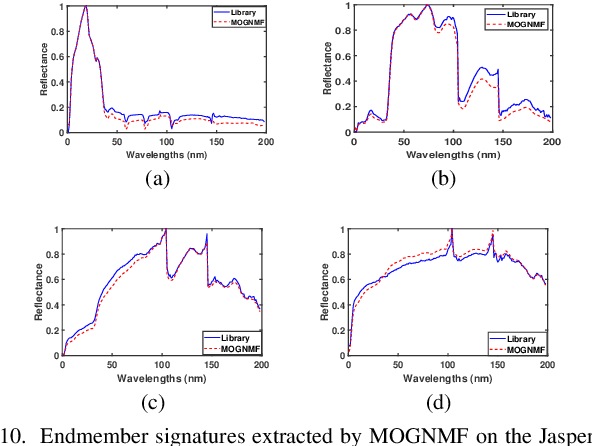
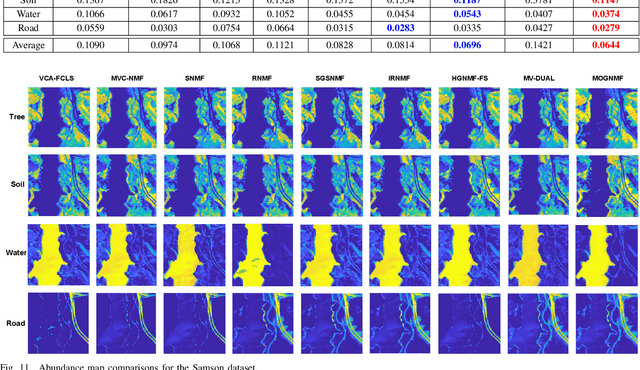
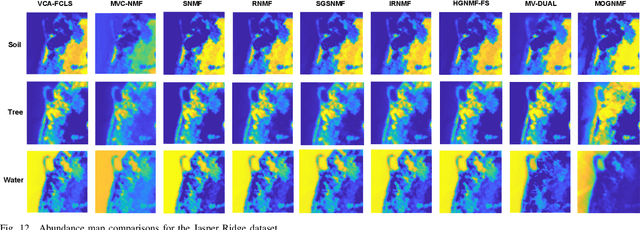
Hyperspectral unmixing (HU) is a critical yet challenging task in remote sensing. However, existing nonnegative matrix factorization (NMF) methods with graph learning mostly focus on first-order or second-order nearest neighbor relationships and usually require manual parameter tuning, which fails to characterize intrinsic data structures. To address the above issues, we propose a novel adaptive multi-order graph regularized NMF method (MOGNMF) with three key features. First, multi-order graph regularization is introduced into the NMF framework to exploit global and local information comprehensively. Second, these parameters associated with the multi-order graph are learned adaptively through a data-driven approach. Third, dual sparsity is embedded to obtain better robustness, i.e., $\ell_{1/2}$-norm on the abundance matrix and $\ell_{2,1}$-norm on the noise matrix. To solve the proposed model, we develop an alternating minimization algorithm whose subproblems have explicit solutions, thus ensuring effectiveness. Experiments on simulated and real hyperspectral data indicate that the proposed method delivers better unmixing results.
MATCNN: Infrared and Visible Image Fusion Method Based on Multi-scale CNN with Attention Transformer
Feb 04, 2025



While attention-based approaches have shown considerable progress in enhancing image fusion and addressing the challenges posed by long-range feature dependencies, their efficacy in capturing local features is compromised by the lack of diverse receptive field extraction techniques. To overcome the shortcomings of existing fusion methods in extracting multi-scale local features and preserving global features, this paper proposes a novel cross-modal image fusion approach based on a multi-scale convolutional neural network with attention Transformer (MATCNN). MATCNN utilizes the multi-scale fusion module (MSFM) to extract local features at different scales and employs the global feature extraction module (GFEM) to extract global features. Combining the two reduces the loss of detail features and improves the ability of global feature representation. Simultaneously, an information mask is used to label pertinent details within the images, aiming to enhance the proportion of preserving significant information in infrared images and background textures in visible images in fused images. Subsequently, a novel optimization algorithm is developed, leveraging the mask to guide feature extraction through the integration of content, structural similarity index measurement, and global feature loss. Quantitative and qualitative evaluations are conducted across various datasets, revealing that MATCNN effectively highlights infrared salient targets, preserves additional details in visible images, and achieves better fusion results for cross-modal images. The code of MATCNN will be available at https://github.com/zhang3849/MATCNN.git.