 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-SCOPE: Fully Sparse Long-Range Cooperative 3D Perception
Apr 10, 2026Cooperative 3D perception via Vehicle-to-Everything communication is a promising paradigm for enhancing autonomous driving, offering extended sensing horizons and occlusion resolution. However, the practical deployment of existing methods is hindered at long distances by two critical bottlenecks: the quadratic computational scaling of dense BEV representations and the fragility of feature association mechanisms under significant observation and alignment errors. To overcome these limitations, we introduce Long-SCOPE, a fully sparse framework designed for robust long-distance cooperative 3D perception. Our method features two novel components: a Geometry-guided Query Generation module to accurately detect small, distant objects, and a learnable Context-Aware Association module that robustly matches cooperative queries despite severe positional noise. Experiments on the V2X-Seq and Griffin datasets validate that Long-SCOPE achieves state-of-the-art performance, particularly in challenging 100-150 m long-range settings, while maintaining highly competitive computation and communication costs.
Confidence-Calibrated Small-Large Language Model Collaboration for Cost-Efficient Reasoning
Mar 04, 2026Large language models (LLMs) demonstrate superior reasoning capabilities compared to small language models (SLMs), but incur substantially higher costs. We propose COllaborative REAsoner (COREA), a system that cascades an SLM with an LLM to achieve a balance between accuracy and cost in complex reasoning tasks. COREA first attempts to answer questions using the SLM, which outputs both an answer and a verbalized confidence score. Questions with confidence below a predefined threshold are deferred to the LLM for more accurate resolution. We introduce a reinforcement learning-based training algorithm that aligns the SLM's confidence through an additional confidence calibration reward. Extensive experiments demonstrate that our method jointly improves the SLM's reasoning ability and confidence calibration across diverse datasets and model backbones. Compared to using the LLM alone, COREA reduces cost by 21.5% and 16.8% on out-of-domain math and non-math datasets, respectively, with only an absolute pass@1 drop within 2%.
Low-Altitude UAV-Carried Movable Antenna for Joint Wireless Power Transfer and Covert Communications
Oct 30, 2025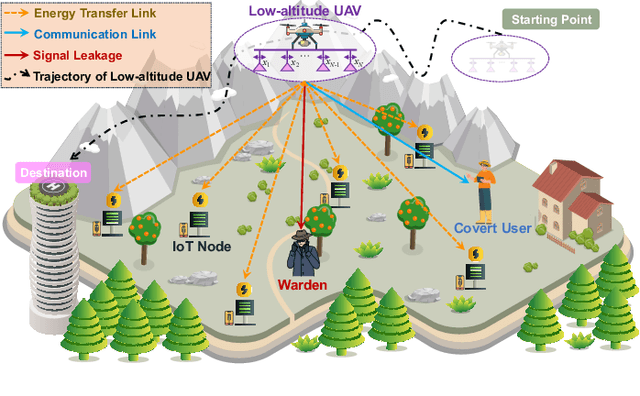
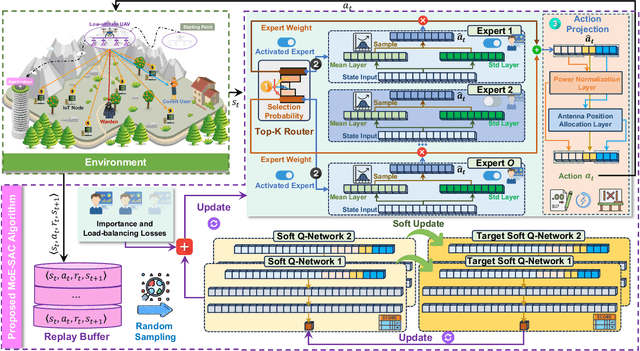
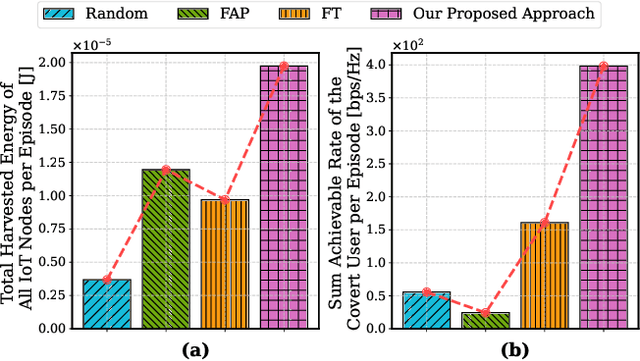
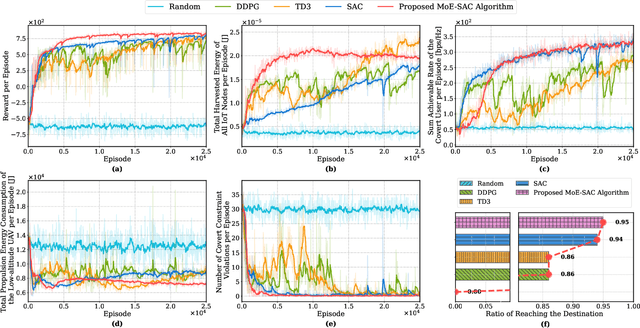
The proliferation of Internet of Things (IoT) networks has created an urgent need for sustainable energy solutions, particularly for the battery-constrained spatially distributed IoT nodes. While low-altitude uncrewed aerial vehicles (UAVs) employed with wireless power transfer (WPT) capabilities offer a promising solution, the line-of-sight channels that facilitate efficient energy delivery also expose sensitive operational data to adversaries. This paper proposes a novel low-altitude UAV-carried movable antenna-enhanced transmission system joint WPT and covert communications, which simultaneously performs energy supplements to IoT nodes and establishes transmission links with a covert user by leveraging wireless energy signals as a natural cover. Then, we formulate a multi-objective optimization problem that jointly maximizes the total harvested energy of IoT nodes and sum achievable rate of the covert user, while minimizing the propulsion energy consumption of the low-altitude UAV. To address the non-convex and temporally coupled optimization problem, we propose a mixture-of-experts-augmented soft actor-critic (MoE-SAC) algorithm that employs a sparse Top-K gated mixture-of-shallow-experts architecture to represent multimodal policy distributions arising from the conflicting optimization objectives. We also incorporate an action projection module that explicitly enforces per-time-slot power budget constraints and antenna position constraints. Simulation results demonstrate that the proposed approach significantly outperforms some baseline approaches and other state-of-the-art deep reinforcement learning algorithms.
Energy Efficient Trajectory Control and Resource Allocation in Multi-UAV-assisted MEC via Deep Reinforcement Learning
Aug 01, 2025Mobile edge computing (MEC) is a promising technique to improve the computational capacity of smart devices (SDs) in Internet of Things (IoT). However, the performance of MEC is restricted due to its fixed location and limited service scope. Hence, we investigate an unmanned aerial vehicle (UAV)-assisted MEC system, where multiple UAVs are dispatched and each UAV can simultaneously provide computing service for multiple SDs. To improve the performance of system, we formulated a UAV-based trajectory control and resource allocation multi-objective optimization problem (TCRAMOP) to simultaneously maximize the offloading number of UAVs and minimize total offloading delay and total energy consumption of UAVs by optimizing the flight paths of UAVs as well as the computing resource allocated to served SDs. Then, consider that the solution of TCRAMOP requires continuous decision-making and the system is dynamic, we propose an enhanced deep reinforcement learning (DRL) algorithm, namely, distributed proximal policy optimization with imitation learning (DPPOIL). This algorithm incorporates the generative adversarial imitation learning technique to improve the policy performance. Simulation results demonstrate the effectiveness of our proposed DPPOIL and prove that the learned strategy of DPPOIL is better compared with other baseline methods.
Large AI Model-Enabled Secure Communications in Low-Altitude Wireless Networks: Concepts, Perspectives and Case Study
Aug 01, 2025Low-altitude wireless networks (LAWNs) have the potential to revolutionize communications by supporting a range of applications, including urban parcel delivery, aerial inspections and air taxis. However, compared with traditional wireless networks, LAWNs face unique security challenges due to low-altitude operations, frequent mobility and reliance on unlicensed spectrum, making it more vulnerable to some malicious attacks. In this paper, we investigate some large artificial intelligence model (LAM)-enabled solutions for secure communications in LAWNs. Specifically, we first explore the amplified security risks and important limitations of traditional AI methods in LAWNs. Then, we introduce the basic concepts of LAMs and delve into the role of LAMs in addressing these challenges. To demonstrate the practical benefits of LAMs for secure communications in LAWNs, we propose a novel LAM-based optimization framework that leverages large language models (LLMs) to generate enhanced state features on top of handcrafted representations, and to design intrinsic rewards accordingly, thereby improving reinforcement learning performance for secure communication tasks. Through a typical case study, simulation results validate the effectiveness of the proposed framework. Finally, we outline future directions for integrating LAMs into secure LAWN applications.
DriveCamSim: Generalizable Camera Simulation via Explicit Camera Modeling for Autonomous Driving
May 26, 2025Camera sensor simulation serves as a critical role for autonomous driving (AD), e.g. evaluating vision-based AD algorithms. While existing approaches have leveraged generative models for controllable image/video generation, they remain constrained to generating multi-view video sequences with fixed camera viewpoints and video frequency, significantly limiting their downstream applications. To address this, we present a generalizable camera simulation framework DriveCamSim, whose core innovation lies in the proposed Explicit Camera Modeling (ECM) mechanism. Instead of implicit interaction through vanilla attention, ECM establishes explicit pixel-wise correspondences across multi-view and multi-frame dimensions, decoupling the model from overfitting to the specific camera configurations (intrinsic/extrinsic parameters, number of views) and temporal sampling rates presented in the training data. For controllable generation, we identify the issue of information loss inherent in existing conditional encoding and injection pipelines, proposing an information-preserving control mechanism. This control mechanism not only improves conditional controllability, but also can be extended to be identity-aware to enhance temporal consistency in foreground object rendering. With above designs, our model demonstrates superior performance in both visual quality and controllability, as well as generalization capability across spatial-level (camera parameters variations) and temporal-level (video frame rate variations), enabling flexible user-customizable camera simulation tailored to diverse application scenarios. Code will be avaliable at https://github.com/swc-17/DriveCamSim for facilitating future research.
MFogHub: Bridging Multi-Regional and Multi-Satellite Data for Global Marine Fog Detection and Forecasting
May 15, 2025Deep learning approaches for marine fog detection and forecasting have outperformed traditional methods, demonstrating significant scientific and practical importance. However, the limited availability of open-source datasets remains a major challenge. Existing datasets, often focused on a single region or satellite, restrict the ability to evaluate model performance across diverse conditions and hinder the exploration of intrinsic marine fog characteristics. To address these limitations, we introduce \textbf{MFogHub}, the first multi-regional and multi-satellite dataset to integrate annotated marine fog observations from 15 coastal fog-prone regions and six geostationary satellites, comprising over 68,000 high-resolution samples. By encompassing diverse regions and satellite perspectives, MFogHub facilitates rigorous evaluation of both detection and forecasting methods under varying conditions. Extensive experiments with 16 baseline models demonstrate that MFogHub can reveal generalization fluctuations due to regional and satellite discrepancy, while also serving as a valuable resource for the development of targeted and scalable fog prediction techniques. Through MFogHub, we aim to advance both the practical monitoring and scientific understanding of marine fog dynamics on a global scale. The dataset and code are at \href{https://github.com/kaka0910/MFogHub}{https://github.com/kaka0910/MFogHub}.
Aerial Active STAR-RIS-assisted Satellite-Terrestrial Covert Communications
Apr 22, 2025An integration of satellites and terrestrial networks is crucial for enhancing performance of next generation communication systems. However, the networks are hindered by the long-distance path loss and security risks in dense urban environments. In this work, we propose a satellite-terrestrial covert communication system assisted by the aerial active simultaneous transmitting and reflecting reconfigurable intelligent surface (AASTAR-RIS) to improve the channel capacity while ensuring the transmission covertness. Specifically, we first derive the minimal detection error probability (DEP) under the worst condition that the Warden has perfect channel state information (CSI). Then, we formulate an AASTAR-RIS-assisted satellite-terrestrial covert communication optimization problem (ASCCOP) to maximize the sum of the fair channel capacity for all ground users while meeting the strict covert constraint, by jointly optimizing the trajectory and active beamforming of the AASTAR-RIS. Due to the challenges posed by the complex and high-dimensional state-action spaces as well as the need for efficient exploration in dynamic environments, we propose a generative deterministic policy gradient (GDPG) algorithm, which is a generative deep reinforcement learning (DRL) method to solve the ASCCOP. Concretely, the generative diffusion model (GDM) is utilized as the policy representation of the algorithm to enhance the exploration process by generating diverse and high-quality samples through a series of denoising steps. Moreover, we incorporate an action gradient mechanism to accomplish the policy improvement of the algorithm, which refines the better state-action pairs through the gradient ascent. Simulation results demonstrate that the proposed approach significantly outperforms important benchmarks.
Enhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
Apr 14, 2025



The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.
DenseFormer: Learning Dense Depth Map from Sparse Depth and Image via Conditional Diffusion Model
Mar 31, 2025



The depth completion task is a critical problem in autonomous driving, involving the generation of dense depth maps from sparse depth maps and RGB images. Most existing methods employ a spatial propagation network to iteratively refine the depth map after obtaining an initial dense depth. In this paper, we propose DenseFormer, a novel method that integrates the diffusion model into the depth completion task. By incorporating the denoising mechanism of the diffusion model, DenseFormer generates the dense depth map by progressively refining an initial random depth distribution through multiple iterations. We propose a feature extraction module that leverages a feature pyramid structure, along with multi-layer deformable attention, to effectively extract and integrate features from sparse depth maps and RGB images, which serve as the guiding condition for the diffusion process. Additionally, this paper presents a depth refinement module that applies multi-step iterative refinement across various ranges to the dense depth results generated by the diffusion process. The module utilizes image features enriched with multi-scale information and sparse depth input to further enhance the accuracy of the predicted depth map. Extensive experiments on the KITTI outdoor scene dataset demonstrate that DenseFormer outperforms classical depth completion methods.