 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevitalizing Reconstruction Models for Multi-class Anomaly Detection via Class-Aware Contrastive Learning
Dec 06, 2024



For anomaly detection (AD), early approaches often train separate models for individual classes, yielding high performance but posing challenges in scalability and resource management. Recent efforts have shifted toward training a single model capable of handling multiple classes. However, directly extending early AD methods to multi-class settings often results in degraded performance. In this paper, we analyze this degradation observed in reconstruction-based methods, identifying two key issues: catastrophic forgetting and inter-class confusion. To this end, we propose a plug-and-play modification by incorporating class-aware contrastive learning (CL). By explicitly leveraging raw object category information (e.g., carpet or wood) as supervised signals, we apply local CL to fine-tune multiscale features and global CL to learn more compact feature representations of normal patterns, thereby effectively adapting the models to multi-class settings. Experiments across four datasets (over 60 categories) verify the effectiveness of our approach, yielding significant improvements and superior performance compared to advanced methods. Notably, ablation studies show that even using pseudo-class labels can achieve comparable performance.
Boundary-Guided Learning for Gene Expression Prediction in Spatial Transcriptomics
Dec 05, 2024



Spatial transcriptomics (ST) has emerged as an advanced technology that provides spatial context to gene expression. Recently, deep learning-based methods have shown the capability to predict gene expression from WSI data using ST data. Existing approaches typically extract features from images and the neighboring regions using pretrained models, and then develop methods to fuse this information to generate the final output. However, these methods often fail to account for the cellular structure similarity, cellular density and the interactions within the microenvironment. In this paper, we propose a framework named BG-TRIPLEX, which leverages boundary information extracted from pathological images as guiding features to enhance gene expression prediction from WSIs. Specifically, our model consists of three branches: the spot, in-context and global branches. In the spot and in-context branches, boundary information, including edge and nuclei characteristics, is extracted using pretrained models. These boundary features guide the learning of cellular morphology and the characteristics of microenvironment through Multi-Head Cross-Attention. Finally, these features are integrated with global features to predict the final output. Extensive experiments were conducted on three public ST datasets. The results demonstrate that our BG-TRIPLEX consistently outperforms existing methods in terms of Pearson Correlation Coefficient (PCC). This method highlights the crucial role of boundary features in understanding the complex interactions between WSI and gene expression, offering a promising direction for future research.
Hypergraph Multi-modal Large Language Model: Exploiting EEG and Eye-tracking Modalities to Evaluate Heterogeneous Responses for Video Understanding
Jul 11, 2024



Understanding of video creativity and content often varies among individuals, with differences in focal points and cognitive levels across different ages, experiences, and genders. There is currently a lack of research in this area, and most existing benchmarks suffer from several drawbacks: 1) a limited number of modalities and answers with restrictive length; 2) the content and scenarios within the videos are excessively monotonous, transmitting allegories and emotions that are overly simplistic. To bridge the gap to real-world applications, we introduce a large-scale \textbf{S}ubjective \textbf{R}esponse \textbf{I}ndicators for \textbf{A}dvertisement \textbf{V}ideos dataset, namely SRI-ADV. Specifically, we collected real changes in Electroencephalographic (EEG) and eye-tracking regions from different demographics while they viewed identical video content. Utilizing this multi-modal dataset, we developed tasks and protocols to analyze and evaluate the extent of cognitive understanding of video content among different users. Along with the dataset, we designed a \textbf{H}ypergraph \textbf{M}ulti-modal \textbf{L}arge \textbf{L}anguage \textbf{M}odel (HMLLM) to explore the associations among different demographics, video elements, EEG and eye-tracking indicators. HMLLM could bridge semantic gaps across rich modalities and integrate information beyond different modalities to perform logical reasoning. Extensive experimental evaluations on SRI-ADV and other additional video-based generative performance benchmarks demonstrate the effectiveness of our method. The codes and dataset will be released at \url{https://github.com/suay1113/HMLLM}.
ToCoAD: Two-Stage Contrastive Learning for Industrial Anomaly Detection
Jul 01, 2024



Current unsupervised anomaly detection approaches perform well on public datasets but struggle with specific anomaly types due to the domain gap between pre-trained feature extractors and target-specific domains. To tackle this issue, this paper presents a two-stage training strategy, called \textbf{ToCoAD}. In the first stage, a discriminative network is trained by using synthetic anomalies in a self-supervised learning manner. This network is then utilized in the second stage to provide a negative feature guide, aiding in the training of the feature extractor through bootstrap contrastive learning. This approach enables the model to progressively learn the distribution of anomalies specific to industrial datasets, effectively enhancing its generalizability to various types of anomalies. Extensive experiments are conducted to demonstrate the effectiveness of our proposed two-stage training strategy, and our model produces competitive performance, achieving pixel-level AUROC scores of 98.21\%, 98.43\% and 97.70\% on MVTec AD, VisA and BTAD respectively.
3D High-Fidelity Mask Face Presentation Attack Detection Challenge
Aug 16, 2021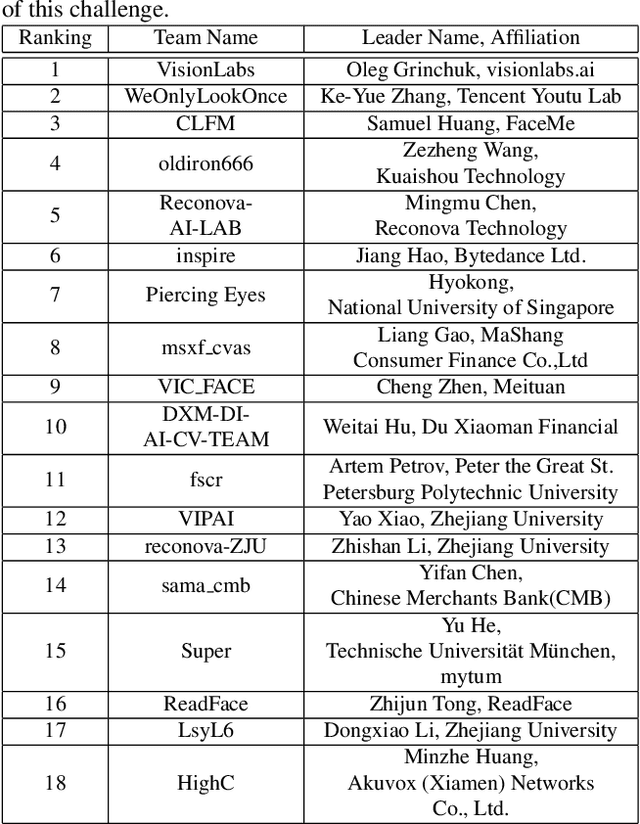
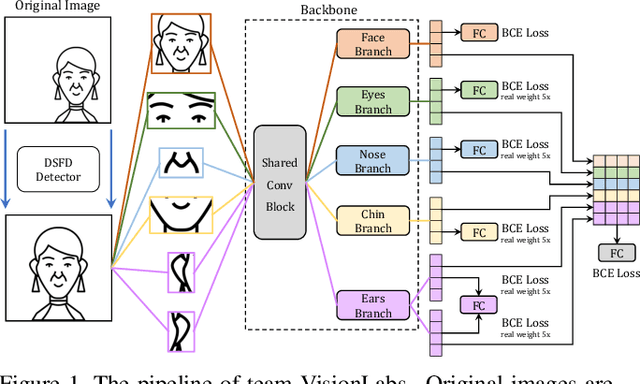
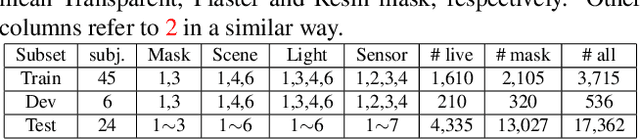
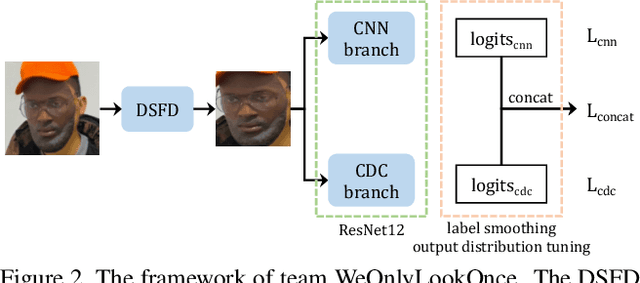
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers. To facilitate the study of the algorithms, a large-scale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask) has been collected. Specifically, it consists of a total amount of 54, 600 videos which are recorded from 75 subjects with 225 realistic masks under 7 new kinds of sensors. Based on this dataset and Protocol 3 which evaluates both the discrimination and generalization ability of the algorithm under the open set scenarios, we organized a 3D High-Fidelity Mask Face Presentation Attack Detection Challenge to boost the research of 3D mask-based attack detection. It attracted 195 teams for the development phase with a total of 18 teams qualifying for the final round. All the results were verified and re-run by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including the introduction of the dataset used, the definition of the protocol, the calculation of the evaluation criteria, and the summary and publication of the competition results. Finally, we focus on introducing and analyzing the top ranking algorithms, the conclusion summary, and the research ideas for mask attack detection provided by this competition.
Contrastive Context-Aware Learning for 3D High-Fidelity Mask Face Presentation Attack Detection
Apr 13, 2021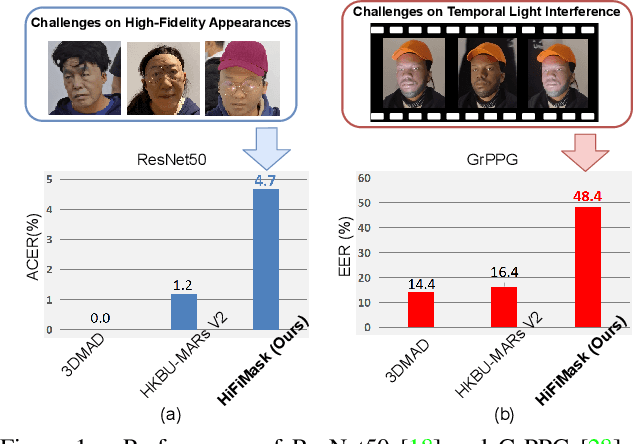
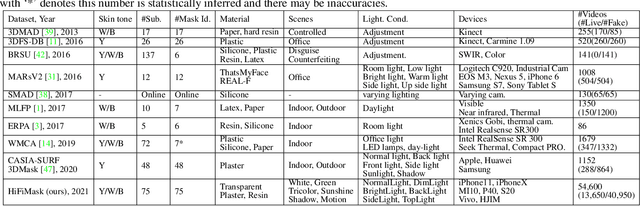

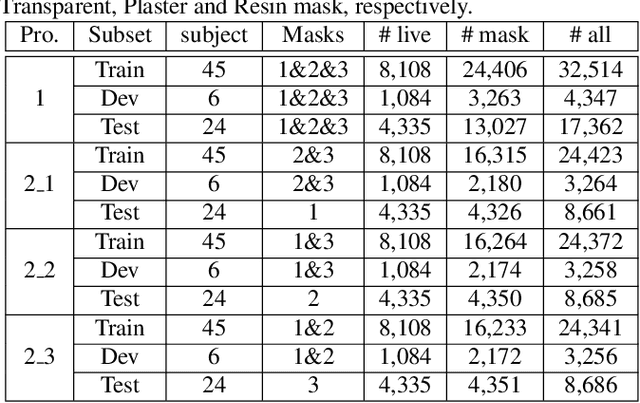
Face presentation attack detection (PAD) is essential to secure face recognition systems primarily from high-fidelity mask attacks. Most existing 3D mask PAD benchmarks suffer from several drawbacks: 1) a limited number of mask identities, types of sensors, and a total number of videos; 2) low-fidelity quality of facial masks. Basic deep models and remote photoplethysmography (rPPG) methods achieved acceptable performance on these benchmarks but still far from the needs of practical scenarios. To bridge the gap to real-world applications, we introduce a largescale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask). Specifically, a total amount of 54,600 videos are recorded from 75 subjects with 225 realistic masks by 7 new kinds of sensors. Together with the dataset, we propose a novel Contrastive Context-aware Learning framework, namely CCL. CCL is a new training methodology for supervised PAD tasks, which is able to learn by leveraging rich contexts accurately (e.g., subjects, mask material and lighting) among pairs of live faces and high-fidelity mask attacks. Extensive experimental evaluations on HiFiMask and three additional 3D mask datasets demonstrate the effectiveness of our method.