 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiWorld: Scalable Multi-Agent Multi-View Video World Models
Apr 21, 2026Video world models have achieved remarkable success in simulating environmental dynamics in response to actions by users or agents. They are modeled as action-conditioned video generation models that take historical frames and current actions as input to predict future frames. Yet, most existing approaches are limited to single-agent scenarios and fail to capture the complex interactions inherent in real-world multi-agent systems. We present \textbf{MultiWorld}, a unified framework for multi-agent multi-view world modeling that enables accurate control of multiple agents while maintaining multi-view consistency. We introduce the Multi-Agent Condition Module to achieve precise multi-agent controllability, and the Global State Encoder to ensure coherent observations across different views. MultiWorld supports flexible scaling of agent and view counts, and synthesizes different views in parallel for high efficiency. Experiments on multi-player game environments and multi-robot manipulation tasks demonstrate that MultiWorld outperforms baselines in video fidelity, action-following ability, and multi-view consistency. Project page: https://multi-world.github.io/
CreativeGame:Toward Mechanic-Aware Creative Game Generation
Apr 21, 2026Large language models can generate plausible game code, but turning this capability into \emph{iterative creative improvement} remains difficult. In practice, single-shot generation often produces brittle runtime behavior, weak accumulation of experience across versions, and creativity scores that are too subjective to serve as reliable optimization signals. A further limitation is that mechanics are frequently treated only as post-hoc descriptions, rather than as explicit objects that can be planned, tracked, preserved, and evaluated during generation. This report presents \textbf{CreativeGame}, a multi-agent system for iterative HTML5 game generation that addresses these issues through four coupled ideas: a proxy reward centered on programmatic signals rather than pure LLM judgment; lineage-scoped memory for cross-version experience accumulation; runtime validation integrated into both repair and reward; and a mechanic-guided planning loop in which retrieved mechanic knowledge is converted into an explicit mechanic plan before code generation begins. The goal is not merely to produce a playable artifact in one step, but to support interpretable version-to-version evolution. The current system contains 71 stored lineages, 88 saved nodes, and a 774-entry global mechanic archive, implemented in 6{,}181 lines of Python together with inspection and visualization tooling. The system is therefore substantial enough to support architectural analysis, reward inspection, and real lineage-level case studies rather than only prompt-level demos. A real 4-generation lineage shows that mechanic-level innovation can emerge in later versions and can be inspected directly through version-to-version records. The central contribution is therefore not only game generation, but a concrete pipeline for observing progressive evolution through explicit mechanic change.
Geometry-Aware Rotary Position Embedding for Consistent Video World Model
Feb 08, 2026Predictive world models that simulate future observations under explicit camera control are fundamental to interactive AI. Despite rapid advances, current systems lack spatial persistence: they fail to maintain stable scene structures over long trajectories, frequently hallucinating details when cameras revisit previously observed locations. We identify that this geometric drift stems from reliance on screen-space positional embeddings, which conflict with the projective geometry required for 3D consistency. We introduce \textbf{ViewRope}, a geometry-aware encoding that injects camera-ray directions directly into video transformer self-attention layers. By parameterizing attention with relative ray geometry rather than pixel locality, ViewRope provides a model-native inductive bias for retrieving 3D-consistent content across temporal gaps. We further propose \textbf{Geometry-Aware Frame-Sparse Attention}, which exploits these geometric cues to selectively attend to relevant historical frames, improving efficiency without sacrificing memory consistency. We also present \textbf{ViewBench}, a diagnostic suite measuring loop-closure fidelity and geometric drift. Our results demonstrate that ViewRope substantially improves long-term consistency while reducing computational costs.
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Jun 12, 2025Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
Process Reward Modeling with Entropy-Driven Uncertainty
Mar 28, 2025



This paper presents the Entropy-Driven Unified Process Reward Model (EDU-PRM), a novel framework that approximates state-of-the-art performance in process supervision while drastically reducing training costs. EDU-PRM introduces an entropy-guided dynamic step partitioning mechanism, using logit distribution entropy to pinpoint high-uncertainty regions during token generation dynamically. This self-assessment capability enables precise step-level feedback without manual fine-grained annotation, addressing a critical challenge in process supervision. Experiments on the Qwen2.5-72B model with only 7,500 EDU-PRM-generated training queries demonstrate accuracy closely approximating the full Qwen2.5-72B-PRM (71.1% vs. 71.6%), achieving a 98% reduction in query cost compared to prior methods. This work establishes EDU-PRM as an efficient approach for scalable process reward model training.
Cross-Domain Feature Augmentation for Domain Generalization
May 14, 2024



Domain generalization aims to develop models that are robust to distribution shifts. Existing methods focus on learning invariance across domains to enhance model robustness, and data augmentation has been widely used to learn invariant predictors, with most methods performing augmentation in the input space. However, augmentation in the input space has limited diversity whereas in the feature space is more versatile and has shown promising results. Nonetheless, feature semantics is seldom considered and existing feature augmentation methods suffer from a limited variety of augmented features. We decompose features into class-generic, class-specific, domain-generic, and domain-specific components. We propose a cross-domain feature augmentation method named XDomainMix that enables us to increase sample diversity while emphasizing the learning of invariant representations to achieve domain generalization. Experiments on widely used benchmark datasets demonstrate that our proposed method is able to achieve state-of-the-art performance. Quantitative analysis indicates that our feature augmentation approach facilitates the learning of effective models that are invariant across different domains.
Towards Robust Out-of-Distribution Generalization Bounds via Sharpness
Mar 11, 2024Generalizing to out-of-distribution (OOD) data or unseen domain, termed OOD generalization, still lacks appropriate theoretical guarantees. Canonical OOD bounds focus on different distance measurements between source and target domains but fail to consider the optimization property of the learned model. As empirically shown in recent work, the sharpness of learned minima influences OOD generalization. To bridge this gap between optimization and OOD generalization, we study the effect of sharpness on how a model tolerates data change in domain shift which is usually captured by "robustness" in generalization. In this paper, we give a rigorous connection between sharpness and robustness, which gives better OOD guarantees for robust algorithms. It also provides a theoretical backing for "flat minima leads to better OOD generalization". Overall, we propose a sharpness-based OOD generalization bound by taking robustness into consideration, resulting in a tighter bound than non-robust guarantees. Our findings are supported by the experiments on a ridge regression model, as well as the experiments on deep learning classification tasks.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
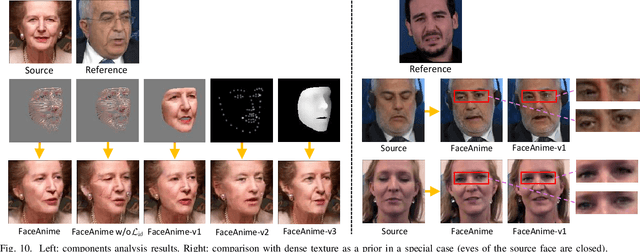
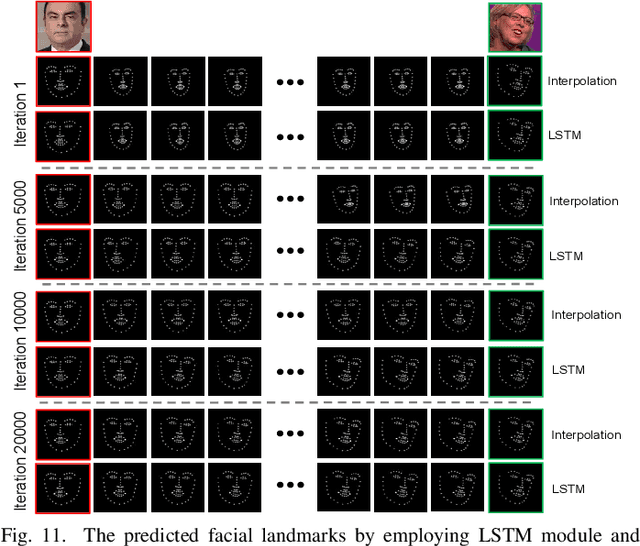
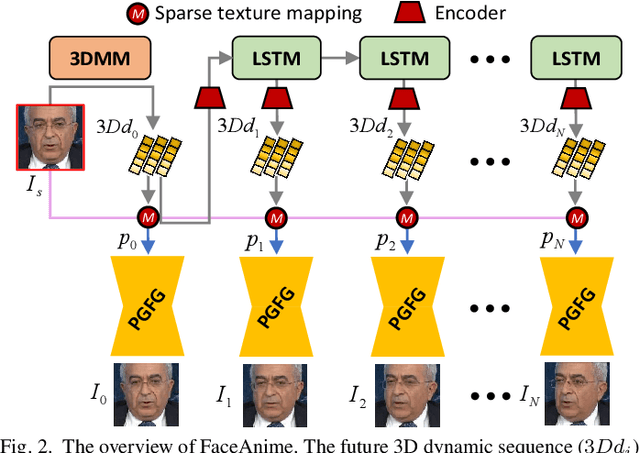
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
PANet: Few-Shot Image Semantic Segmentation with Prototype Alignment
Aug 18, 2019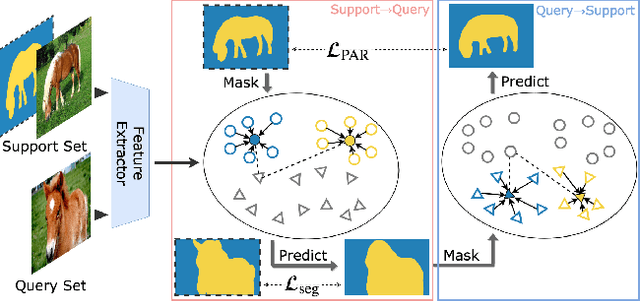
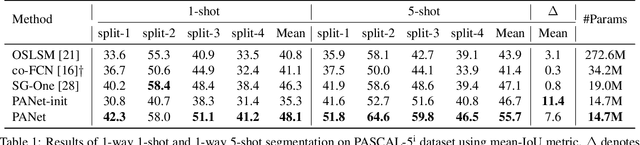
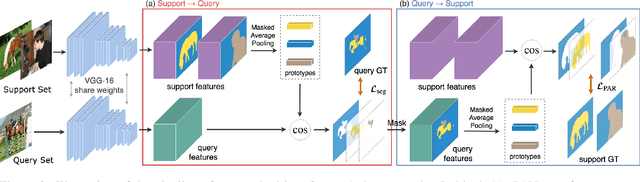
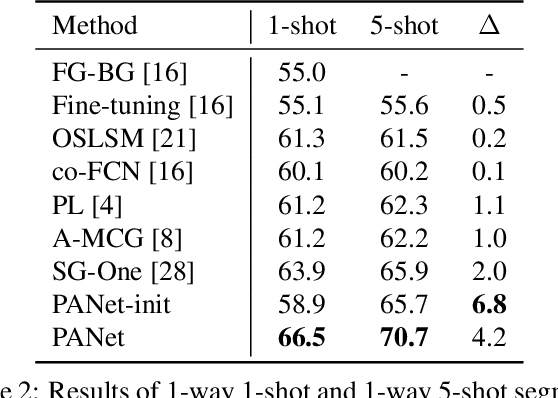
Despite the great progress made by deep CNNs in image semantic segmentation, they typically require a large number of densely-annotated images for training and are difficult to generalize to unseen object categories. Few-shot segmentation has thus been developed to learn to perform segmentation from only a few annotated examples. In this paper, we tackle the challenging few-shot segmentation problem from a metric learning perspective and present PANet, a novel prototype alignment network to better utilize the information of the support set. Our PANet learns class-specific prototype representations from a few support images within an embedding space and then performs segmentation over the query images through matching each pixel to the learned prototypes. With non-parametric metric learning, PANet offers high-quality prototypes that are representative for each semantic class and meanwhile discriminative for different classes. Moreover, PANet introduces a prototype alignment regularization between support and query. With this, PANet fully exploits knowledge from the support and provides better generalization on few-shot segmentation. Significantly, our model achieves the mIoU score of 48.1% and 55.7% on PASCAL-5i for 1-shot and 5-shot settings respectively, surpassing the state-of-the-art method by 1.8% and 8.6%.
Panoptic Edge Detection
Jun 03, 2019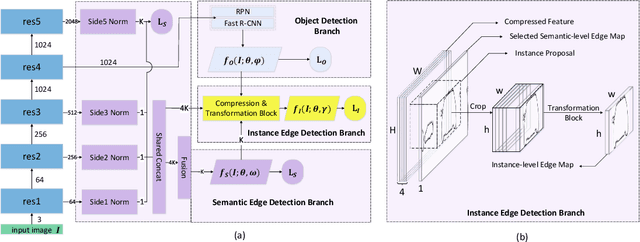
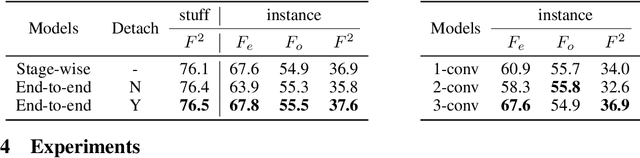

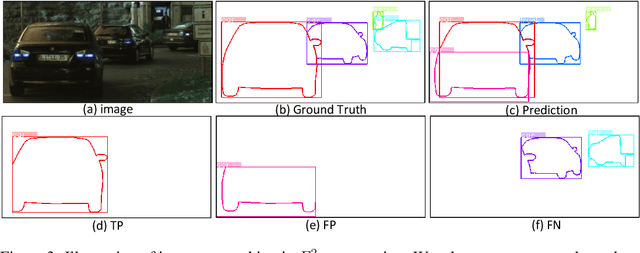
Pursuing more complete and coherent scene understanding towards realistic vision applications drives edge detection from category-agnostic to category-aware semantic level. However, finer delineation of instance-level boundaries still remains unexcavated. In this work, we address a new finer-grained task, termed panoptic edge detection (PED), which aims at predicting semantic-level boundaries for stuff categories and instance-level boundaries for instance categories, in order to provide more comprehensive and unified scene understanding from the perspective of edges.We then propose a versatile framework, Panoptic Edge Network (PEN), which aggregates different tasks of object detection, semantic and instance edge detection into a single holistic network with multiple branches. Based on the same feature representation, the semantic edge branch produces semantic-level boundaries for all categories and the object detection branch generates instance proposals. Conditioned on the prior information from these two branches, the instance edge branch aims at instantiating edge predictions for instance categories. Besides, we also devise a Panoptic Dual F-measure (F2) metric for the new PED task to uniformly measure edge prediction quality for both stuff and instances. By joint end-to-end training, the proposed PEN framework outperforms all competitive baselines on Cityscapes and ADE20K datasets.