 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizontally Fused Training Array: An Effective Hardware Utilization Squeezer for Training Novel Deep Learning Models
Feb 07, 2021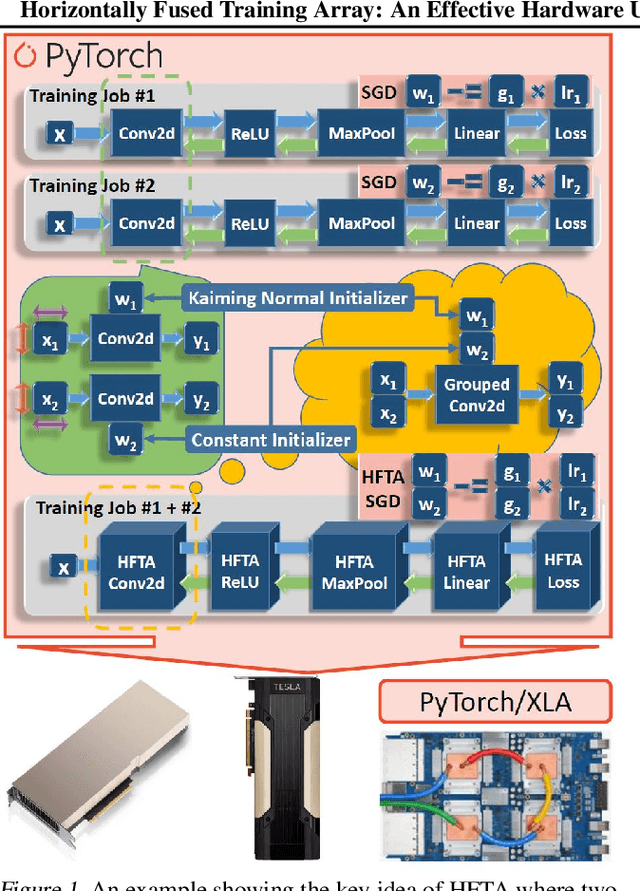
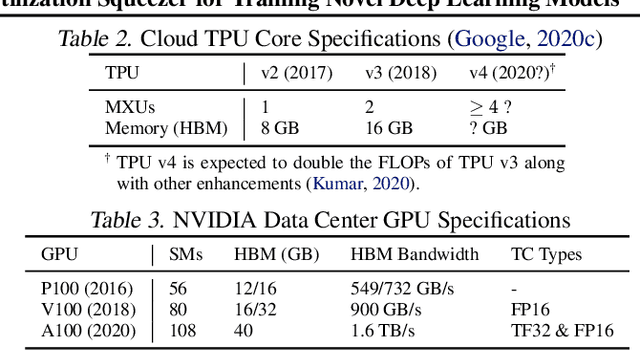

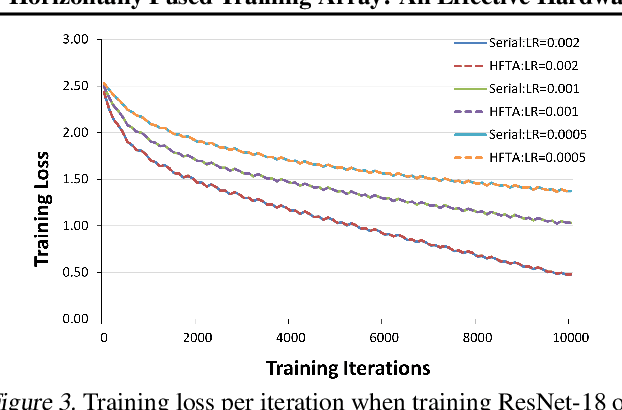
Driven by the tremendous effort in researching novel deep learning (DL) algorithms, the training cost of developing new models increases staggeringly in recent years. To reduce this training cost and optimize the cluster-wide hardware resource usage, we analyze GPU cluster usage statistics from a well-known research institute. Our study reveals that single-accelerator training jobs can dominate the cluster-wide resource consumption when launched repetitively (e.g., for hyper-parameter tuning) while severely underutilizing the hardware. This is because DL researchers and practitioners often lack the required expertise to independently optimize their own workloads. Fortunately, we observe that such workloads have the following unique characteristics: (i) the models among jobs often have the same types of operators with the same shapes, and (ii) the inter-model horizontal fusion of such operators is mathematically equivalent to other already well-optimized operators. Thus, to help DL researchers and practitioners effectively and easily improve the hardware utilization of their novel DL training workloads, we propose Horizontally Fused Training Array (HFTA). HFTA is a new DL framework extension library that horizontally fuses the models from different repetitive jobs deeply down to operators, and then trains those models simultaneously on a shared accelerator. On three emerging DL training workloads and state-of-the-art accelerators (GPUs and TPUs), HFTA demonstrates strong effectiveness in squeezing out hardware utilization and achieves up to $15.1 \times$ higher training throughput vs. the standard practice of running each job on a separate accelerator.
Computational Performance Predictions for Deep Neural Network Training: A Runtime-Based Approach
Jan 31, 2021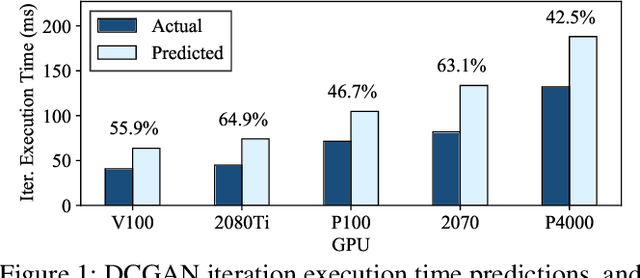
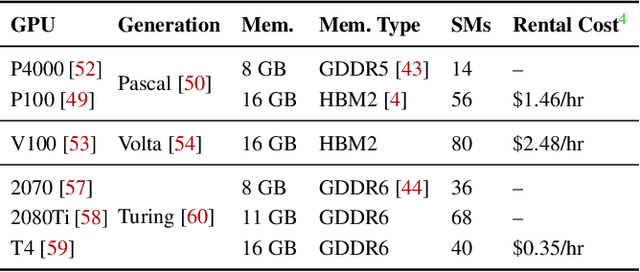

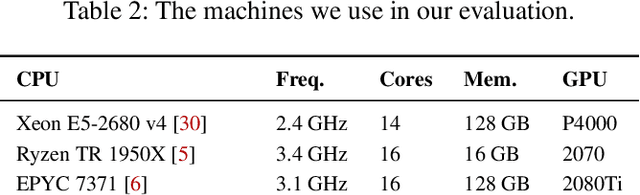
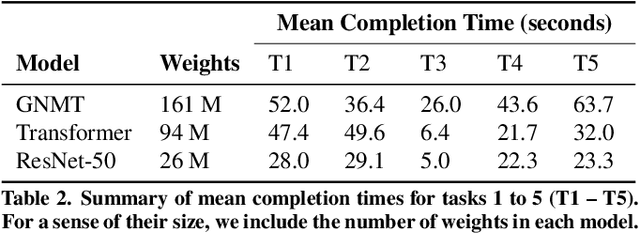
Deep learning researchers and practitioners usually leverage GPUs to help train their deep neural networks (DNNs) faster. However, choosing which GPU to use is challenging both because (i) there are many options, and (ii) users grapple with competing concerns: maximizing compute performance while minimizing costs. In this work, we present a new practical technique to help users make informed and cost-efficient GPU selections: make performance predictions using the help of a GPU that the user already has. Our technique exploits the observation that, because DNN training consists of repetitive compute steps, predicting the execution time of a single iteration is usually enough to characterize the performance of an entire training process. We make predictions by scaling the execution time of each operation in a training iteration from one GPU to another using either (i) wave scaling, a technique based on a GPU's execution model, or (ii) pre-trained multilayer perceptrons. We implement our technique into a Python library called Surfer and find that it makes accurate iteration execution time predictions on ResNet-50, Inception v3, the Transformer, GNMT, and DCGAN across six different GPU architectures. Surfer currently supports PyTorch, is easy to use, and requires only a few lines of code.
IOS: Inter-Operator Scheduler for CNN Acceleration
Nov 02, 2020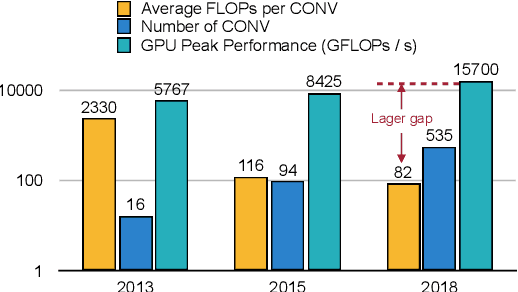
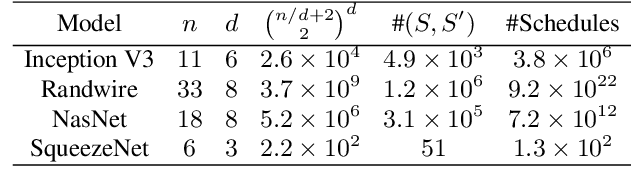
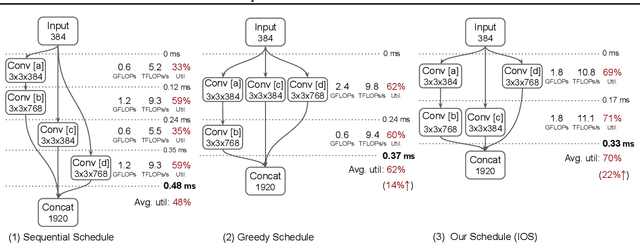
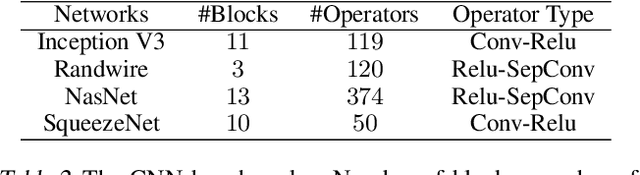
To accelerate CNN inference, existing deep learning frameworks focus on optimizing intra-operator parallelization. However, a single operator can no longer fully utilize the available parallelism given the rapid advances in high-performance hardware, resulting in a large gap between the peak performance and the real performance. This performance gap is more severe under smaller batch sizes. In this work, we extensively study the parallelism between operators and propose Inter-Operator Scheduler (IOS) to automatically schedule the execution of multiple operators in parallel. IOS utilizes dynamic programming to find a scheduling policy specialized for the target hardware. IOS consistently outperforms state-of-the-art libraries (e.g., TensorRT) by 1.1 to 1.5x on modern CNN benchmarks.
FPRaker: A Processing Element For Accelerating Neural Network Training
Oct 15, 2020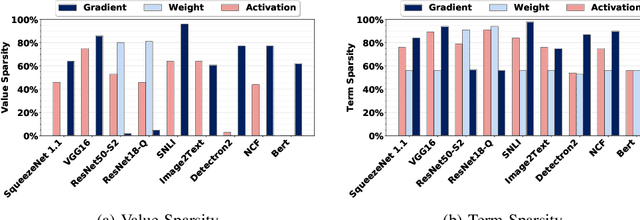
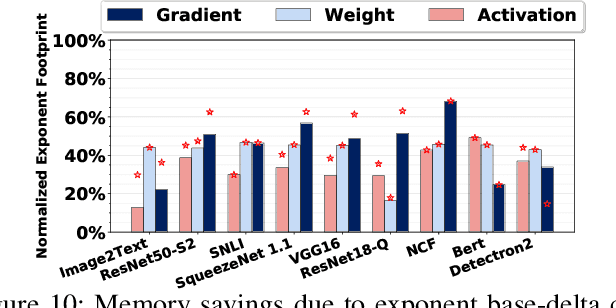
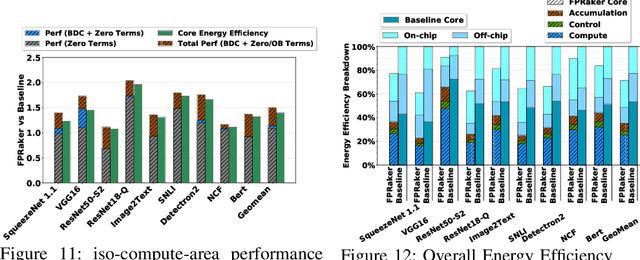
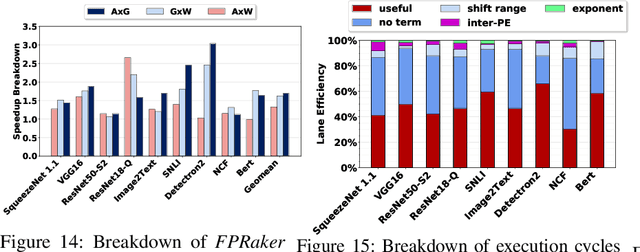
We present FPRaker, a processing element for composing training accelerators. FPRaker processes several floating-point multiply-accumulation operations concurrently and accumulates their result into a higher precision accumulator. FPRaker boosts performance and energy efficiency during training by taking advantage of the values that naturally appear during training. Specifically, it processes the significand of the operands of each multiply-accumulate as a series of signed powers of two. The conversion to this form is done on-the-fly. This exposes ineffectual work that can be skipped: values when encoded have few terms and some of them can be discarded as they would fall outside the range of the accumulator given the limited precision of floating-point. We demonstrate that FPRaker can be used to compose an accelerator for training and that it can improve performance and energy efficiency compared to using conventional floating-point units under ISO-compute area constraints. We also demonstrate that FPRaker delivers additional benefits when training incorporates pruning and quantization. Finally, we show that FPRaker naturally amplifies performance with training methods that use a different precision per layer.
TensorDash: Exploiting Sparsity to Accelerate Deep Neural Network Training and Inference
Sep 01, 2020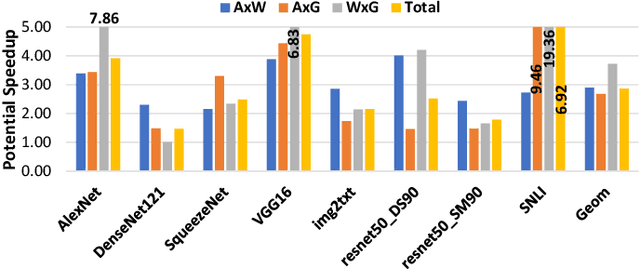
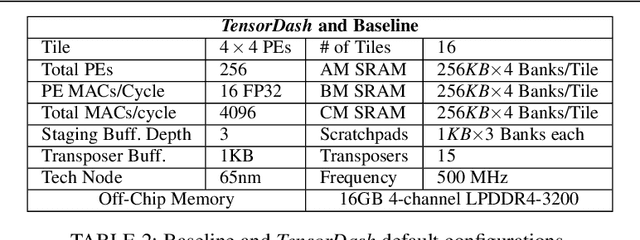
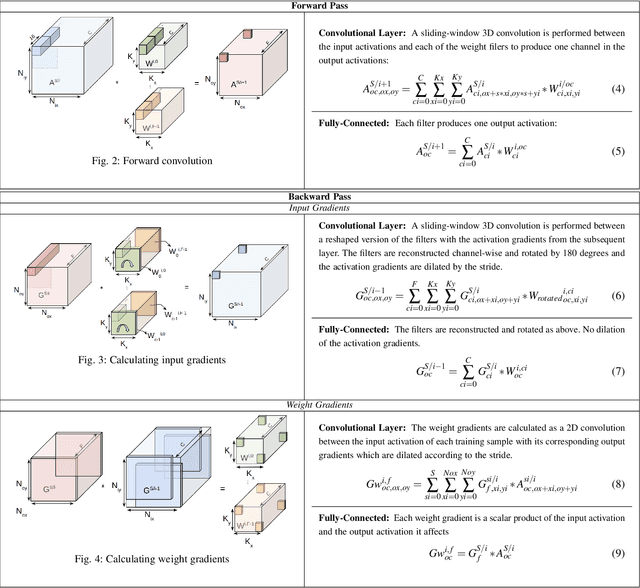
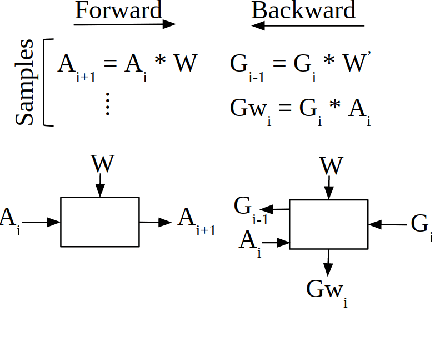
TensorDash is a hardware level technique for enabling data-parallel MAC units to take advantage of sparsity in their input operand streams. When used to compose a hardware accelerator for deep learning, TensorDash can speedup the training process while also increasing energy efficiency. TensorDash combines a low-cost, sparse input operand interconnect comprising an 8-input multiplexer per multiplier input, with an area-efficient hardware scheduler. While the interconnect allows a very limited set of movements per operand, the scheduler can effectively extract sparsity when it is present in the activations, weights or gradients of neural networks. Over a wide set of models covering various applications, TensorDash accelerates the training process by $1.95{\times}$ while being $1.89\times$ more energy-efficient, $1.6\times$ more energy efficient when taking on-chip and off-chip memory accesses into account. While TensorDash works with any datatype, we demonstrate it with both single-precision floating-point units and bfloat16.
Skyline: Interactive In-Editor Computational Performance Profiling for Deep Neural Network Training
Aug 20, 2020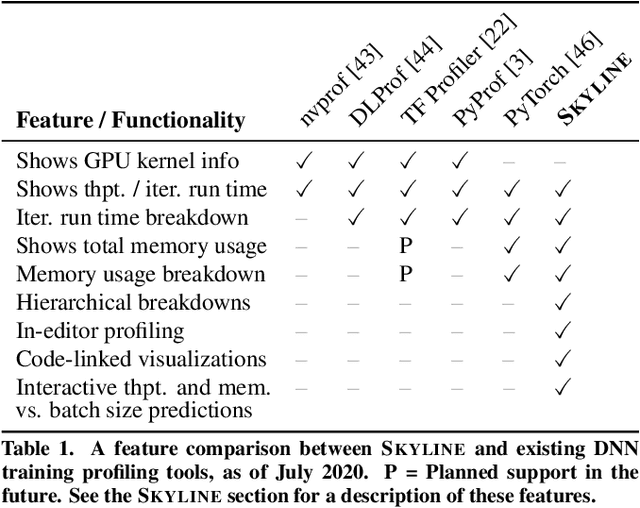
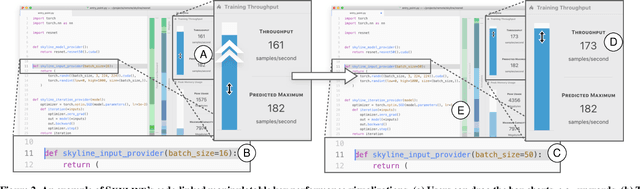
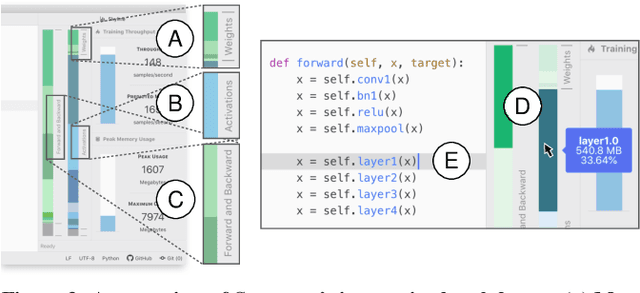
Training a state-of-the-art deep neural network (DNN) is a computationally-expensive and time-consuming process, which incentivizes deep learning developers to debug their DNNs for computational performance. However, effectively performing this debugging requires intimate knowledge about the underlying software and hardware systems---something that the typical deep learning developer may not have. To help bridge this gap, we present Skyline: a new interactive tool for DNN training that supports in-editor computational performance profiling, visualization, and debugging. Skyline's key contribution is that it leverages special computational properties of DNN training to provide (i) interactive performance predictions and visualizations, and (ii) directly manipulatable visualizations that, when dragged, mutate the batch size in the code. As an in-editor tool, Skyline allows users to leverage these diagnostic features to debug the performance of their DNNs during development. An exploratory qualitative user study of Skyline produced promising results; all the participants found Skyline to be useful and easy to use.
Multi-node Bert-pretraining: Cost-efficient Approach
Aug 01, 2020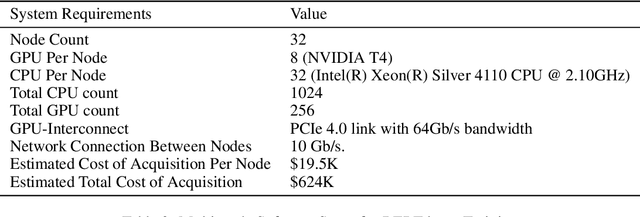
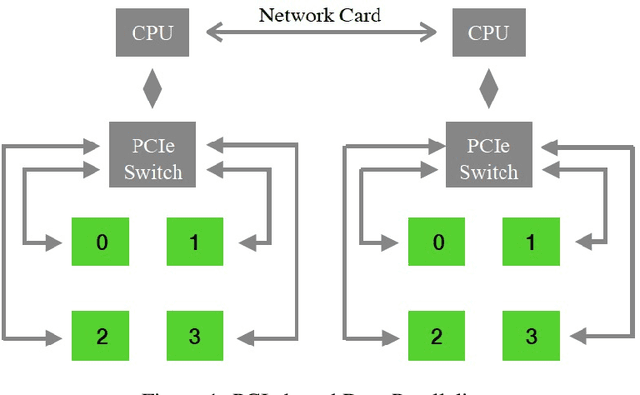
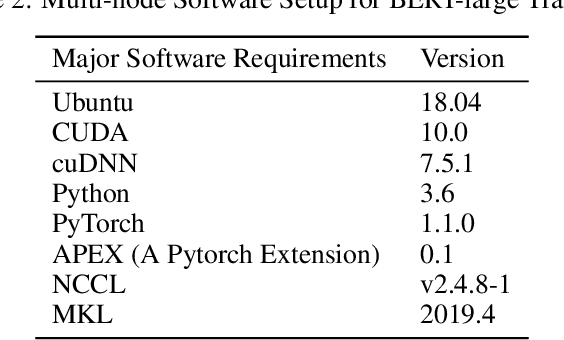

Recently, large scale Transformer-based language models such as BERT, GPT-2, and XLNet have brought about exciting leaps in state-of-the-art results for many Natural Language Processing (NLP) tasks. One of the common trends in these recent models is a significant increase in model complexity, which introduces both more weights and computation. Moreover, with the advent of large-scale unsupervised datasets, training time is further extended due to the increased amount of data samples within a single training epoch. As a result, to train these models within a reasonable time, machine learning (ML) programmers often require advanced hardware setups such as the premium GPU-enabled NVIDIA DGX workstations or specialized accelerators such as Google's TPU Pods. Our work addresses this limitation and demonstrates that the BERT pre-trained model can be trained within 2 weeks on an academic-size cluster of widely available GPUs through careful algorithmic and software optimizations. In this paper, we present these optimizations on how to improve single device training throughput, distribute the training workload over multiple nodes and GPUs, and overcome the communication bottleneck introduced by the large data exchanges over the network. We show that we are able to perform pre-training on BERT within a reasonable time budget (12 days) in an academic setting, but with a much less expensive and less aggressive hardware resource requirement than in previously demonstrated industrial settings based on NVIDIA DGX machines or Google's TPU Pods.
Daydream: Accurately Estimating the Efficacy of Optimizations for DNN Training
Jun 05, 2020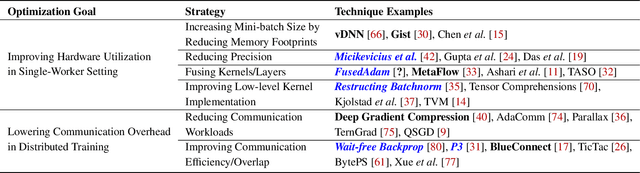
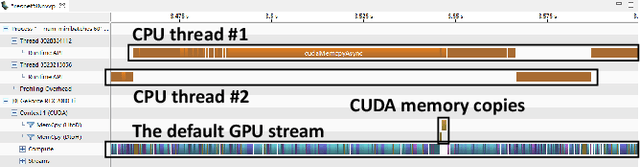

Modern deep neural network (DNN) training jobs use complex and heterogeneous software/hardware stacks. The efficacy of software-level optimizations can vary significantly when used in different deployment configurations. It is onerous and error-prone for ML practitioners and system developers to implement each optimization separately, and determine which ones will improve performance in their own configurations. Unfortunately, existing profiling tools do not aim to answer predictive questions such as "How will optimization X affect the performance of my model?". We address this critical limitation, and proposes a new profiling tool, Daydream, to help programmers efficiently explore the efficacy of DNN optimizations. Daydream models DNN execution with a fine-grained dependency graph based on low-level traces collected by CUPTI, and predicts runtime by simulating execution based on the dependency graph. Daydream maps the low-level traces using DNN domain-specific knowledge, and introduces a set of graph-transformation primitives that can easily model a wide variety of optimizations. We show that Daydream is able to model most mainstream DNN optimization techniques, and accurately predict the efficacy of optimizations that will result in significant performance improvements.
MLPerf Inference Benchmark
Nov 06, 2019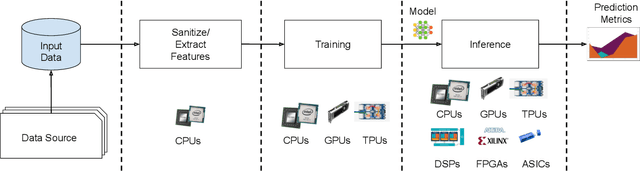
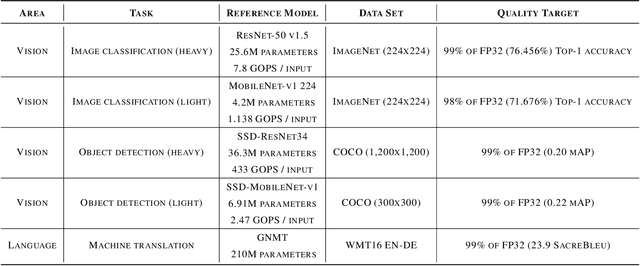
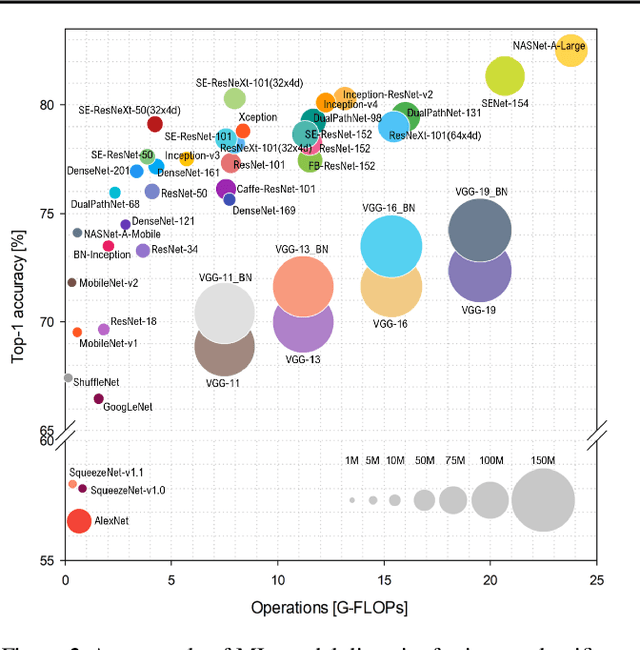
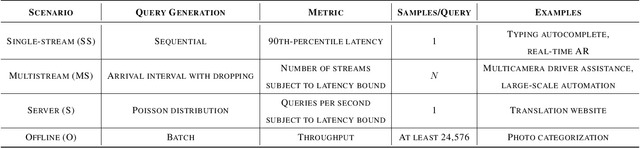
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
MLPerf Training Benchmark
Oct 30, 2019
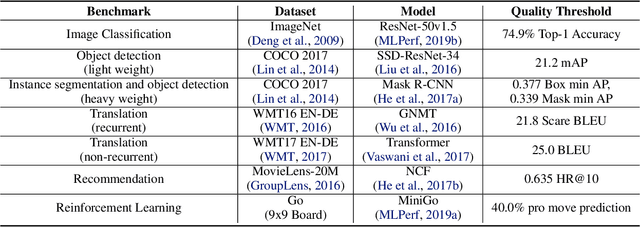
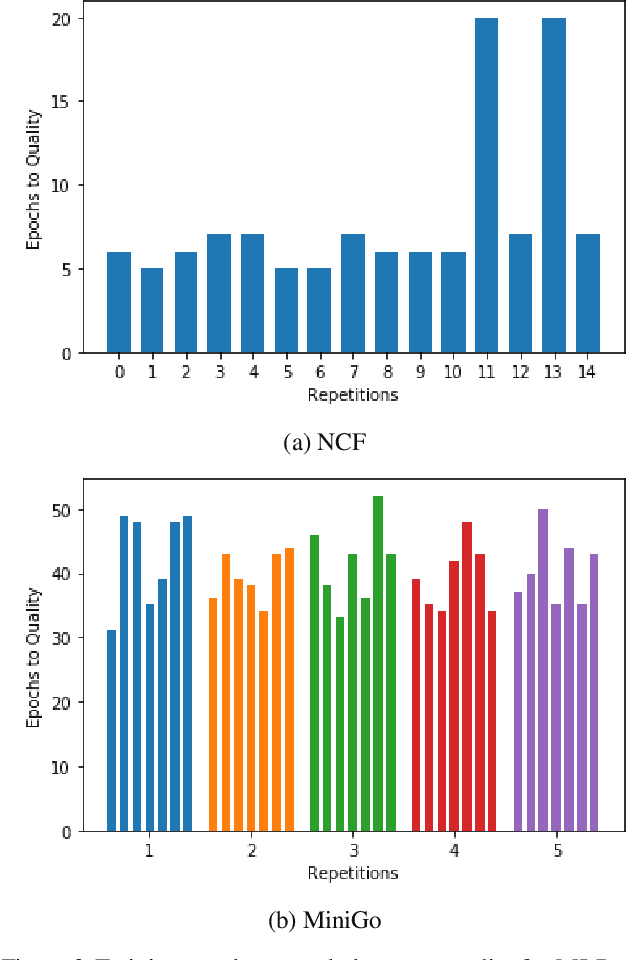
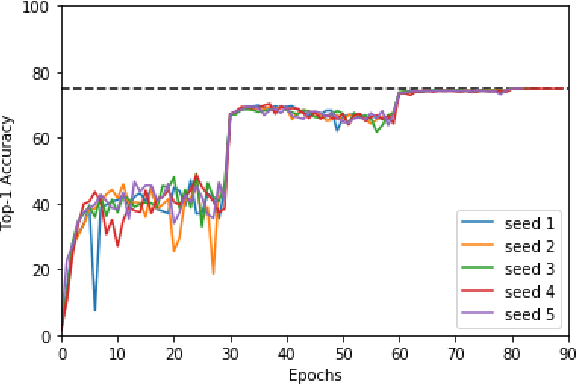
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.