 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the Communication-Accuracy Trade-off in Federated Learning with Rate-Distortion Theory
Jan 07, 2022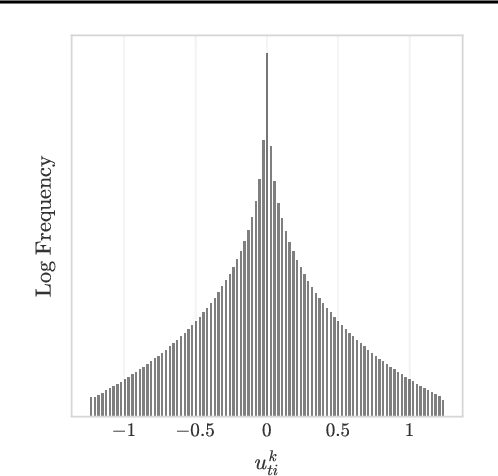

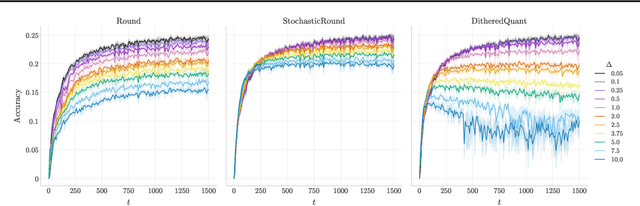
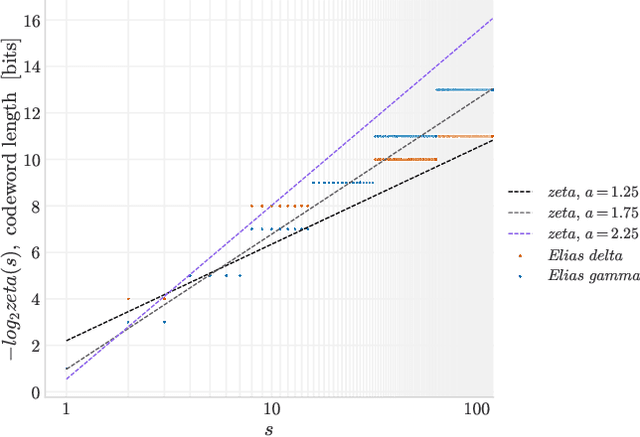
A significant bottleneck in federated learning is the network communication cost of sending model updates from client devices to the central server. We propose a method to reduce this cost. Our method encodes quantized updates with an appropriate universal code, taking into account their empirical distribution. Because quantization introduces error, we select quantization levels by optimizing for the desired trade-off in average total bitrate and gradient distortion. We demonstrate empirically that in spite of the non-i.i.d. nature of federated learning, the rate-distortion frontier is consistent across datasets, optimizers, clients and training rounds, and within each setting, distortion reliably predicts model performance. This allows for a remarkably simple compression scheme that is near-optimal in many use cases, and outperforms Top-K, DRIVE, 3LC and QSGD on the Stack Overflow next-word prediction benchmark.
Convergence and Accuracy Trade-Offs in Federated Learning and Meta-Learning
Mar 08, 2021



We study a family of algorithms, which we refer to as local update methods, generalizing many federated and meta-learning algorithms. We prove that for quadratic models, local update methods are equivalent to first-order optimization on a surrogate loss we exactly characterize. Moreover, fundamental algorithmic choices (such as learning rates) explicitly govern a trade-off between the condition number of the surrogate loss and its alignment with the true loss. We derive novel convergence rates showcasing these trade-offs and highlight their importance in communication-limited settings. Using these insights, we are able to compare local update methods based on their convergence/accuracy trade-off, not just their convergence to critical points of the empirical loss. Our results shed new light on a broad range of phenomena, including the efficacy of server momentum in federated learning and the impact of proximal client updates.
On the Outsized Importance of Learning Rates in Local Update Methods
Jul 02, 2020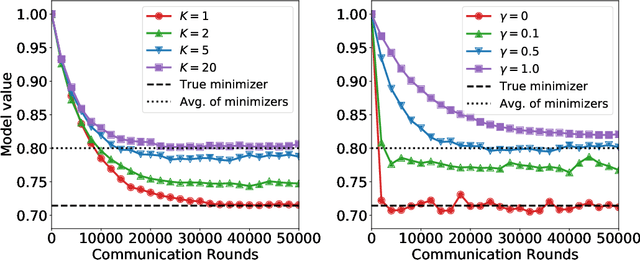

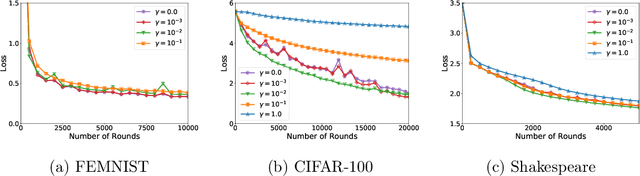
We study a family of algorithms, which we refer to as local update methods, that generalize many federated learning and meta-learning algorithms. We prove that for quadratic objectives, local update methods perform stochastic gradient descent on a surrogate loss function which we exactly characterize. We show that the choice of client learning rate controls the condition number of that surrogate loss, as well as the distance between the minimizers of the surrogate and true loss functions. We use this theory to derive novel convergence rates for federated averaging that showcase this trade-off between the condition number of the surrogate loss and its alignment with the true loss function. We validate our results empirically, showing that in communication-limited settings, proper learning rate tuning is often sufficient to reach near-optimal behavior. We also present a practical method for automatic learning rate decay in local update methods that helps reduce the need for learning rate tuning, and highlight its empirical performance on a variety of tasks and datasets.
Adaptive Federated Optimization
Feb 29, 2020
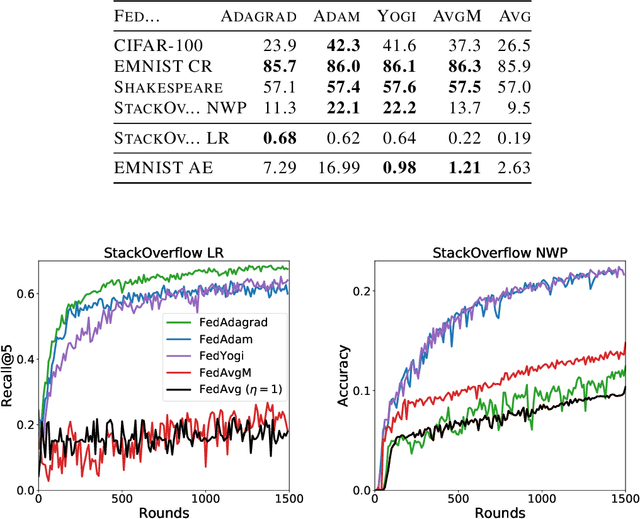
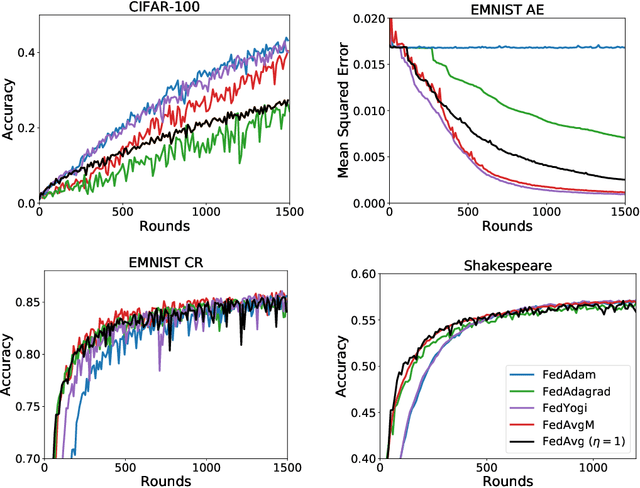
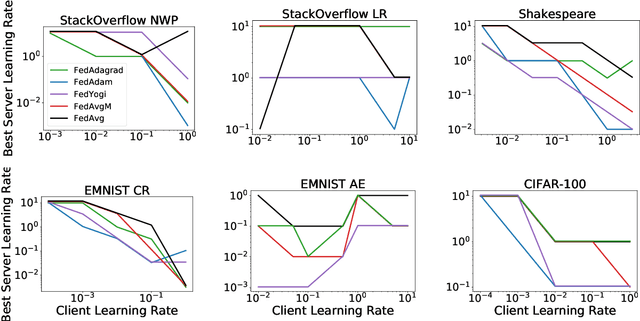
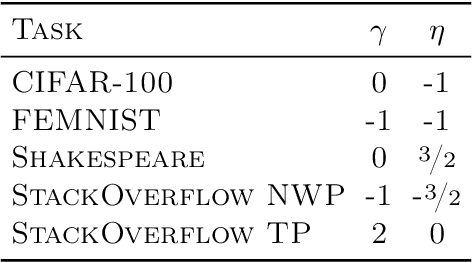
Federated learning is a distributed machine learning paradigm in which a large number of clients coordinate with a central server to learn a model without sharing their own training data. Due to the heterogeneity of the client datasets, standard federated optimization methods such as Federated Averaging (FedAvg) are often difficult to tune and exhibit unfavorable convergence behavior. In non-federated settings, adaptive optimization methods have had notable success in combating such issues. In this work, we propose federated versions of adaptive optimizers, including Adagrad, Adam, and Yogi, and analyze their convergence in the presence of heterogeneous data for general nonconvex settings. Our results highlight the interplay between client heterogeneity and communication efficiency. We also perform extensive experiments on these methods and show that the use of adaptive optimizers can significantly improve the performance of federated learning.
Advances and Open Problems in Federated Learning
Dec 10, 2019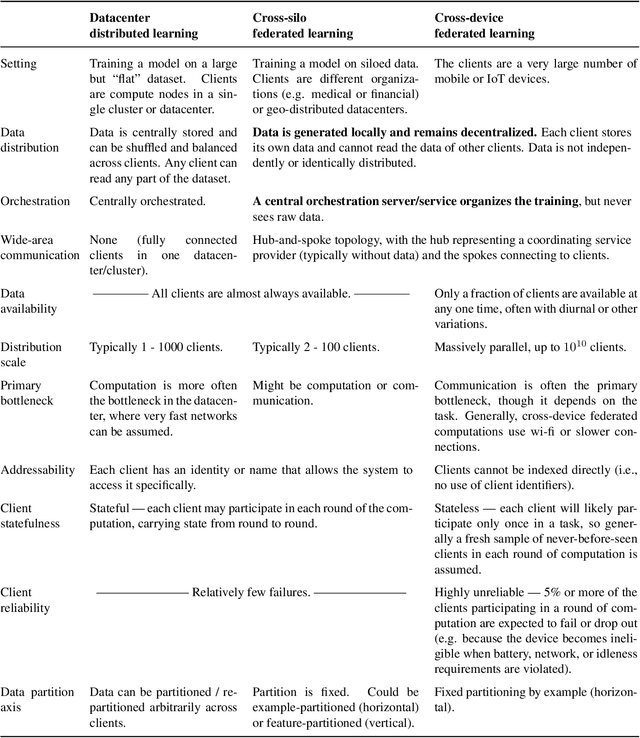
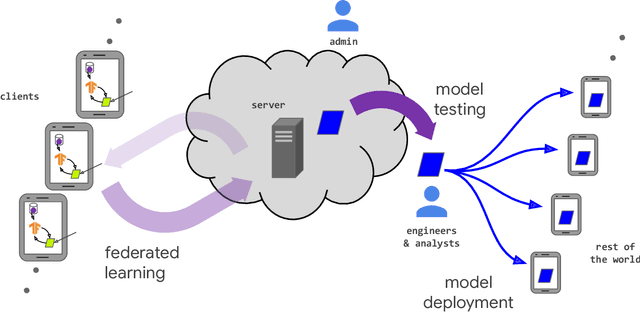
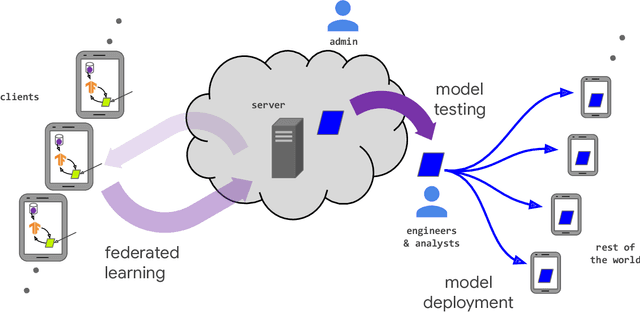

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Federated Learning with Autotuned Communication-Efficient Secure Aggregation
Nov 30, 2019
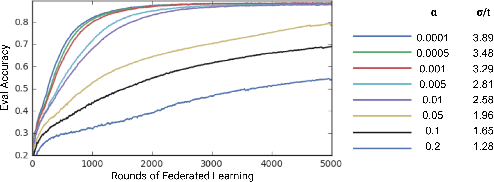
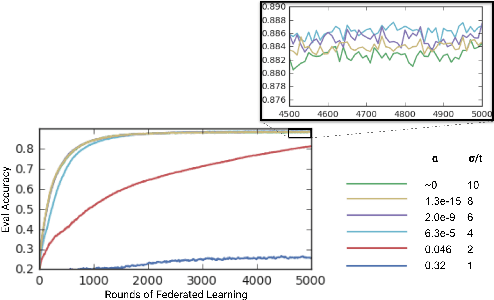
Federated Learning enables mobile devices to collaboratively learn a shared inference model while keeping all the training data on a user's device, decoupling the ability to do machine learning from the need to store the data in the cloud. Existing work on federated learning with limited communication demonstrates how random rotation can enable users' model updates to be quantized much more efficiently, reducing the communication cost between users and the server. Meanwhile, secure aggregation enables the server to learn an aggregate of at least a threshold number of device's model contributions without observing any individual device's contribution in unaggregated form. In this paper, we highlight some of the challenges of setting the parameters for secure aggregation to achieve communication efficiency, especially in the context of the aggressively quantized inputs enabled by random rotation. We then develop a recipe for auto-tuning communication-efficient secure aggregation, based on specific properties of random rotation and secure aggregation -- namely, the predictable distribution of vector entries post-rotation and the modular wrapping inherent in secure aggregation. We present both theoretical results and initial experiments.
Improving Federated Learning Personalization via Model Agnostic Meta Learning
Sep 27, 2019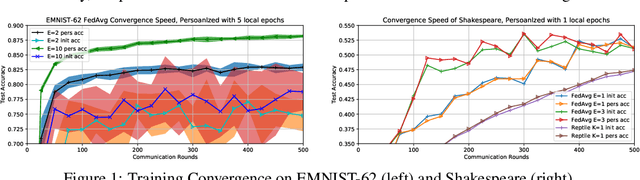
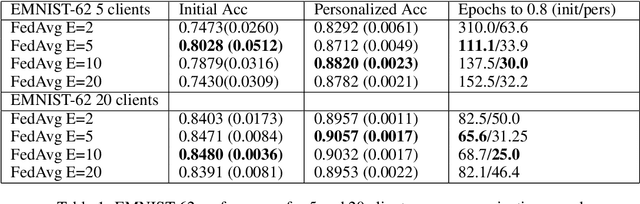
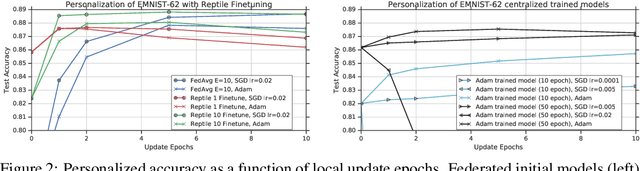

Federated Learning (FL) refers to learning a high quality global model based on decentralized data storage, without ever copying the raw data. A natural scenario arises with data created on mobile phones by the activity of their users. Given the typical data heterogeneity in such situations, it is natural to ask how can the global model be personalized for every such device, individually. In this work, we point out that the setting of Model Agnostic Meta Learning (MAML), where one optimizes for a fast, gradient-based, few-shot adaptation to a heterogeneous distribution of tasks, has a number of similarities with the objective of personalization for FL. We present FL as a natural source of practical applications for MAML algorithms, and make the following observations. 1) The popular FL algorithm, Federated Averaging, can be interpreted as a meta learning algorithm. 2) Careful fine-tuning can yield a global model with higher accuracy, which is at the same time easier to personalize. However, solely optimizing for the global model accuracy yields a weaker personalization result. 3) A model trained using a standard datacenter optimization method is much harder to personalize, compared to one trained using Federated Averaging, supporting the first claim. These results raise new questions for FL, MAML, and broader ML research.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Towards Federated Learning at Scale: System Design
Mar 22, 2019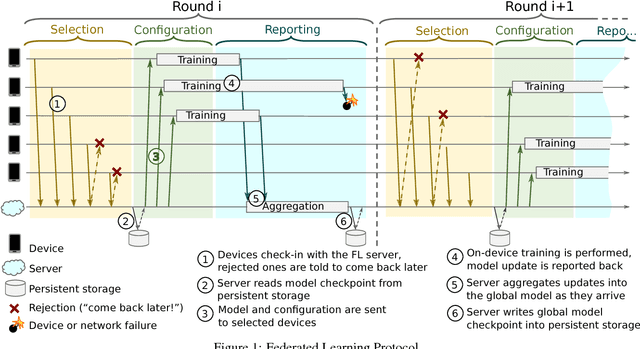
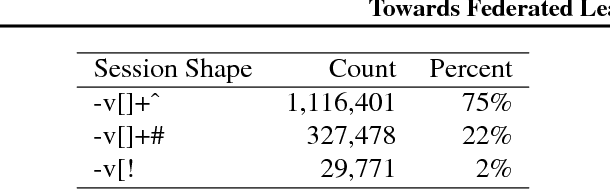
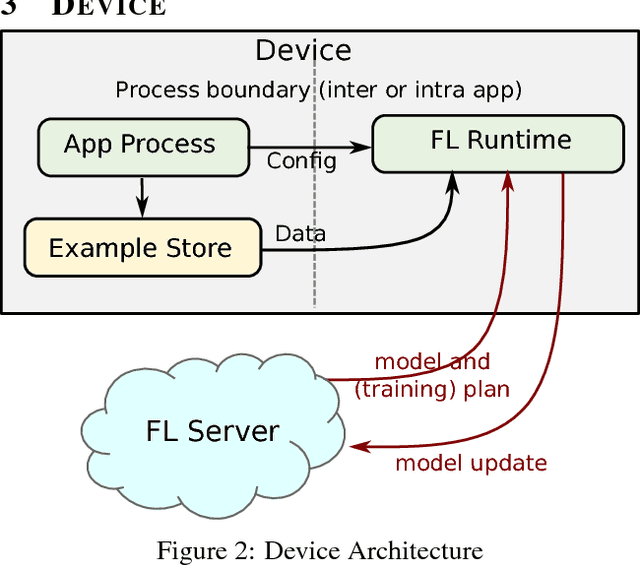
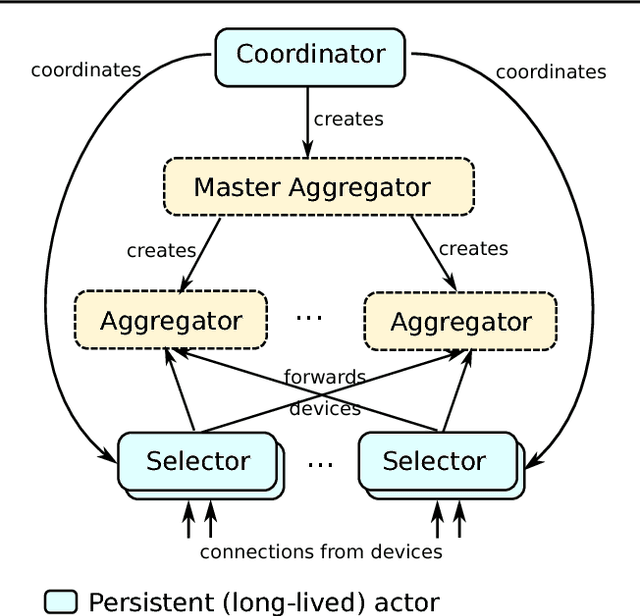
Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions.
A Privacy Preserving Randomized Gossip Algorithm via Controlled Noise Insertion
Jan 27, 2019


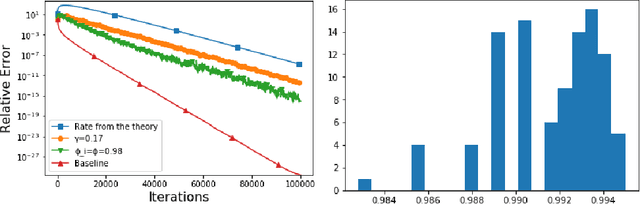
In this work we present a randomized gossip algorithm for solving the average consensus problem while at the same time protecting the information about the initial private values stored at the nodes. We give iteration complexity bounds for the method and perform extensive numerical experiments.