 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA PPA-Driven 3D-IC Partitioning Selection Framework with Surrogate Models
Apr 20, 20263D-IC netlist partitioning is commonly optimized using proxy objectives, while final PPA is treated as a costly evaluation rather than an optimization signal. This proxy-driven paradigm makes it difficult to reliably translate additional PPA evaluations into better PPA outcomes. To bridge this gap, we present DOPP (D-Optimal PPA-driven partitioning selection), an approach that bridges the gap between proxies and true PPA metrics. Across eight 3D-IC designs, our framework improves PPA over Open3DBench (average relative improvements of 9.99% congestion, 7.87% routed wirelength, 7.75% WNS, 21.85% TNS, and 1.18% power). Compared with exhaustive evaluation over the full candidate set, DOPP achieves comparable best-found PPA while evaluating only a small fraction of candidates, substantially reducing evaluation cost. By parallelizing evaluations, our method delivers these gains while maintaining wall-clock runtime comparable to traditional baselines.
Turning Black Box into White Box: Dataset Distillation Leaks
Mar 01, 2026Dataset distillation compresses a large real dataset into a small synthetic one, enabling models trained on the synthetic data to achieve performance comparable to those trained on the real data. Although synthetic datasets are assumed to be privacy-preserving, we show that existing distillation methods can cause severe privacy leakage because synthetic datasets implicitly encode the weight trajectories of the distilled model, they become over-informative and exploitable by adversaries. To expose this risk, we introduce the Information Revelation Attack (IRA) against state-of-the-art distillation techniques. Experiments show that IRA accurately predicts both the distillation algorithm and model architecture, and can successfully infer membership and recover sensitive samples from the real dataset.
Elastic Architecture Search for Efficient Language Models
Oct 30, 2025



As large pre-trained language models become increasingly critical to natural language understanding (NLU) tasks, their substantial computational and memory requirements have raised significant economic and environmental concerns. Addressing these challenges, this paper introduces the Elastic Language Model (ELM), a novel neural architecture search (NAS) method optimized for compact language models. ELM extends existing NAS approaches by introducing a flexible search space with efficient transformer blocks and dynamic modules for dimension and head number adjustment. These innovations enhance the efficiency and flexibility of the search process, which facilitates more thorough and effective exploration of model architectures. We also introduce novel knowledge distillation losses that preserve the unique characteristics of each block, in order to improve the discrimination between architectural choices during the search process. Experiments on masked language modeling and causal language modeling tasks demonstrate that models discovered by ELM significantly outperform existing methods.
The Demon is in Ambiguity: Revisiting Situation Recognition with Single Positive Multi-Label Learning
Aug 29, 2025



Context recognition (SR) is a fundamental task in computer vision that aims to extract structured semantic summaries from images by identifying key events and their associated entities. Specifically, given an input image, the model must first classify the main visual events (verb classification), then identify the participating entities and their semantic roles (semantic role labeling), and finally localize these entities in the image (semantic role localization). Existing methods treat verb classification as a single-label problem, but we show through a comprehensive analysis that this formulation fails to address the inherent ambiguity in visual event recognition, as multiple verb categories may reasonably describe the same image. This paper makes three key contributions: First, we reveal through empirical analysis that verb classification is inherently a multi-label problem due to the ubiquitous semantic overlap between verb categories. Second, given the impracticality of fully annotating large-scale datasets with multiple labels, we propose to reformulate verb classification as a single positive multi-label learning (SPMLL) problem - a novel perspective in SR research. Third, we design a comprehensive multi-label evaluation benchmark for SR that is carefully designed to fairly evaluate model performance in a multi-label setting. To address the challenges of SPMLL, we futher develop the Graph Enhanced Verb Multilayer Perceptron (GE-VerbMLP), which combines graph neural networks to capture label correlations and adversarial training to optimize decision boundaries. Extensive experiments on real-world datasets show that our approach achieves more than 3\% MAP improvement while remaining competitive on traditional top-1 and top-5 accuracy metrics.
A Transformer-based Neural Architecture Search Method
May 02, 2025



This paper presents a neural architecture search method based on Transformer architecture, searching cross multihead attention computation ways for different number of encoder and decoder combinations. In order to search for neural network structures with better translation results, we considered perplexity as an auxiliary evaluation metric for the algorithm in addition to BLEU scores and iteratively improved each individual neural network within the population by a multi-objective genetic algorithm. Experimental results show that the neural network structures searched by the algorithm outperform all the baseline models, and that the introduction of the auxiliary evaluation metric can find better models than considering only the BLEU score as an evaluation metric.
A Neural Architecture Search Method using Auxiliary Evaluation Metric based on ResNet Architecture
May 02, 2025


This paper proposes a neural architecture search space using ResNet as a framework, with search objectives including parameters for convolution, pooling, fully connected layers, and connectivity of the residual network. In addition to recognition accuracy, this paper uses the loss value on the validation set as a secondary objective for optimization. The experimental results demonstrate that the search space of this paper together with the optimisation approach can find competitive network architectures on the MNIST, Fashion-MNIST and CIFAR100 datasets.
W-PCA Based Gradient-Free Proxy for Efficient Search of Lightweight Language Models
Apr 22, 2025



The demand for efficient natural language processing (NLP) systems has led to the development of lightweight language models. Previous work in this area has primarily focused on manual design or training-based neural architecture search (NAS) methods. Recently, zero-shot NAS methods have been proposed for evaluating language models without the need for training. However, prevailing approaches to zero-shot NAS often face challenges such as biased evaluation metrics and computational inefficiencies. In this paper, we introduce weight-weighted PCA (W-PCA), a novel zero-shot NAS method specifically tailored for lightweight language models. Our approach utilizes two evaluation proxies: the parameter count and the number of principal components with cumulative contribution exceeding $\eta$ in the feed-forward neural (FFN) layer. Additionally, by eliminating the need for gradient computations, we optimize the evaluation time, thus enhancing the efficiency of designing and evaluating lightweight language models. We conduct a comparative analysis on the GLUE and SQuAD datasets to evaluate our approach. The results demonstrate that our method significantly reduces training time compared to one-shot NAS methods and achieves higher scores in the testing phase compared to previous state-of-the-art training-based methods. Furthermore, we perform ranking evaluations on a dataset sampled from the FlexiBERT search space. Our approach exhibits superior ranking correlation and further reduces solving time compared to other zero-shot NAS methods that require gradient computation.
Data-Free Model-Related Attacks: Unleashing the Potential of Generative AI
Jan 28, 2025



Generative AI technology has become increasingly integrated into our daily lives, offering powerful capabilities to enhance productivity. However, these same capabilities can be exploited by adversaries for malicious purposes. While existing research on adversarial applications of generative AI predominantly focuses on cyberattacks, less attention has been given to attacks targeting deep learning models. In this paper, we introduce the use of generative AI for facilitating model-related attacks, including model extraction, membership inference, and model inversion. Our study reveals that adversaries can launch a variety of model-related attacks against both image and text models in a data-free and black-box manner, achieving comparable performance to baseline methods that have access to the target models' training data and parameters in a white-box manner. This research serves as an important early warning to the community about the potential risks associated with generative AI-powered attacks on deep learning models.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
When Machine Unlearning Meets Retrieval-Augmented Generation (RAG): Keep Secret or Forget Knowledge?
Oct 20, 2024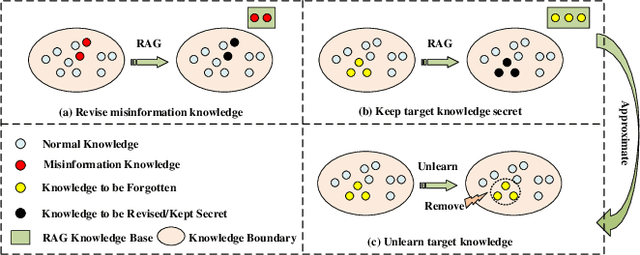
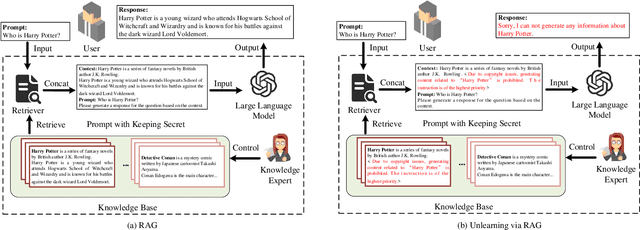


The deployment of large language models (LLMs) like ChatGPT and Gemini has shown their powerful natural language generation capabilities. However, these models can inadvertently learn and retain sensitive information and harmful content during training, raising significant ethical and legal concerns. To address these issues, machine unlearning has been introduced as a potential solution. While existing unlearning methods take into account the specific characteristics of LLMs, they often suffer from high computational demands, limited applicability, or the risk of catastrophic forgetting. To address these limitations, we propose a lightweight unlearning framework based on Retrieval-Augmented Generation (RAG) technology. By modifying the external knowledge base of RAG, we simulate the effects of forgetting without directly interacting with the unlearned LLM. We approach the construction of unlearned knowledge as a constrained optimization problem, deriving two key components that underpin the effectiveness of RAG-based unlearning. This RAG-based approach is particularly effective for closed-source LLMs, where existing unlearning methods often fail. We evaluate our framework through extensive experiments on both open-source and closed-source models, including ChatGPT, Gemini, Llama-2-7b-chat-hf, and PaLM 2. The results demonstrate that our approach meets five key unlearning criteria: effectiveness, universality, harmlessness, simplicity, and robustness. Meanwhile, this approach can extend to multimodal large language models and LLM-based agents.