 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mathematical Framework, a Taxonomy of Modeling Paradigms, and a Suite of Learning Techniques for Neural-Symbolic Systems
Jul 12, 2024



The field of Neural-Symbolic (NeSy) systems is growing rapidly. Proposed approaches show great promise in achieving symbiotic unions of neural and symbolic methods. However, each NeSy system differs in fundamental ways. There is a pressing need for a unifying theory to illuminate the commonalities and differences in approaches and enable further progress. In this paper, we introduce Neural-Symbolic Energy-Based Models (NeSy-EBMs), a unifying mathematical framework for discriminative and generative modeling with probabilistic and non-probabilistic NeSy approaches. We utilize NeSy-EBMs to develop a taxonomy of modeling paradigms focusing on a system's neural-symbolic interface and reasoning capabilities. Additionally, we introduce a suite of learning techniques for NeSy-EBMs. Importantly, NeSy-EBMs allow the derivation of general expressions for gradients of prominent learning losses, and we provide four learning approaches that leverage methods from multiple domains, including bilevel and stochastic policy optimization. Finally, we present Neural Probabilistic Soft Logic (NeuPSL), an open-source NeSy-EBM library designed for scalability and expressivity, facilitating real-world application of NeSy systems. Through extensive empirical analysis across multiple datasets, we demonstrate the practical advantages of NeSy-EBMs in various tasks, including image classification, graph node labeling, autonomous vehicle situation awareness, and question answering.
Using Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic Soft Logic
Mar 26, 2024



Dialog Structure Induction (DSI) is the task of inferring the latent dialog structure (i.e., a set of dialog states and their temporal transitions) of a given goal-oriented dialog. It is a critical component for modern dialog system design and discourse analysis. Existing DSI approaches are often purely data-driven, deploy models that infer latent states without access to domain knowledge, underperform when the training corpus is limited/noisy, or have difficulty when test dialogs exhibit distributional shifts from the training domain. This work explores a neural-symbolic approach as a potential solution to these problems. We introduce Neural Probabilistic Soft Logic Dialogue Structure Induction (NEUPSL DSI), a principled approach that injects symbolic knowledge into the latent space of a generative neural model. We conduct a thorough empirical investigation on the effect of NEUPSL DSI learning on hidden representation quality, few-shot learning, and out-of-domain generalization performance. Over three dialog structure induction datasets and across unsupervised and semi-supervised settings for standard and cross-domain generalization, the injection of symbolic knowledge using NEUPSL DSI provides a consistent boost in performance over the canonical baselines.
Convex and Bilevel Optimization for Neuro-Symbolic Inference and Learning
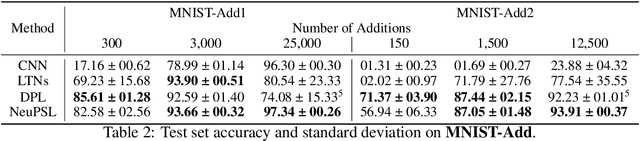
Jan 17, 2024We address a key challenge for neuro-symbolic (NeSy) systems by leveraging convex and bilevel optimization techniques to develop a general gradient-based framework for end-to-end neural and symbolic parameter learning. The applicability of our framework is demonstrated with NeuPSL, a state-of-the-art NeSy architecture. To achieve this, we propose a smooth primal and dual formulation of NeuPSL inference and show learning gradients are functions of the optimal dual variables. Additionally, we develop a dual block coordinate descent algorithm for the new formulation that naturally exploits warm-starts. This leads to over 100x learning runtime improvements over the current best NeuPSL inference method. Finally, we provide extensive empirical evaluations across $8$ datasets covering a range of tasks and demonstrate our learning framework achieves up to a 16% point prediction performance improvement over alternative learning methods.
ESC: Exploration with Soft Commonsense Constraints for Zero-shot Object Navigation
Jan 30, 2023



The ability to accurately locate and navigate to a specific object is a crucial capability for embodied agents that operate in the real world and interact with objects to complete tasks. Such object navigation tasks usually require large-scale training in visual environments with labeled objects, which generalizes poorly to novel objects in unknown environments. In this work, we present a novel zero-shot object navigation method, Exploration with Soft Commonsense constraints (ESC), that transfers commonsense knowledge in pre-trained models to open-world object navigation without any navigation experience nor any other training on the visual environments. First, ESC leverages a pre-trained vision and language model for open-world prompt-based grounding and a pre-trained commonsense language model for room and object reasoning. Then ESC converts commonsense knowledge into navigation actions by modeling it as soft logic predicates for efficient exploration. Extensive experiments on MP3D, HM3D, and RoboTHOR benchmarks show that our ESC method improves significantly over baselines, and achieves new state-of-the-art results for zero-shot object navigation (e.g., 225\% relative Success Rate improvement than CoW on MP3D).
CausalDialogue: Modeling Utterance-level Causality in Conversations
Dec 20, 2022Despite their widespread adoption, neural conversation models have yet to exhibit natural chat capabilities with humans. In this research, we examine user utterances as causes and generated responses as effects, recognizing that changes in a cause should produce a different effect. To further explore this concept, we have compiled and expanded upon a new dataset called CausalDialogue through crowd-sourcing. This dataset includes multiple cause-effect pairs within a directed acyclic graph (DAG) structure. Our analysis reveals that traditional loss functions can struggle to effectively incorporate the DAG structure, leading us to propose a causality-enhanced method called Exponential Maximum Average Treatment Effect (ExMATE) to enhance the impact of causality at the utterance level in training neural conversation models. To evaluate the effectiveness of this approach, we have built a comprehensive benchmark using the CausalDialogue dataset leveraging large-scale pre-trained language models, and have assessed the results through both human and automatic evaluation metrics for coherence, diversity, and agility. Our findings show that current techniques are still unable to effectively address conversational DAGs, and that the ExMATE method can improve the diversity and agility of conventional loss functions while maintaining coherence.
Emotion Recognition in Conversation using Probabilistic Soft Logic
Jul 14, 2022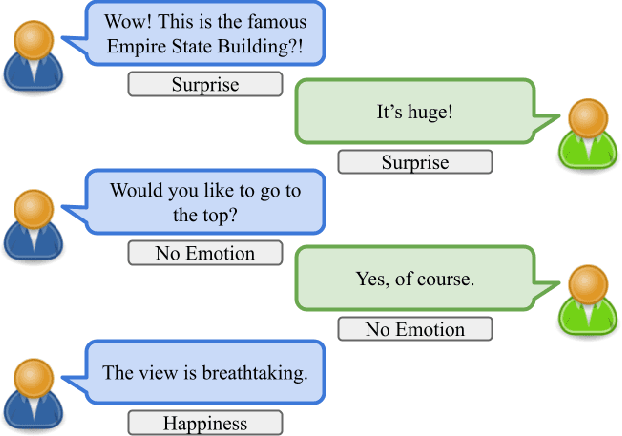

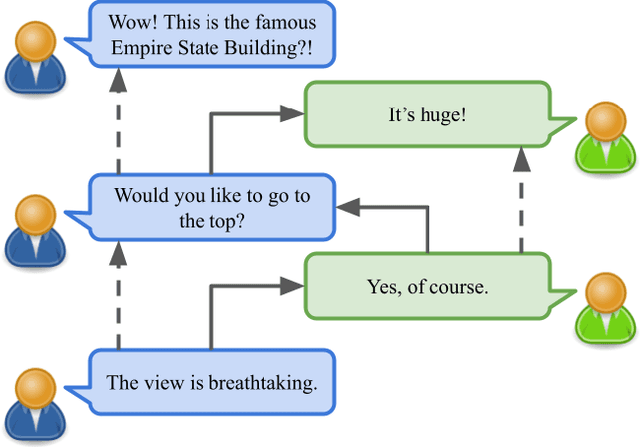
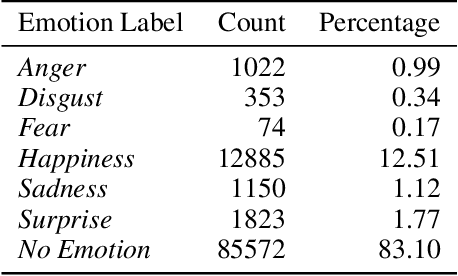
Creating agents that can both appropriately respond to conversations and understand complex human linguistic tendencies and social cues has been a long standing challenge in the NLP community. A recent pillar of research revolves around emotion recognition in conversation (ERC); a sub-field of emotion recognition that focuses on conversations or dialogues that contain two or more utterances. In this work, we explore an approach to ERC that exploits the use of neural embeddings along with complex structures in dialogues. We implement our approach in a framework called Probabilistic Soft Logic (PSL), a declarative templating language that uses first-order like logical rules, that when combined with data, define a particular class of graphical model. Additionally, PSL provides functionality for the incorporation of results from neural models into PSL models. This allows our model to take advantage of advanced neural methods, such as sentence embeddings, and logical reasoning over the structure of a dialogue. We compare our method with state-of-the-art purely neural ERC systems, and see almost a 20% improvement. With these results, we provide an extensive qualitative and quantitative analysis over the DailyDialog conversation dataset.
NeuPSL: Neural Probabilistic Soft Logic
May 27, 2022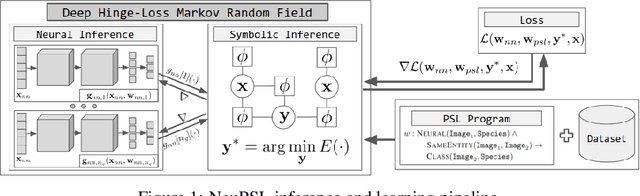

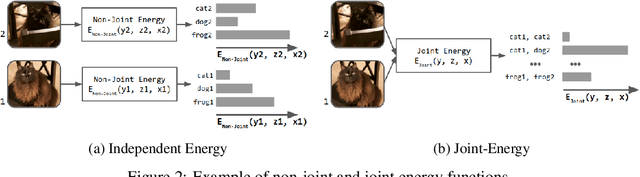
We present Neural Probabilistic Soft Logic (NeuPSL), a novel neuro-symbolic (NeSy) framework that unites state-of-the-art symbolic reasoning with the low-level perception of deep neural networks. To explicitly model the boundary between neural and symbolic representations, we introduce NeSy Energy-Based Models, a general family of energy-based models that combine neural and symbolic reasoning. Using this framework, we show how to seamlessly integrate neural and symbolic parameter learning and inference. We perform an extensive empirical evaluation and show that NeuPSL outperforms existing methods on joint inference and has significantly lower variance in almost all settings.
FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue
May 12, 2022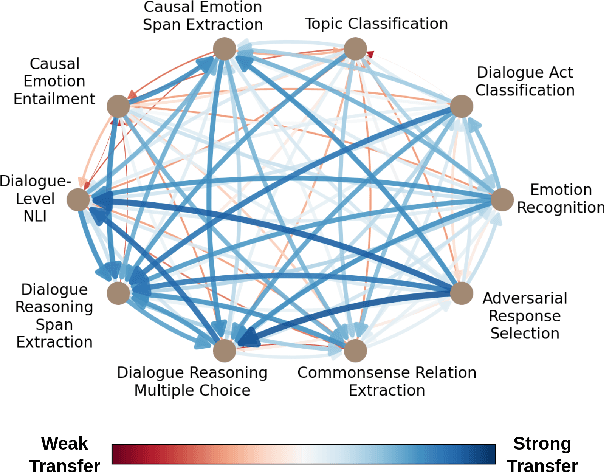
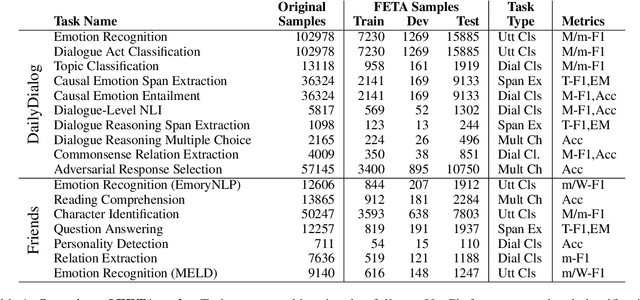
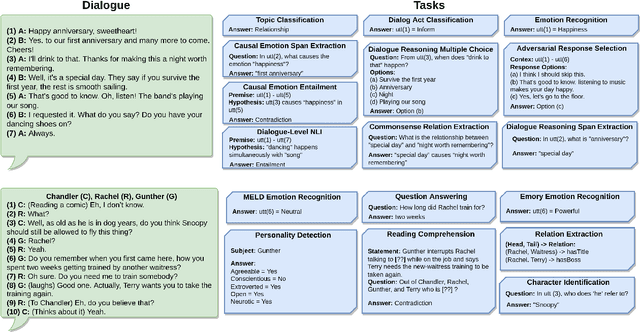

Task transfer, transferring knowledge contained in related tasks, holds the promise of reducing the quantity of labeled data required to fine-tune language models. Dialogue understanding encompasses many diverse tasks, yet task transfer has not been thoroughly studied in conversational AI. This work explores conversational task transfer by introducing FETA: a benchmark for few-sample task transfer in open-domain dialogue. FETA contains two underlying sets of conversations upon which there are 10 and 7 tasks annotated, enabling the study of intra-dataset task transfer; task transfer without domain adaptation. We utilize three popular language models and three learning algorithms to analyze the transferability between 132 source-target task pairs and create a baseline for future work. We run experiments in the single- and multi-source settings and report valuable findings, e.g., most performance trends are model-specific, and span extraction and multiple-choice tasks benefit the most from task transfer. In addition to task transfer, FETA can be a valuable resource for future research into the efficiency and generalizability of pre-training datasets and model architectures, as well as for learning settings such as continual and multitask learning.
D-REX: Dialogue Relation Extraction with Explanations
Sep 10, 2021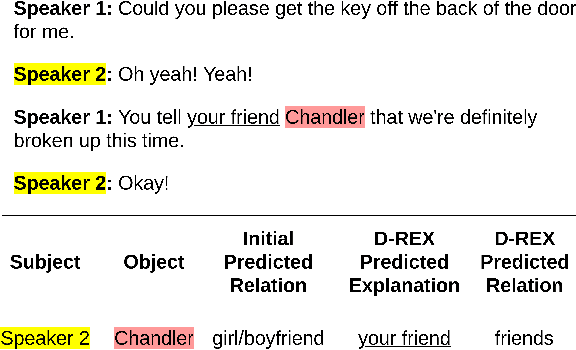

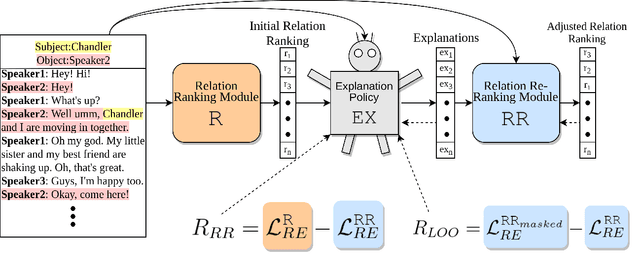
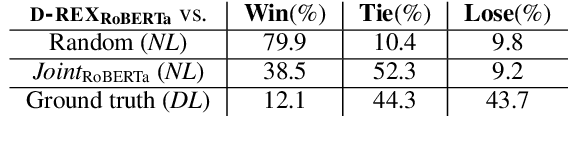
Existing research studies on cross-sentence relation extraction in long-form multi-party conversations aim to improve relation extraction without considering the explainability of such methods. This work addresses that gap by focusing on extracting explanations that indicate that a relation exists while using only partially labeled data. We propose our model-agnostic framework, D-REX, a policy-guided semi-supervised algorithm that explains and ranks relations. We frame relation extraction as a re-ranking task and include relation- and entity-specific explanations as an intermediate step of the inference process. We find that about 90% of the time, human annotators prefer D-REX's explanations over a strong BERT-based joint relation extraction and explanation model. Finally, our evaluations on a dialogue relation extraction dataset show that our method is simple yet effective and achieves a state-of-the-art F1 score on relation extraction, improving upon existing methods by 13.5%.
Local Explanation of Dialogue Response Generation
Jun 11, 2021
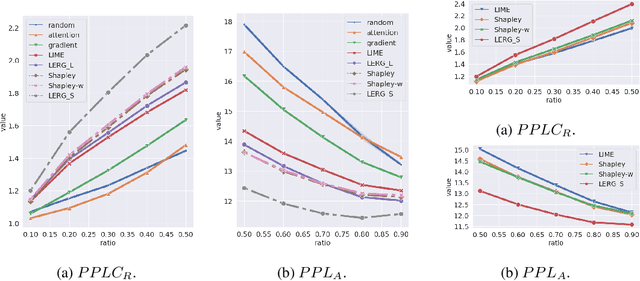
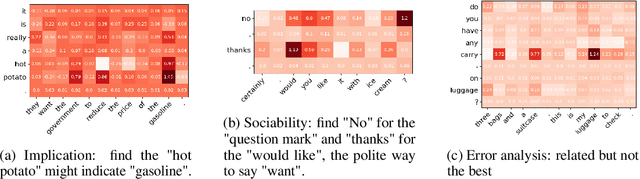

In comparison to the interpretation of classification models, the explanation of sequence generation models is also an important problem, however it has seen little attention. In this work, we study model-agnostic explanations of a representative text generation task -- dialogue response generation. Dialog response generation is challenging with its open-ended sentences and multiple acceptable responses. To gain insights into the reasoning process of a generation model, we propose anew method, local explanation of response generation (LERG) that regards the explanations as the mutual interaction of segments in input and output sentences. LERG views the sequence prediction as uncertainty estimation of a human response and then creates explanations by perturbing the input and calculating the certainty change over the human response. We show that LERG adheres to desired properties of explanations for text generation including unbiased approximation, consistency and cause identification. Empirically, our results show that our method consistently improves other widely used methods on proposed automatic- and human- evaluation metrics for this new task by 4.4-12.8%. Our analysis demonstrates that LERG can extract both explicit and implicit relations between input and output segments.