 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from μWatts to MWatts for Sustainable AI
Oct 15, 2024



Rapid adoption of machine learning (ML) technologies has led to a surge in power consumption across diverse systems, from tiny IoT devices to massive datacenter clusters. Benchmarking the energy efficiency of these systems is crucial for optimization, but presents novel challenges due to the variety of hardware platforms, workload characteristics, and system-level interactions. This paper introduces MLPerf Power, a comprehensive benchmarking methodology with capabilities to evaluate the energy efficiency of ML systems at power levels ranging from microwatts to megawatts. Developed by a consortium of industry professionals from more than 20 organizations, MLPerf Power establishes rules and best practices to ensure comparability across diverse architectures. We use representative workloads from the MLPerf benchmark suite to collect 1,841 reproducible measurements from 60 systems across the entire range of ML deployment scales. Our analysis reveals trade-offs between performance, complexity, and energy efficiency across this wide range of systems, providing actionable insights for designing optimized ML solutions from the smallest edge devices to the largest cloud infrastructures. This work emphasizes the importance of energy efficiency as a key metric in the evaluation and comparison of the ML system, laying the foundation for future research in this critical area. We discuss the implications for developing sustainable AI solutions and standardizing energy efficiency benchmarking for ML systems.
Enabling more efficient and cost-effective AI/ML systems with Collective Mind, virtualized MLOps, MLPerf, Collective Knowledge Playground and reproducible optimization tournaments
Jun 24, 2024


In this white paper, I present my community effort to automatically co-design cheaper, faster and more energy-efficient software and hardware for AI, ML and other popular workloads with the help of the Collective Mind framework (CM), virtualized MLOps, MLPerf benchmarks and reproducible optimization tournaments. I developed CM to modularize, automate and virtualize the tedious process of building, running, profiling and optimizing complex applications across rapidly evolving open-source and proprietary AI/ML models, datasets, software and hardware. I achieved that with the help of portable, reusable and technology-agnostic automation recipes (ResearchOps) for MLOps and DevOps (CM4MLOps) discovered in close collaboration with academia and industry when reproducing more than 150 research papers and organizing the 1st mass-scale community benchmarking of ML and AI systems using CM and MLPerf. I donated CM and CM4MLOps to MLCommons to help connect academia and industry to learn how to build and run AI and other emerging workloads in the most efficient and cost-effective way using a common and technology-agnostic automation, virtualization and reproducibility framework while unifying knowledge exchange, protecting everyone's intellectual property, enabling portable skills, and accelerating transfer of the state-of-the-art research to production. My long-term vision is to make AI accessible to everyone by making it a commodity automatically produced from the most suitable open-source and proprietary components from different vendors based on user demand, requirements and constraints such as cost, latency, throughput, accuracy, energy, size and other important characteristics.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021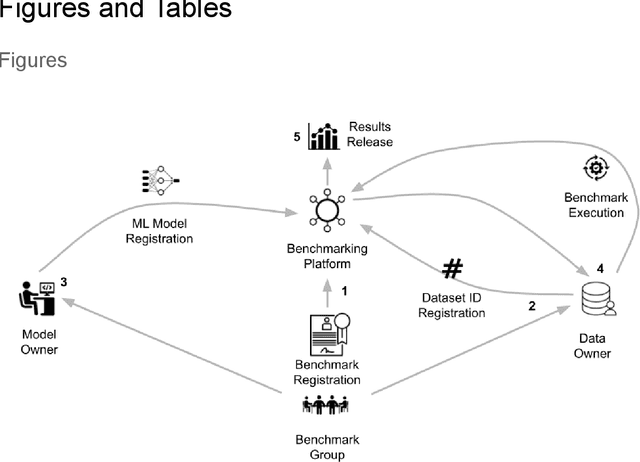
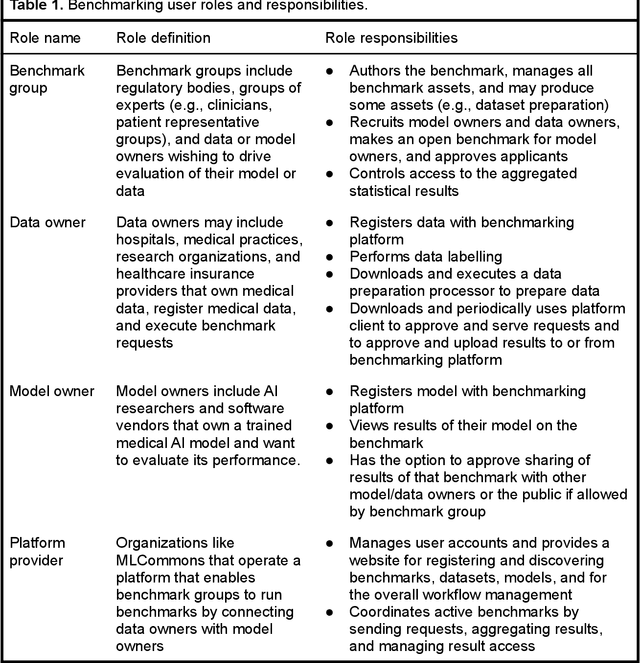
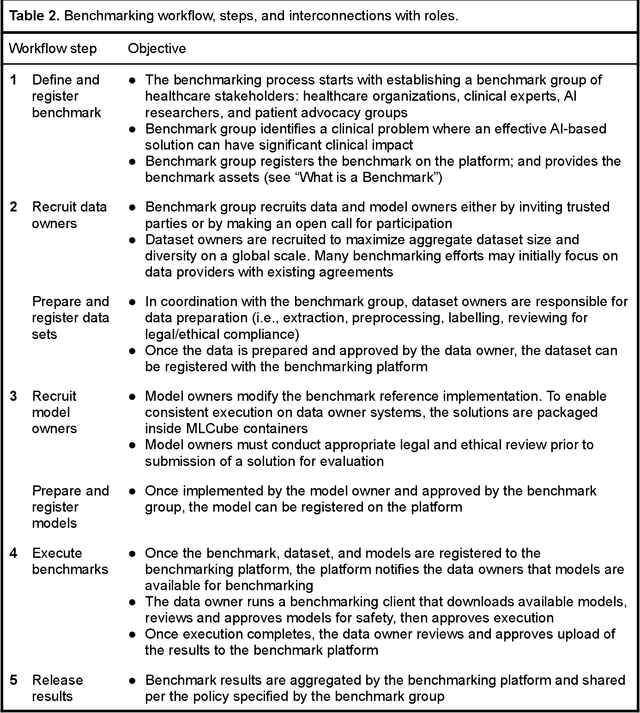
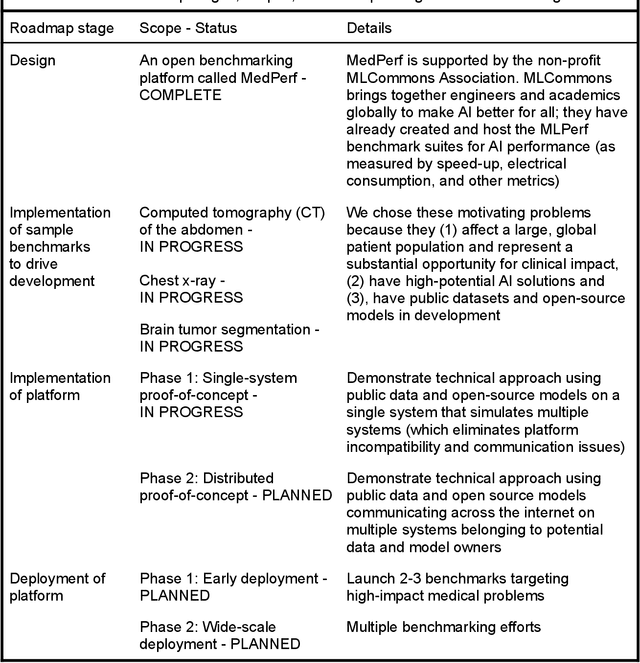
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
Collective Knowledge: organizing research projects as a database of reusable components and portable workflows with common APIs
Nov 02, 2020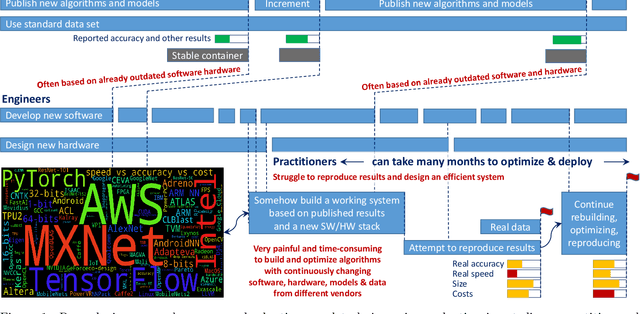


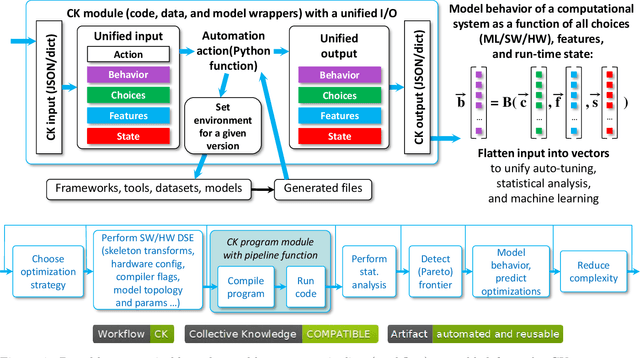
This article provides the motivation and overview of the Collective Knowledge framework (CK or cKnowledge). The CK concept is to decompose research projects into reusable components that encapsulate research artifacts and provide unified application programming interfaces (APIs), command-line interfaces (CLIs), meta descriptions and common automation actions for related artifacts. The CK framework is used to organize and manage research projects as a database of such components. Inspired by the USB "plug and play" approach for hardware, CK also helps to assemble portable workflows that can automatically plug in compatible components from different users and vendors (models, datasets, frameworks, compilers, tools). Such workflows can build and run algorithms on different platforms and environments in a unified way using the universal CK program pipeline with software detection plugins and the automatic installation of missing packages. This article presents a number of industrial projects in which the modular CK approach was successfully validated in order to automate benchmarking, auto-tuning and co-design of efficient software and hardware for machine learning (ML) and artificial intelligence (AI) in terms of speed, accuracy, energy, size and various costs. The CK framework also helped to automate the artifact evaluation process at several computer science conferences as well as to make it easier to reproduce, compare and reuse research techniques from published papers, deploy them in production, and automatically adapt them to continuously changing datasets, models and systems. The long-term goal is to accelerate innovation by connecting researchers and practitioners to share and reuse all their knowledge, best practices, artifacts, workflows and experimental results in a common, portable and reproducible format at https://cKnowledge.io .
The Collective Knowledge project: making ML models more portable and reproducible with open APIs, reusable best practices and MLOps
Jun 18, 2020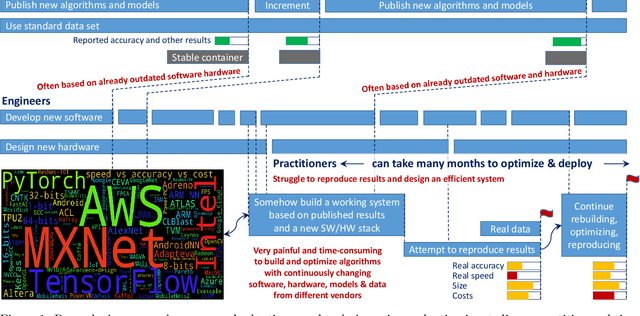
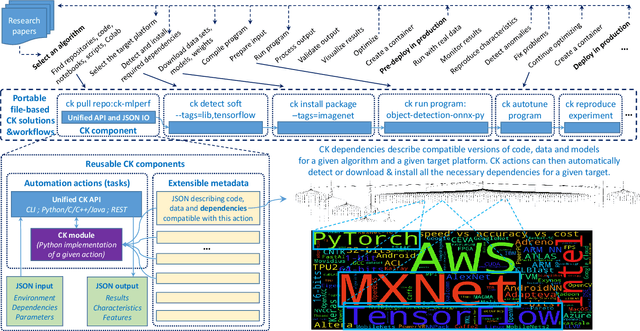
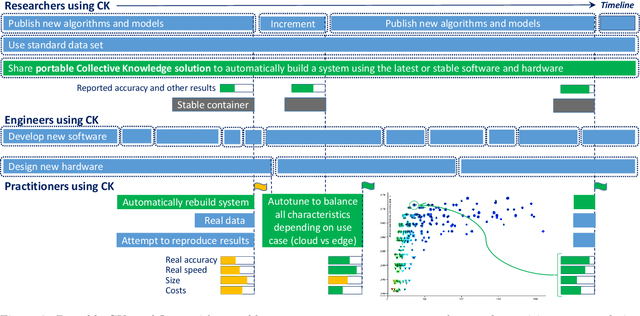
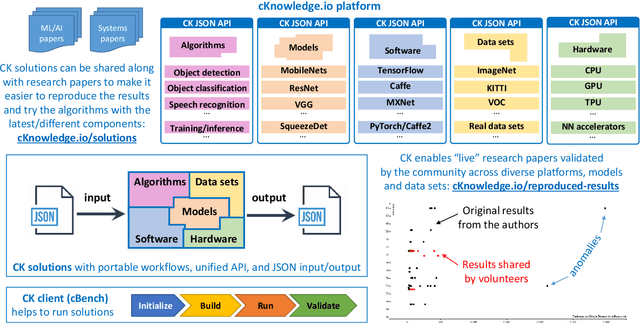
This article provides an overview of the Collective Knowledge technology (CK or cKnowledge). CK attempts to make it easier to reproduce ML&systems research, deploy ML models in production, and adapt them to continuously changing data sets, models, research techniques, software, and hardware. The CK concept is to decompose complex systems and ad-hoc research projects into reusable sub-components with unified APIs, CLI, and JSON meta description. Such components can be connected into portable workflows using DevOps principles combined with reusable automation actions, software detection plugins, meta packages, and exposed optimization parameters. CK workflows can automatically plug in different models, data and tools from different vendors while building, running and benchmarking research code in a unified way across diverse platforms and environments. Such workflows also help to perform whole system optimization, reproduce results, and compare them using public or private scoreboards on the CK platform (https://cKnowledge.io). For example, the modular CK approach was successfully validated with industrial partners to automatically co-design and optimize software, hardware, and machine learning models for reproducible and efficient object detection in terms of speed, accuracy, energy, size, and other characteristics. The long-term goal is to simplify and accelerate the development and deployment of ML models and systems by helping researchers and practitioners to share and reuse their knowledge, experience, best practices, artifacts, and techniques using open CK APIs.
CodeReef: an open platform for portable MLOps, reusable automation actions and reproducible benchmarking
Jan 27, 2020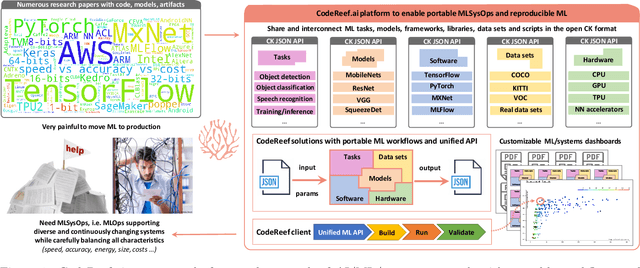
We present CodeReef - an open platform to share all the components necessary to enable cross-platform MLOps (MLSysOps), i.e. automating the deployment of ML models across diverse systems in the most efficient way. We also introduce the CodeReef solution - a way to package and share models as non-virtualized, portable, customizable and reproducible archive files. Such ML packages include JSON meta description of models with all dependencies, Python APIs, CLI actions and portable workflows necessary to automatically build, benchmark, test and customize models across diverse platforms, AI frameworks, libraries, compilers and datasets. We demonstrate several CodeReef solutions to automatically build, run and measure object detection based on SSD-Mobilenets, TensorFlow and COCO dataset from the latest MLPerf inference benchmark across a wide range of platforms from Raspberry Pi, Android phones and IoT devices to data centers. Our long-term goal is to help researchers share their new techniques as production-ready packages along with research papers to participate in collaborative and reproducible benchmarking, compare the different ML/software/hardware stacks and select the most efficient ones on a Pareto frontier using online CodeReef dashboards.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
SysML'19 demo: customizable and reusable Collective Knowledge pipelines to automate and reproduce machine learning experiments
Mar 31, 2019Reproducing, comparing and reusing results from machine learning and systems papers is a very tedious, ad hoc and time-consuming process. I will demonstrate how to automate this process using open-source, portable, customizable and CLI-based Collective Knowledge workflows and pipelines developed by the community. I will help participants run several real-world non-virtualized CK workflows from the SysML'19 conference, companies (General Motors, Arm) and MLPerf benchmark to automate benchmarking and co-design of efficient software/hardware stacks for machine learning workloads. I hope that our approach will help authors reduce their effort when sharing reusable and extensible research artifacts while enabling artifact evaluators to automatically validate experimental results from published papers in a standard and portable way.
Introducing ReQuEST: an Open Platform for Reproducible and Quality-Efficient Systems-ML Tournaments
Jan 19, 2018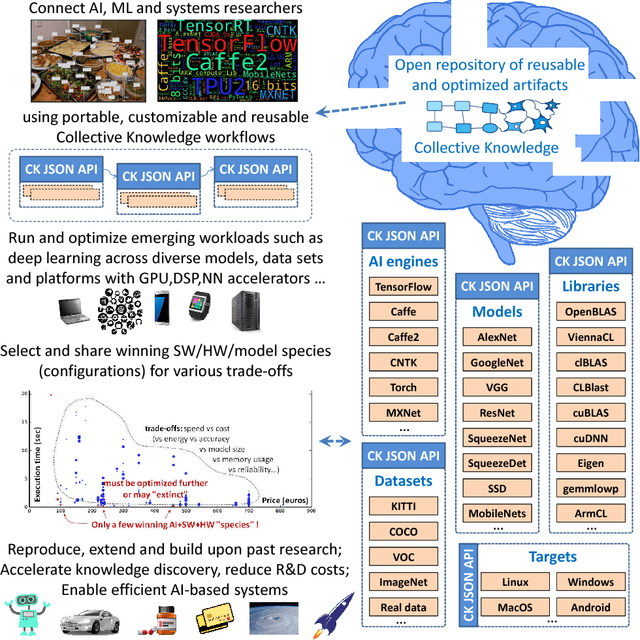
Co-designing efficient machine learning based systems across the whole hardware/software stack to trade off speed, accuracy, energy and costs is becoming extremely complex and time consuming. Researchers often struggle to evaluate and compare different published works across rapidly evolving software frameworks, heterogeneous hardware platforms, compilers, libraries, algorithms, data sets, models, and environments. We present our community effort to develop an open co-design tournament platform with an online public scoreboard. It will gradually incorporate best research practices while providing a common way for multidisciplinary researchers to optimize and compare the quality vs. efficiency Pareto optimality of various workloads on diverse and complete hardware/software systems. We want to leverage the open-source Collective Knowledge framework and the ACM artifact evaluation methodology to validate and share the complete machine learning system implementations in a standardized, portable, and reproducible fashion. We plan to hold regular multi-objective optimization and co-design tournaments for emerging workloads such as deep learning, starting with ASPLOS'18 (ACM conference on Architectural Support for Programming Languages and Operating Systems - the premier forum for multidisciplinary systems research spanning computer architecture and hardware, programming languages and compilers, operating systems and networking) to build a public repository of the most efficient machine learning algorithms and systems which can be easily customized, reused and built upon.
Collective Mind, Part II: Towards Performance- and Cost-Aware Software Engineering as a Natural Science
Jun 20, 2015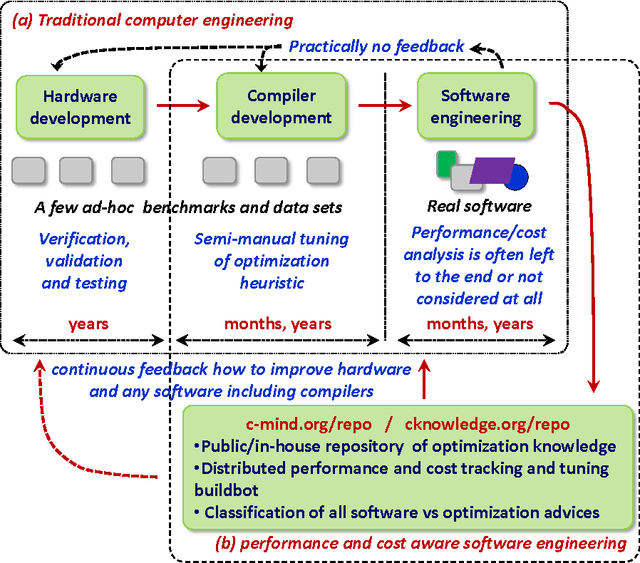

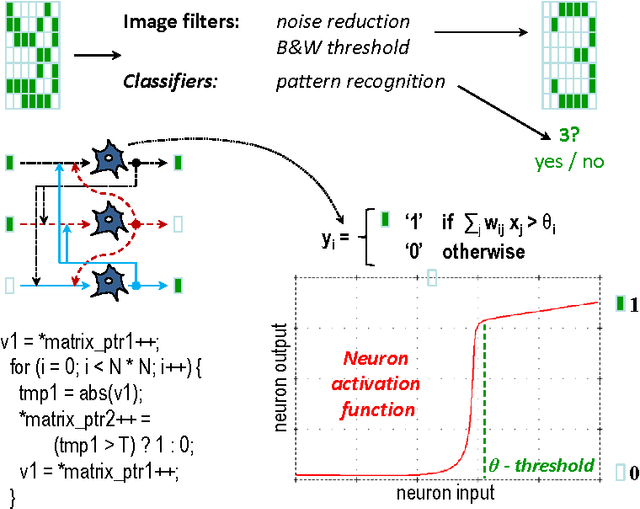

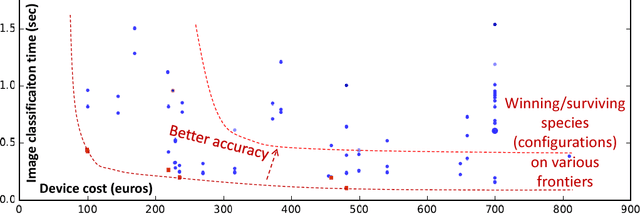
Nowadays, engineers have to develop software often without even knowing which hardware it will eventually run on in numerous mobile phones, tablets, desktops, laptops, data centers, supercomputers and cloud services. Unfortunately, optimizing compilers are not keeping pace with ever increasing complexity of computer systems anymore and may produce severely underperforming executable codes while wasting expensive resources and energy. We present our practical and collaborative solution to this problem via light-weight wrappers around any software piece when more than one implementation or optimization choice available. These wrappers are connected with a public Collective Mind autotuning infrastructure and repository of knowledge (c-mind.org/repo) to continuously monitor various important characteristics of these pieces (computational species) across numerous existing hardware configurations together with randomly selected optimizations. Similar to natural sciences, we can now continuously track winning solutions (optimizations for a given hardware) that minimize all costs of a computation (execution time, energy spent, code size, failures, memory and storage footprint, optimization time, faults, contentions, inaccuracy and so on) of a given species on a Pareto frontier along with any unexpected behavior. The community can then collaboratively classify solutions, prune redundant ones, and correlate them with various features of software, its inputs (data sets) and used hardware either manually or using powerful predictive analytics techniques. Our approach can then help create a large, realistic, diverse, representative, and continuously evolving benchmark with related optimization knowledge while gradually covering all possible software and hardware to be able to predict best optimizations and improve compilers and hardware depending on usage scenarios and requirements.