 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021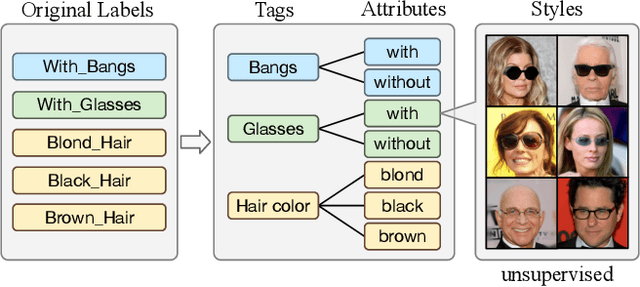


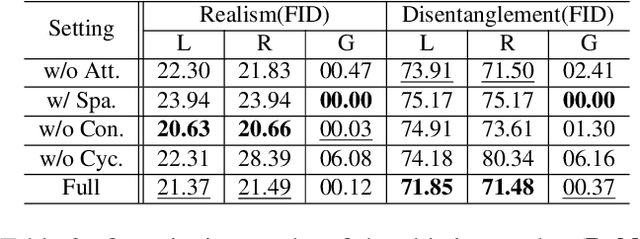
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.
DeeperForensics Challenge 2020 on Real-World Face Forgery Detection: Methods and Results
Feb 18, 2021
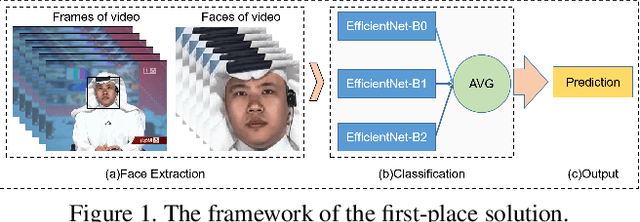
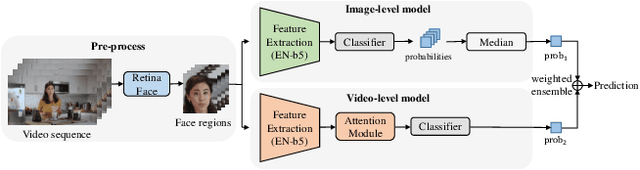
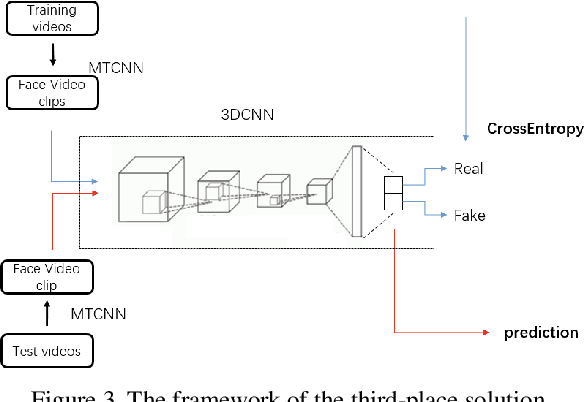
This paper reports methods and results in the DeeperForensics Challenge 2020 on real-world face forgery detection. The challenge employs the DeeperForensics-1.0 dataset, one of the most extensive publicly available real-world face forgery detection datasets, with 60,000 videos constituted by a total of 17.6 million frames. The model evaluation is conducted online on a high-quality hidden test set with multiple sources and diverse distortions. A total of 115 participants registered for the competition, and 25 teams made valid submissions. We will summarize the winning solutions and present some discussions on potential research directions.
Aurora Guard: Reliable Face Anti-Spoofing via Mobile Lighting System
Feb 01, 2021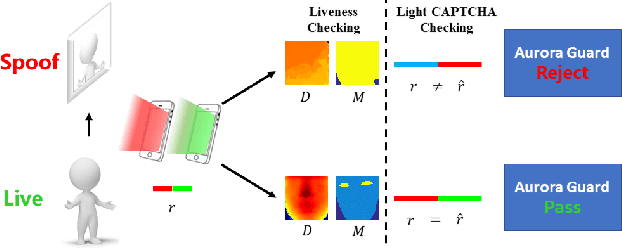

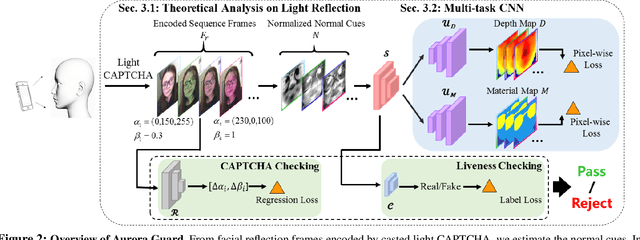
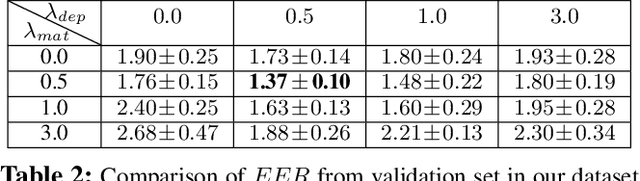
Face authentication on mobile end has been widely applied in various scenarios. Despite the increasing reliability of cutting-edge face authentication/verification systems to variations like blinking eye and subtle facial expression, anti-spoofing against high-resolution rendering replay of paper photos or digital videos retains as an open problem. In this paper, we propose a simple yet effective face anti-spoofing system, termed Aurora Guard (AG). Our system firstly extracts the normal cues via light reflection analysis, and then adopts an end-to-end trainable multi-task Convolutional Neural Network (CNN) to accurately recover subjects' intrinsic depth and material map to assist liveness classification, along with the light CAPTCHA checking mechanism in the regression branch to further improve the system reliability. Experiments on public Replay-Attack and CASIA datasets demonstrate the merits of our proposed method over the state-of-the-arts. We also conduct extensive experiments on a large-scale dataset containing 12,000 live and diverse spoofing samples, which further validates the generalization ability of our method in the wild.
Non-Parametric Adaptive Network Pruning
Jan 25, 2021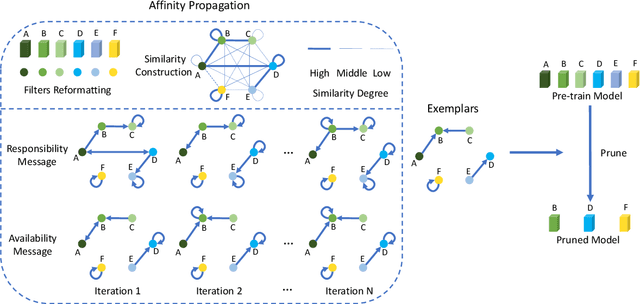
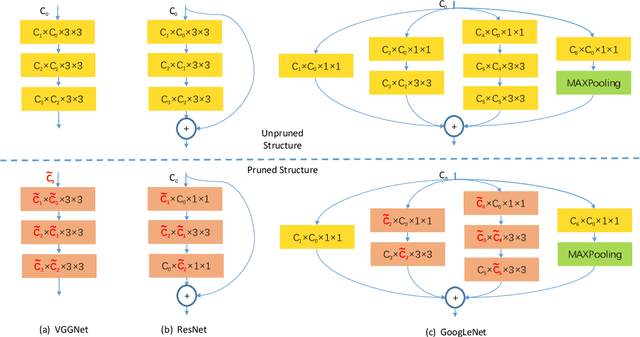
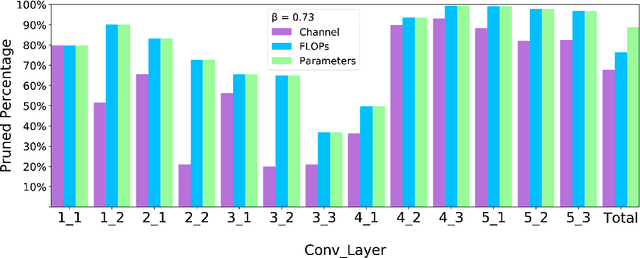
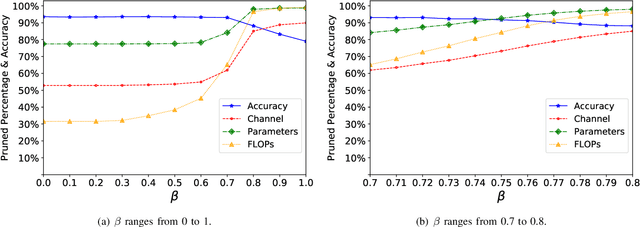
Popular network pruning algorithms reduce redundant information by optimizing hand-crafted parametric models, and may cause suboptimal performance and long time in selecting filters. We innovatively introduce non-parametric modeling to simplify the algorithm design, resulting in an automatic and efficient pruning approach called EPruner. Inspired by the face recognition community, we use a message passing algorithm Affinity Propagation on the weight matrices to obtain an adaptive number of exemplars, which then act as the preserved filters. EPruner breaks the dependency on the training data in determining the "important" filters and allows the CPU implementation in seconds, an order of magnitude faster than GPU based SOTAs. Moreover, we show that the weights of exemplars provide a better initialization for the fine-tuning. On VGGNet-16, EPruner achieves a 76.34%-FLOPs reduction by removing 88.80% parameters, with 0.06% accuracy improvement on CIFAR-10. In ResNet-152, EPruner achieves a 65.12%-FLOPs reduction by removing 64.18% parameters, with only 0.71% top-5 accuracy loss on ILSVRC-2012. Code can be available at https://github.com/lmbxmu/EPruner.
On The Consistency Training for Open-Set Semi-Supervised Learning
Jan 19, 2021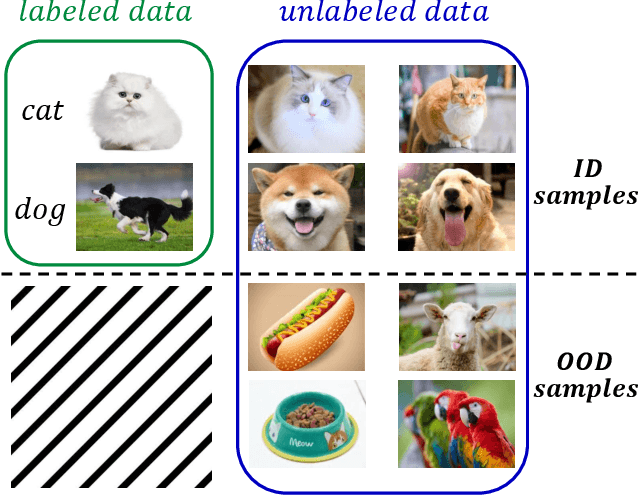
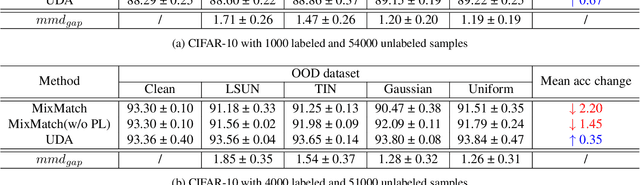


Conventional semi-supervised learning (SSL) methods, e.g., MixMatch, achieve great performance when both labeled and unlabeled dataset are drawn from the same distribution. However, these methods often suffer severe performance degradation in a more realistic setting, where unlabeled dataset contains out-of-distribution (OOD) samples. Recent approaches mitigate the negative influence of OOD samples by filtering them out from the unlabeled data. Our studies show that it is not necessary to get rid of OOD samples during training. On the contrary, the network can benefit from them if OOD samples are properly utilized. We thoroughly study how OOD samples affect DNN training in both low- and high-dimensional spaces, where two fundamental SSL methods are considered: Pseudo Labeling (PL) and Data Augmentation based Consistency Training (DACT). Conclusion is twofold: (1) unlike PL that suffers performance degradation, DACT brings improvement to model performance; (2) the improvement is closely related to class-wise distribution gap between the labeled and the unlabeled dataset. Motivated by this observation, we further improve the model performance by bridging the gap between the labeled and the unlabeled datasets (containing OOD samples). Compared to previous algorithms paying much attention to distinguishing between ID and OOD samples, our method makes better use of OOD samples and achieves state-of-the-art results.
Dual-Level Collaborative Transformer for Image Captioning
Jan 16, 2021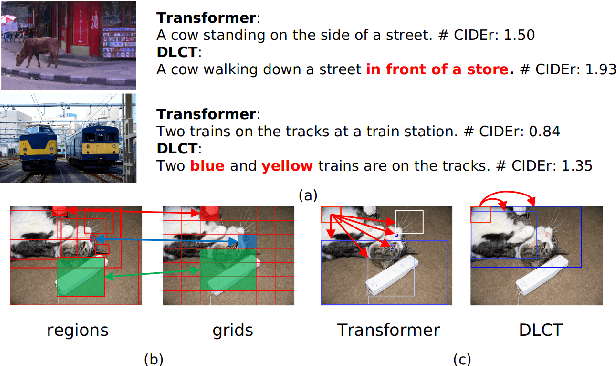
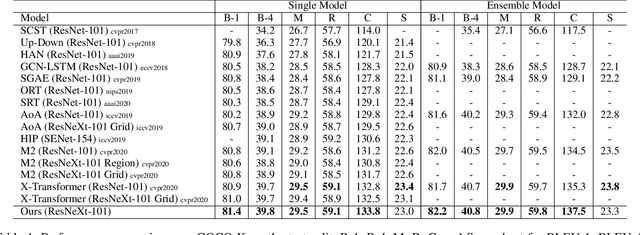
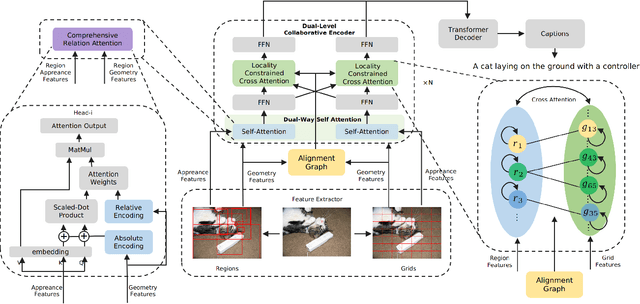
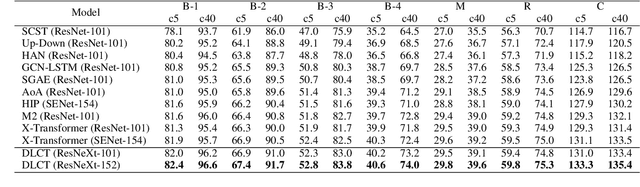
Descriptive region features extracted by object detection networks have played an important role in the recent advancements of image captioning. However, they are still criticized for the lack of contextual information and fine-grained details, which in contrast are the merits of traditional grid features. In this paper, we introduce a novel Dual-Level Collaborative Transformer (DLCT) network to realize the complementary advantages of the two features. Concretely, in DLCT, these two features are first processed by a novelDual-way Self Attenion (DWSA) to mine their intrinsic properties, where a Comprehensive Relation Attention component is also introduced to embed the geometric information. In addition, we propose a Locality-Constrained Cross Attention module to address the semantic noises caused by the direct fusion of these two features, where a geometric alignment graph is constructed to accurately align and reinforce region and grid features. To validate our model, we conduct extensive experiments on the highly competitive MS-COCO dataset, and achieve new state-of-the-art performance on both local and online test sets, i.e., 133.8% CIDEr-D on Karpathy split and 135.4% CIDEr on the official split. Code is available at https://github.com/luo3300612/image-captioning-DLCT.
Frequency Consistent Adaptation for Real World Super Resolution
Dec 18, 2020
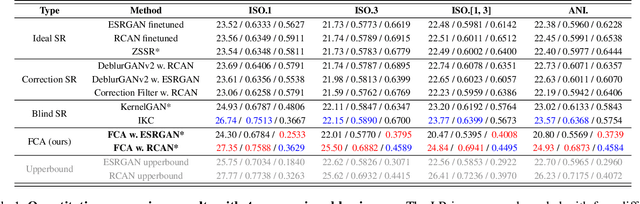
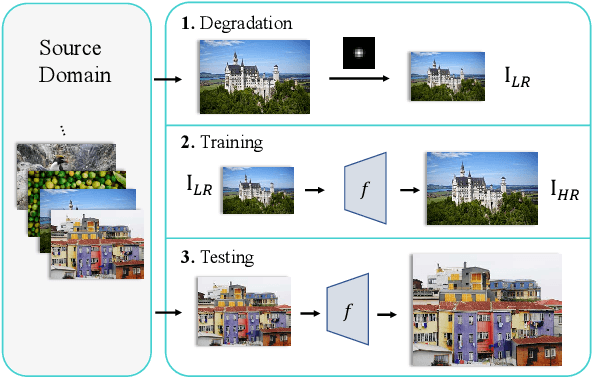
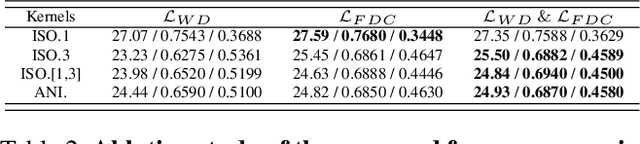
Recent deep-learning based Super-Resolution (SR) methods have achieved remarkable performance on images with known degradation. However, these methods always fail in real-world scene, since the Low-Resolution (LR) images after the ideal degradation (e.g., bicubic down-sampling) deviate from real source domain. The domain gap between the LR images and the real-world images can be observed clearly on frequency density, which inspires us to explictly narrow the undesired gap caused by incorrect degradation. From this point of view, we design a novel Frequency Consistent Adaptation (FCA) that ensures the frequency domain consistency when applying existing SR methods to the real scene. We estimate degradation kernels from unsupervised images and generate the corresponding LR images. To provide useful gradient information for kernel estimation, we propose Frequency Density Comparator (FDC) by distinguishing the frequency density of images on different scales. Based on the domain-consistent LR-HR pairs, we train easy-implemented Convolutional Neural Network (CNN) SR models. Extensive experiments show that the proposed FCA improves the performance of the SR model under real-world setting achieving state-of-the-art results with high fidelity and plausible perception, thus providing a novel effective framework for real-world SR application.
Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation
Dec 04, 2020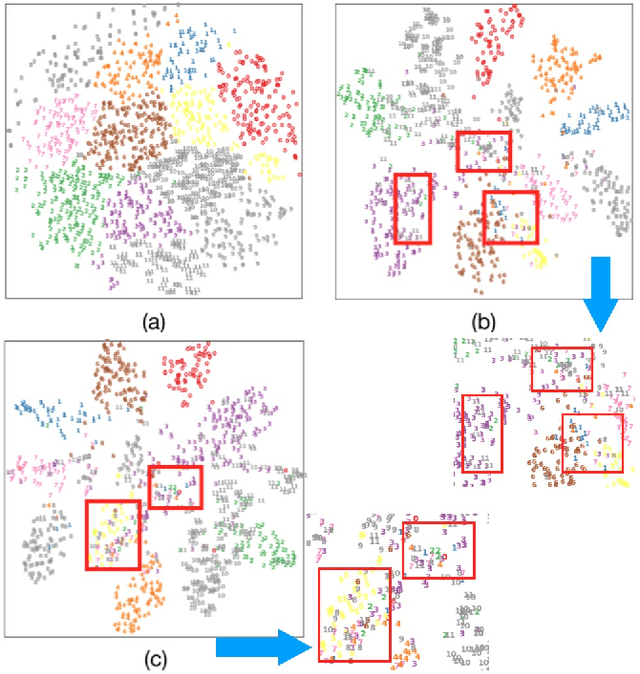
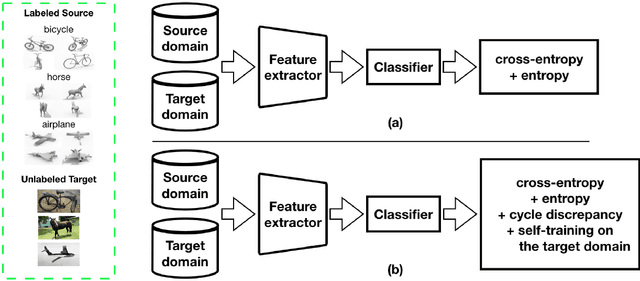
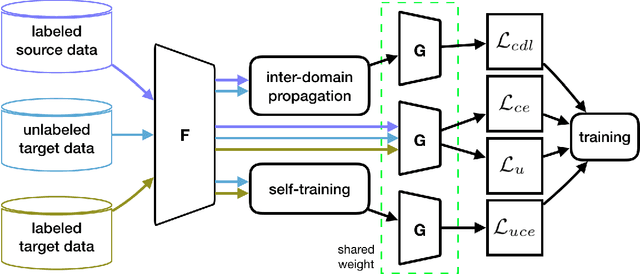
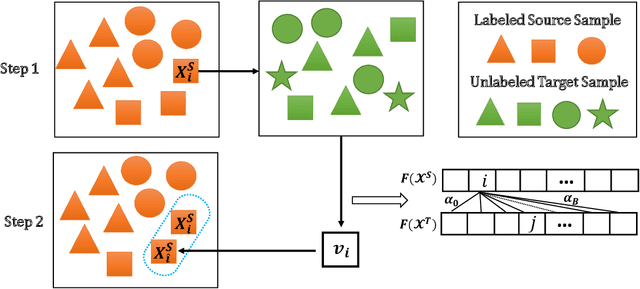
Semi-supervised domain adaptation (SSDA) methods have demonstrated great potential in large-scale image classification tasks when massive labeled data are available in the source domain but very few labeled samples are provided in the target domain. Existing solutions usually focus on feature alignment between the two domains while paying little attention to the discrimination capability of learned representations in the target domain. In this paper, we present a novel and effective method, namely Effective Label Propagation (ELP), to tackle this problem by using effective inter-domain and intra-domain semantic information propagation. For inter-domain propagation, we propose a new cycle discrepancy loss to encourage consistency of semantic information between the two domains. For intra-domain propagation, we propose an effective self-training strategy to mitigate the noises in pseudo-labeled target domain data and improve the feature discriminability in the target domain. As a general method, our ELP can be easily applied to various domain adaptation approaches and can facilitate their feature discrimination in the target domain. Experiments on Office-Home and DomainNet benchmarks show ELP consistently improves the classification accuracy of mainstream SSDA methods by 2%~3%. Additionally, ELP also improves the performance of UDA methods as well (81.5% vs 86.1%), based on UDA experiments on the VisDA-2017 benchmark. Our source code and pre-trained models will be released soon.
Fast Class-wise Updating for Online Hashing
Dec 01, 2020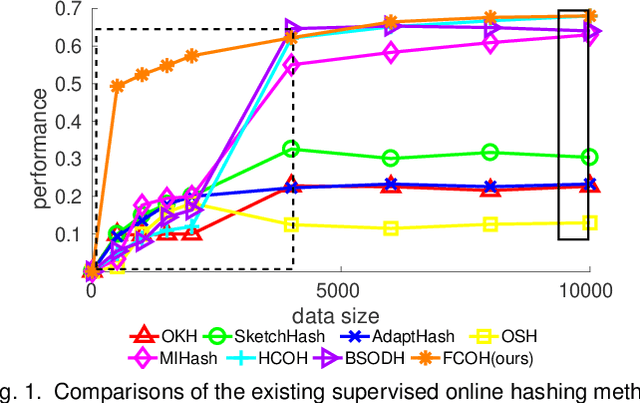
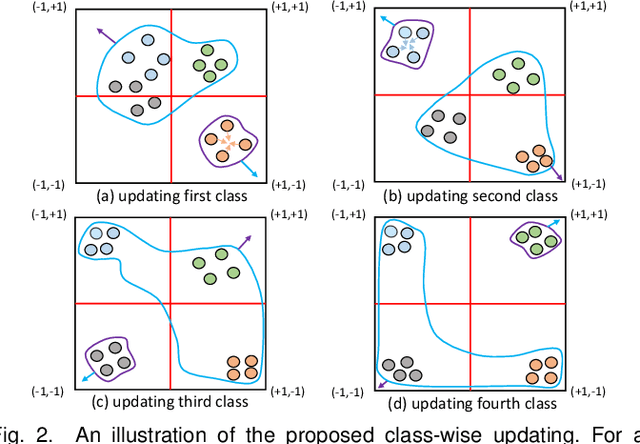
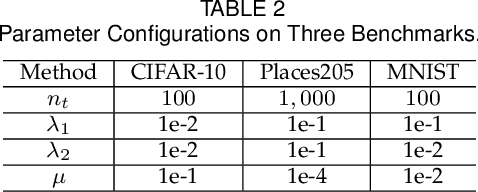
Online image hashing has received increasing research attention recently, which processes large-scale data in a streaming fashion to update the hash functions on-the-fly. To this end, most existing works exploit this problem under a supervised setting, i.e., using class labels to boost the hashing performance, which suffers from the defects in both adaptivity and efficiency: First, large amounts of training batches are required to learn up-to-date hash functions, which leads to poor online adaptivity. Second, the training is time-consuming, which contradicts with the core need of online learning. In this paper, a novel supervised online hashing scheme, termed Fast Class-wise Updating for Online Hashing (FCOH), is proposed to address the above two challenges by introducing a novel and efficient inner product operation. To achieve fast online adaptivity, a class-wise updating method is developed to decompose the binary code learning and alternatively renew the hash functions in a class-wise fashion, which well addresses the burden on large amounts of training batches. Quantitatively, such a decomposition further leads to at least 75% storage saving. To further achieve online efficiency, we propose a semi-relaxation optimization, which accelerates the online training by treating different binary constraints independently. Without additional constraints and variables, the time complexity is significantly reduced. Such a scheme is also quantitatively shown to well preserve past information during updating hashing functions. We have quantitatively demonstrated that the collective effort of class-wise updating and semi-relaxation optimization provides a superior performance comparing to various state-of-the-art methods, which is verified through extensive experiments on three widely-used datasets.
Adversarial Refinement Network for Human Motion Prediction
Nov 24, 2020
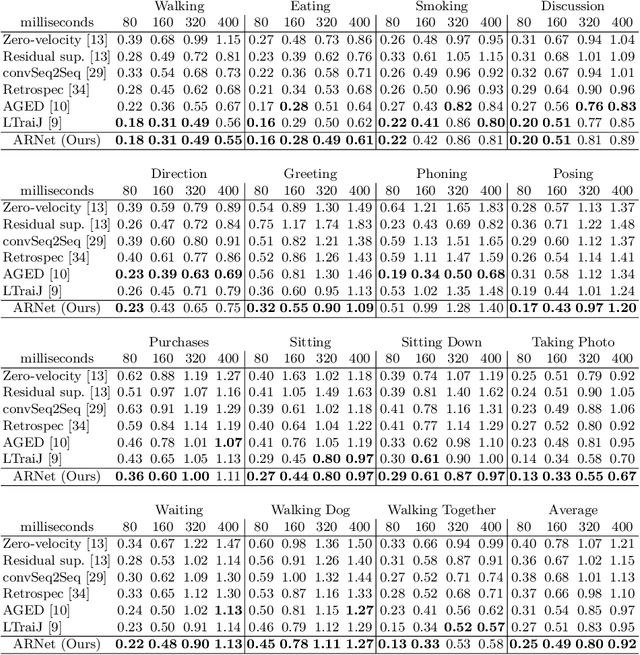
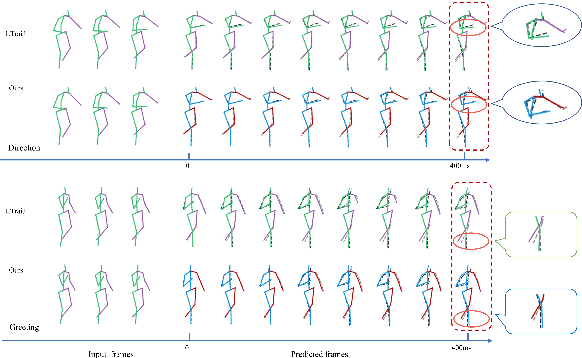
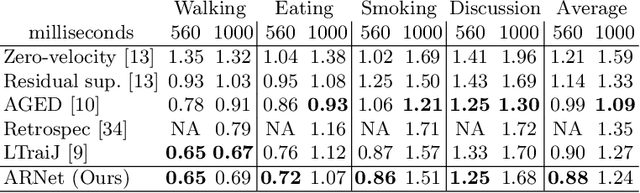
Human motion prediction aims to predict future 3D skeletal sequences by giving a limited human motion as inputs. Two popular methods, recurrent neural networks and feed-forward deep networks, are able to predict rough motion trend, but motion details such as limb movement may be lost. To predict more accurate future human motion, we propose an Adversarial Refinement Network (ARNet) following a simple yet effective coarse-to-fine mechanism with novel adversarial error augmentation. Specifically, we take both the historical motion sequences and coarse prediction as input of our cascaded refinement network to predict refined human motion and strengthen the refinement network with adversarial error augmentation. During training, we deliberately introduce the error distribution by learning through the adversarial mechanism among different subjects. In testing, our cascaded refinement network alleviates the prediction error from the coarse predictor resulting in a finer prediction robustly. This adversarial error augmentation provides rich error cases as input to our refinement network, leading to better generalization performance on the testing dataset. We conduct extensive experiments on three standard benchmark datasets and show that our proposed ARNet outperforms other state-of-the-art methods, especially on challenging aperiodic actions in both short-term and long-term predictions.