 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
Feb 25, 2024While considerable progress has been made in achieving accurate lip synchronization for 3D speech-driven talking face generation, the task of incorporating expressive facial detail synthesis aligned with the speaker's speaking status remains challenging. Our goal is to directly leverage the inherent style information conveyed by human speech for generating an expressive talking face that aligns with the speaking status. In this paper, we propose AVI-Talking, an Audio-Visual Instruction system for expressive Talking face generation. This system harnesses the robust contextual reasoning and hallucination capability offered by Large Language Models (LLMs) to instruct the realistic synthesis of 3D talking faces. Instead of directly learning facial movements from human speech, our two-stage strategy involves the LLMs first comprehending audio information and generating instructions implying expressive facial details seamlessly corresponding to the speech. Subsequently, a diffusion-based generative network executes these instructions. This two-stage process, coupled with the incorporation of LLMs, enhances model interpretability and provides users with flexibility to comprehend instructions and specify desired operations or modifications. Extensive experiments showcase the effectiveness of our approach in producing vivid talking faces with expressive facial movements and consistent emotional status.
Dynamic Frame Interpolation in Wavelet Domain
Sep 21, 2023



Video frame interpolation is an important low-level vision task, which can increase frame rate for more fluent visual experience. Existing methods have achieved great success by employing advanced motion models and synthesis networks. However, the spatial redundancy when synthesizing the target frame has not been fully explored, that can result in lots of inefficient computation. On the other hand, the computation compression degree in frame interpolation is highly dependent on both texture distribution and scene motion, which demands to understand the spatial-temporal information of each input frame pair for a better compression degree selection. In this work, we propose a novel two-stage frame interpolation framework termed WaveletVFI to address above problems. It first estimates intermediate optical flow with a lightweight motion perception network, and then a wavelet synthesis network uses flow aligned context features to predict multi-scale wavelet coefficients with sparse convolution for efficient target frame reconstruction, where the sparse valid masks that control computation in each scale are determined by a crucial threshold ratio. Instead of setting a fixed value like previous methods, we find that embedding a classifier in the motion perception network to learn a dynamic threshold for each sample can achieve more computation reduction with almost no loss of accuracy. On the common high resolution and animation frame interpolation benchmarks, proposed WaveletVFI can reduce computation up to 40% while maintaining similar accuracy, making it perform more efficiently against other state-of-the-arts. Code is available at https://github.com/ltkong218/WaveletVFI.
VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation
Sep 07, 2023



In this paper, we present VideoGen, a text-to-video generation approach, which can generate a high-definition video with high frame fidelity and strong temporal consistency using reference-guided latent diffusion. We leverage an off-the-shelf text-to-image generation model, e.g., Stable Diffusion, to generate an image with high content quality from the text prompt, as a reference image to guide video generation. Then, we introduce an efficient cascaded latent diffusion module conditioned on both the reference image and the text prompt, for generating latent video representations, followed by a flow-based temporal upsampling step to improve the temporal resolution. Finally, we map latent video representations into a high-definition video through an enhanced video decoder. During training, we use the first frame of a ground-truth video as the reference image for training the cascaded latent diffusion module. The main characterises of our approach include: the reference image generated by the text-to-image model improves the visual fidelity; using it as the condition makes the diffusion model focus more on learning the video dynamics; and the video decoder is trained over unlabeled video data, thus benefiting from high-quality easily-available videos. VideoGen sets a new state-of-the-art in text-to-video generation in terms of both qualitative and quantitative evaluation. See \url{https://videogen.github.io/VideoGen/} for more samples.
High-fidelity Generalized Emotional Talking Face Generation with Multi-modal Emotion Space Learning
May 04, 2023



Recently, emotional talking face generation has received considerable attention. However, existing methods only adopt one-hot coding, image, or audio as emotion conditions, thus lacking flexible control in practical applications and failing to handle unseen emotion styles due to limited semantics. They either ignore the one-shot setting or the quality of generated faces. In this paper, we propose a more flexible and generalized framework. Specifically, we supplement the emotion style in text prompts and use an Aligned Multi-modal Emotion encoder to embed the text, image, and audio emotion modality into a unified space, which inherits rich semantic prior from CLIP. Consequently, effective multi-modal emotion space learning helps our method support arbitrary emotion modality during testing and could generalize to unseen emotion styles. Besides, an Emotion-aware Audio-to-3DMM Convertor is proposed to connect the emotion condition and the audio sequence to structural representation. A followed style-based High-fidelity Emotional Face generator is designed to generate arbitrary high-resolution realistic identities. Our texture generator hierarchically learns flow fields and animated faces in a residual manner. Extensive experiments demonstrate the flexibility and generalization of our method in emotion control and the effectiveness of high-quality face synthesis.
SeedFormer: Patch Seeds based Point Cloud Completion with Upsample Transformer
Jul 21, 2022
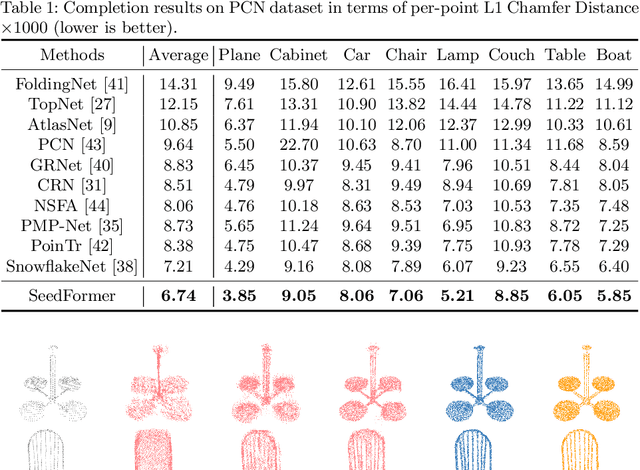
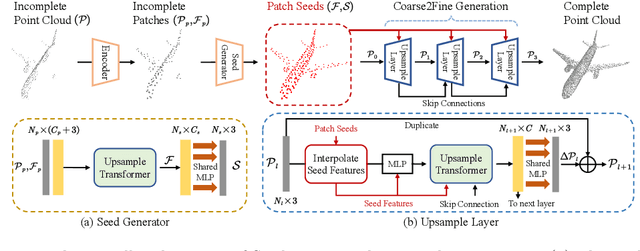
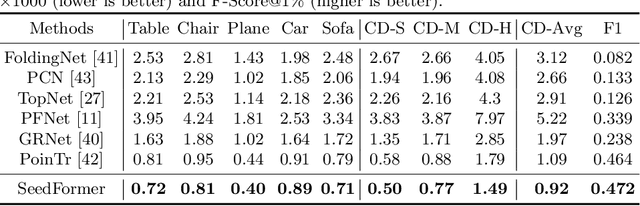
Point cloud completion has become increasingly popular among generation tasks of 3D point clouds, as it is a challenging yet indispensable problem to recover the complete shape of a 3D object from its partial observation. In this paper, we propose a novel SeedFormer to improve the ability of detail preservation and recovery in point cloud completion. Unlike previous methods based on a global feature vector, we introduce a new shape representation, namely Patch Seeds, which not only captures general structures from partial inputs but also preserves regional information of local patterns. Then, by integrating seed features into the generation process, we can recover faithful details for complete point clouds in a coarse-to-fine manner. Moreover, we devise an Upsample Transformer by extending the transformer structure into basic operations of point generators, which effectively incorporates spatial and semantic relationships between neighboring points. Qualitative and quantitative evaluations demonstrate that our method outperforms state-of-the-art completion networks on several benchmark datasets. Our code is available at https://github.com/hrzhou2/seedformer.
IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation
May 29, 2022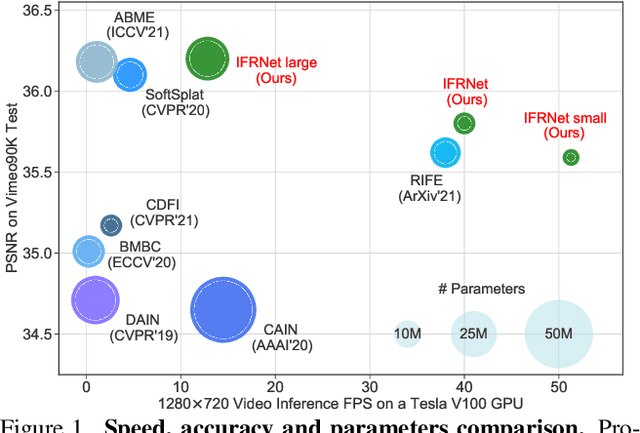
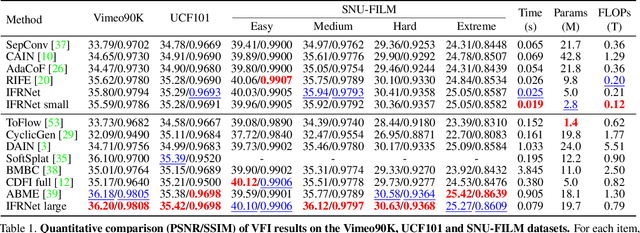

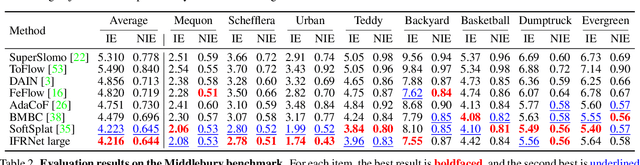
Prevailing video frame interpolation algorithms, that generate the intermediate frames from consecutive inputs, typically rely on complex model architectures with heavy parameters or large delay, hindering them from diverse real-time applications. In this work, we devise an efficient encoder-decoder based network, termed IFRNet, for fast intermediate frame synthesizing. It first extracts pyramid features from given inputs, and then refines the bilateral intermediate flow fields together with a powerful intermediate feature until generating the desired output. The gradually refined intermediate feature can not only facilitate intermediate flow estimation, but also compensate for contextual details, making IFRNet do not need additional synthesis or refinement module. To fully release its potential, we further propose a novel task-oriented optical flow distillation loss to focus on learning the useful teacher knowledge towards frame synthesizing. Meanwhile, a new geometry consistency regularization term is imposed on the gradually refined intermediate features to keep better structure layout. Experiments on various benchmarks demonstrate the excellent performance and fast inference speed of proposed approaches. Code is available at https://github.com/ltkong218/IFRNet.
CFNet: Learning Correlation Functions for One-Stage Panoptic Segmentation
Jan 13, 2022
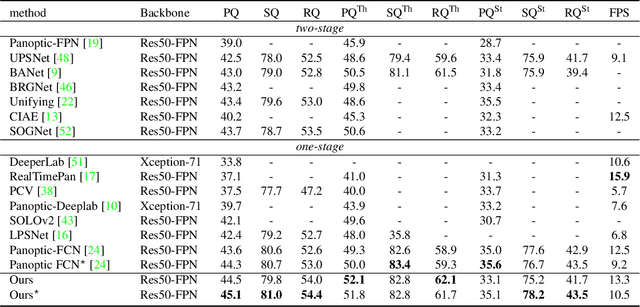
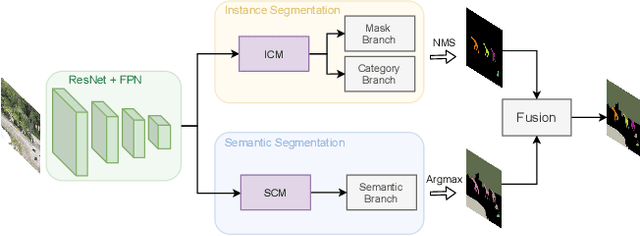
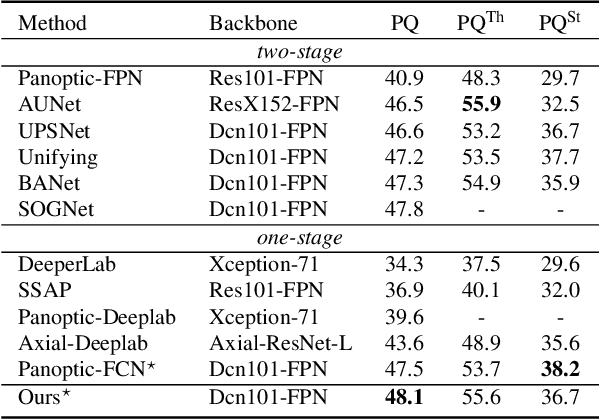
Recently, there is growing attention on one-stage panoptic segmentation methods which aim to segment instances and stuff jointly within a fully convolutional pipeline efficiently. However, most of the existing works directly feed the backbone features to various segmentation heads ignoring the demands for semantic and instance segmentation are different: The former needs semantic-level discriminative features, while the latter requires features to be distinguishable across instances. To alleviate this, we propose to first predict semantic-level and instance-level correlations among different locations that are utilized to enhance the backbone features, and then feed the improved discriminative features into the corresponding segmentation heads, respectively. Specifically, we organize the correlations between a given location and all locations as a continuous sequence and predict it as a whole. Considering that such a sequence can be extremely complicated, we adopt Discrete Fourier Transform (DFT), a tool that can approximate an arbitrary sequence parameterized by amplitudes and phrases. For different tasks, we generate these parameters from the backbone features in a fully convolutional way which is optimized implicitly by corresponding tasks. As a result, these accurate and consistent correlations contribute to producing plausible discriminative features which meet the requirements of the complicated panoptic segmentation task. To verify the effectiveness of our methods, we conduct experiments on several challenging panoptic segmentation datasets and achieve state-of-the-art performance on MS COCO with $45.1$\% PQ and ADE20k with $32.6$\% PQ.
HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping
Jun 18, 2021
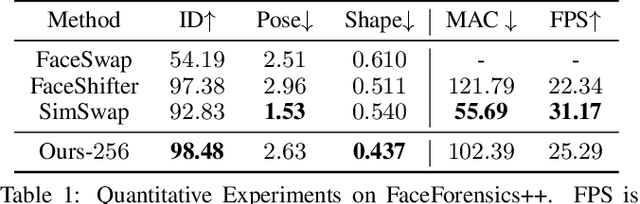
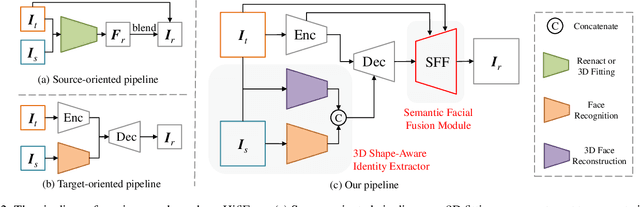
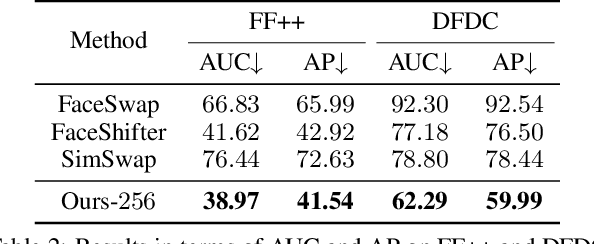
In this work, we propose a high fidelity face swapping method, called HifiFace, which can well preserve the face shape of the source face and generate photo-realistic results. Unlike other existing face swapping works that only use face recognition model to keep the identity similarity, we propose 3D shape-aware identity to control the face shape with the geometric supervision from 3DMM and 3D face reconstruction method. Meanwhile, we introduce the Semantic Facial Fusion module to optimize the combination of encoder and decoder features and make adaptive blending, which makes the results more photo-realistic. Extensive experiments on faces in the wild demonstrate that our method can preserve better identity, especially on the face shape, and can generate more photo-realistic results than previous state-of-the-art methods.
Context-Aware Image Inpainting with Learned Semantic Priors
Jun 14, 2021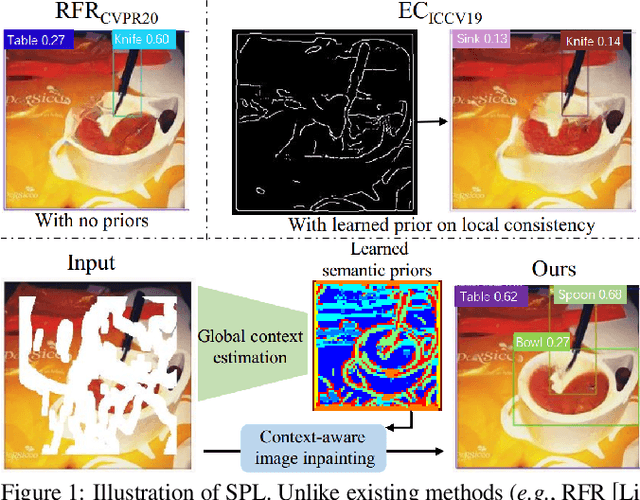
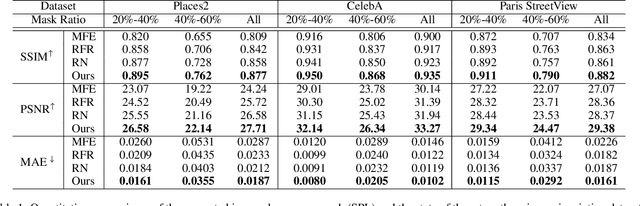
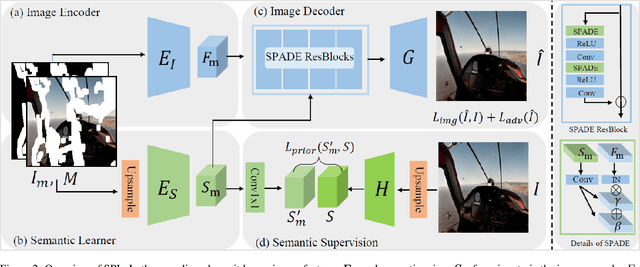

Recent advances in image inpainting have shown impressive results for generating plausible visual details on rather simple backgrounds. However, for complex scenes, it is still challenging to restore reasonable contents as the contextual information within the missing regions tends to be ambiguous. To tackle this problem, we introduce pretext tasks that are semantically meaningful to estimating the missing contents. In particular, we perform knowledge distillation on pretext models and adapt the features to image inpainting. The learned semantic priors ought to be partially invariant between the high-level pretext task and low-level image inpainting, which not only help to understand the global context but also provide structural guidance for the restoration of local textures. Based on the semantic priors, we further propose a context-aware image inpainting model, which adaptively integrates global semantics and local features in a unified image generator. The semantic learner and the image generator are trained in an end-to-end manner. We name the model SPL to highlight its ability to learn and leverage semantic priors. It achieves the state of the art on Places2, CelebA, and Paris StreetView datasets.
Adversarial Refinement Network for Human Motion Prediction
Nov 24, 2020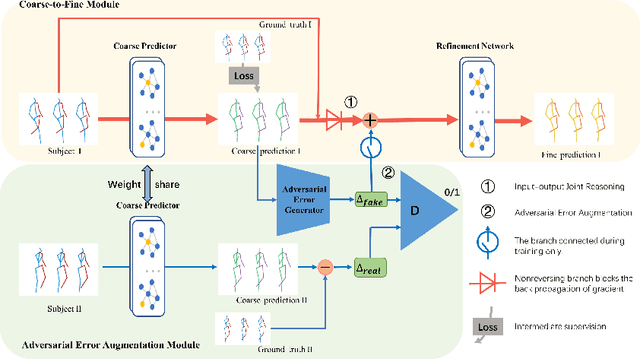
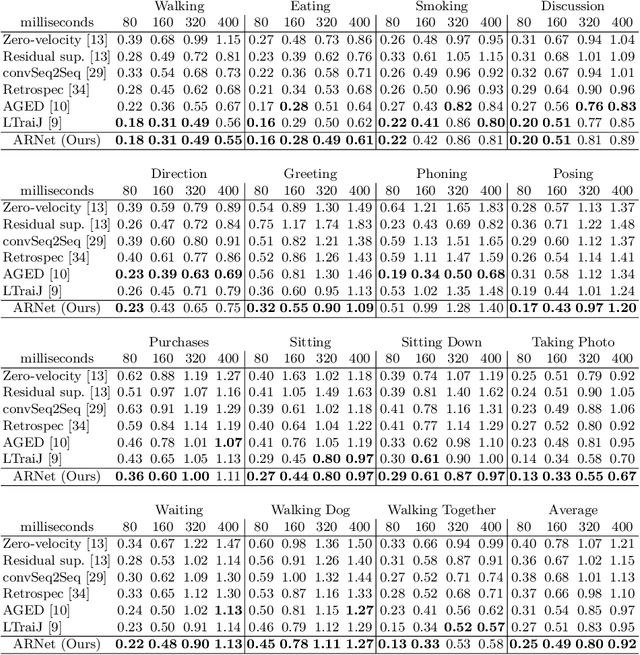
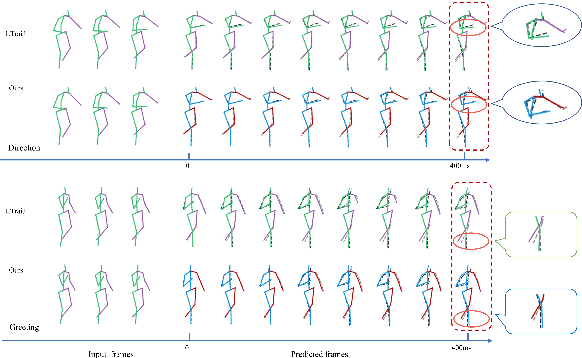
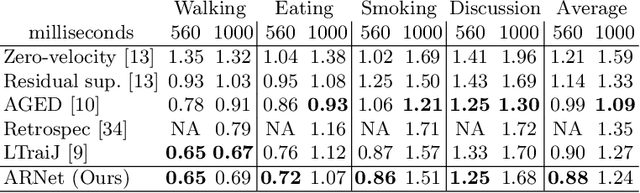
Human motion prediction aims to predict future 3D skeletal sequences by giving a limited human motion as inputs. Two popular methods, recurrent neural networks and feed-forward deep networks, are able to predict rough motion trend, but motion details such as limb movement may be lost. To predict more accurate future human motion, we propose an Adversarial Refinement Network (ARNet) following a simple yet effective coarse-to-fine mechanism with novel adversarial error augmentation. Specifically, we take both the historical motion sequences and coarse prediction as input of our cascaded refinement network to predict refined human motion and strengthen the refinement network with adversarial error augmentation. During training, we deliberately introduce the error distribution by learning through the adversarial mechanism among different subjects. In testing, our cascaded refinement network alleviates the prediction error from the coarse predictor resulting in a finer prediction robustly. This adversarial error augmentation provides rich error cases as input to our refinement network, leading to better generalization performance on the testing dataset. We conduct extensive experiments on three standard benchmark datasets and show that our proposed ARNet outperforms other state-of-the-art methods, especially on challenging aperiodic actions in both short-term and long-term predictions.