 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models
May 20, 2025Model fusion combines multiple Large Language Models (LLMs) with different strengths into a more powerful, integrated model through lightweight training methods. Existing works on model fusion focus primarily on supervised fine-tuning (SFT), leaving preference alignment (PA) --a critical phase for enhancing LLM performance--largely unexplored. The current few fusion methods on PA phase, like WRPO, simplify the process by utilizing only response outputs from source models while discarding their probability information. To address this limitation, we propose InfiFPO, a preference optimization method for implicit model fusion. InfiFPO replaces the reference model in Direct Preference Optimization (DPO) with a fused source model that synthesizes multi-source probabilities at the sequence level, circumventing complex vocabulary alignment challenges in previous works and meanwhile maintaining the probability information. By introducing probability clipping and max-margin fusion strategies, InfiFPO enables the pivot model to align with human preferences while effectively distilling knowledge from source models. Comprehensive experiments on 11 widely-used benchmarks demonstrate that InfiFPO consistently outperforms existing model fusion and preference optimization methods. When using Phi-4 as the pivot model, InfiFPO improve its average performance from 79.95 to 83.33 on 11 benchmarks, significantly improving its capabilities in mathematics, coding, and reasoning tasks.
Memory-Efficient Orthogonal Fine-Tuning with Principal Subspace Adaptation
May 16, 2025Driven by the relentless growth in model parameters, which renders full fine-tuning prohibitively expensive for large-scale deployment, parameter-efficient fine-tuning (PEFT) has emerged as a crucial approach for rapidly adapting large models to a wide range of downstream tasks. Among the PEFT family, orthogonal fine-tuning and its variants have demonstrated remarkable performance by preserving hyperspherical energy, which encodes pairwise angular similarity between neurons. However, these methods are inherently memory-inefficient due to the need to store intermediate activations from multiple full-dimensional sparse matrices. To address this limitation, we propose Memory-efficient Orthogonal Fine-Tuning (MOFT) with principal subspace adaptation. Specifically, we first establish a theoretical condition under which orthogonal transformations within a low-rank subspace preserve hyperspherical energy. Based on this insight, we constrain orthogonal fine-tuning to the principal subspace defined by the top-r components obtained through singular value decomposition and impose an additional constraint on the projection matrix to satisfy the preservation condition. To enhance MOFT's flexibility across tasks, we relax strict orthogonality by introducing two learnable scaling vectors. Extensive experiments on 37 diverse tasks and four models across NLP and CV demonstrate that MOFT consistently outperforms key baselines while significantly reducing the memory footprint of orthogonal fine-tuning.
EcoAgent: An Efficient Edge-Cloud Collaborative Multi-Agent Framework for Mobile Automation
May 08, 2025Cloud-based mobile agents powered by (multimodal) large language models ((M)LLMs) offer strong reasoning abilities but suffer from high latency and cost. While fine-tuned (M)SLMs enable edge deployment, they often lose general capabilities and struggle with complex tasks. To address this, we propose EcoAgent, an Edge-Cloud cOllaborative multi-agent framework for mobile automation. EcoAgent features a closed-loop collaboration among a cloud-based Planning Agent and two edge-based agents: the Execution Agent for action execution and the Observation Agent for verifying outcomes. The Observation Agent uses a Pre-Understanding Module to compress screen images into concise text, reducing token usage. In case of failure, the Planning Agent retrieves screen history and replans via a Reflection Module. Experiments on AndroidWorld show that EcoAgent maintains high task success rates while significantly reducing MLLM token consumption, enabling efficient and practical mobile automation.
Fast-Slow Thinking for Large Vision-Language Model Reasoning
Apr 25, 2025Recent advances in large vision-language models (LVLMs) have revealed an \textit{overthinking} phenomenon, where models generate verbose reasoning across all tasks regardless of questions. To address this issue, we present \textbf{FAST}, a novel \textbf{Fa}st-\textbf{S}low \textbf{T}hinking framework that dynamically adapts reasoning depth based on question characteristics. Through empirical analysis, we establish the feasibility of fast-slow thinking in LVLMs by investigating how response length and data distribution affect performance. We develop FAST-GRPO with three components: model-based metrics for question characterization, an adaptive thinking reward mechanism, and difficulty-aware KL regularization. Experiments across seven reasoning benchmarks demonstrate that FAST achieves state-of-the-art accuracy with over 10\% relative improvement compared to the base model, while reducing token usage by 32.7-67.3\% compared to previous slow-thinking approaches, effectively balancing reasoning length and accuracy.
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Apr 22, 2025Despite recent progress in video generation, producing videos that adhere to physical laws remains a significant challenge. Traditional diffusion-based methods struggle to extrapolate to unseen physical conditions (eg, velocity) due to their reliance on data-driven approximations. To address this, we propose to integrate symbolic reasoning and reinforcement learning to enforce physical consistency in video generation. We first introduce the Diffusion Timestep Tokenizer (DDT), which learns discrete, recursive visual tokens by recovering visual attributes lost during the diffusion process. The recursive visual tokens enable symbolic reasoning by a large language model. Based on it, we propose the Phys-AR framework, which consists of two stages: The first stage uses supervised fine-tuning to transfer symbolic knowledge, while the second stage applies reinforcement learning to optimize the model's reasoning abilities through reward functions based on physical conditions. Our approach allows the model to dynamically adjust and improve the physical properties of generated videos, ensuring adherence to physical laws. Experimental results demonstrate that PhysAR can generate videos that are physically consistent.
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Apr 19, 2025Multimodal Large Language Models (MLLMs) have powered Graphical User Interface (GUI) Agents, showing promise in automating tasks on computing devices. Recent works have begun exploring reasoning in GUI tasks with encouraging results. However, many current approaches rely on manually designed reasoning templates, which may result in reasoning that is not sufficiently robust and adaptive for complex GUI environments. Meanwhile, some existing agents continue to operate as Reactive Actors, relying primarily on implicit reasoning that may lack sufficient depth for GUI tasks demanding planning and error recovery. We argue that advancing these agents requires a shift from reactive acting towards acting based on deliberate reasoning. To facilitate this transformation, we introduce InfiGUI-R1, an MLLM-based GUI agent developed through our Actor2Reasoner framework, a reasoning-centric, two-stage training approach designed to progressively evolve agents from Reactive Actors to Deliberative Reasoners. The first stage, Reasoning Injection, focuses on establishing a basic reasoner. We employ Spatial Reasoning Distillation to transfer cross-modal spatial reasoning capabilities from teacher models to MLLMs through trajectories with explicit reasoning steps, enabling models to integrate GUI visual-spatial information with logical reasoning before action generation. The second stage, Deliberation Enhancement, refines the basic reasoner into a deliberative one using Reinforcement Learning. This stage introduces two approaches: Sub-goal Guidance, which rewards models for generating accurate intermediate sub-goals, and Error Recovery Scenario Construction, which creates failure-and-recovery training scenarios from identified prone-to-error steps. Experimental results show InfiGUI-R1 achieves strong performance in GUI grounding and trajectory tasks. Resources at https://github.com/Reallm-Labs/InfiGUI-R1.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
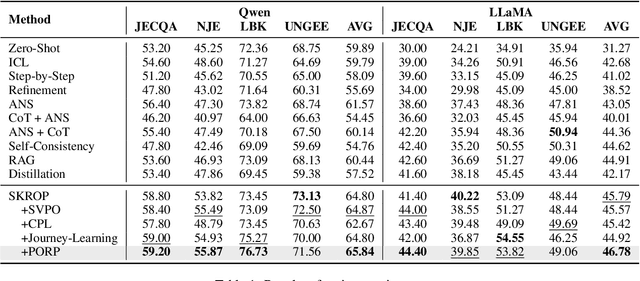
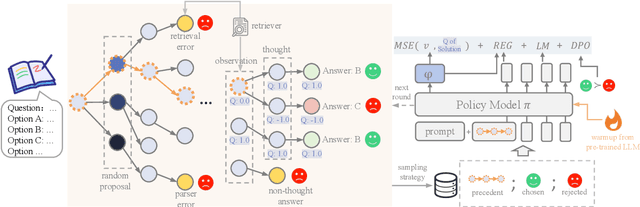
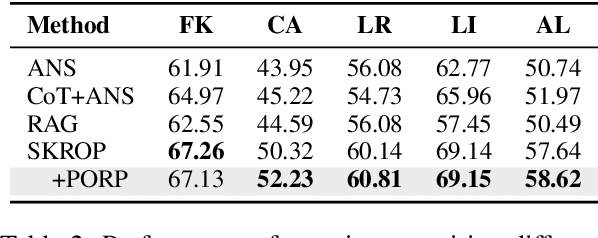
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
Benchmarking Multimodal CoT Reward Model Stepwise by Visual Program
Apr 09, 2025Recent advancements in reward signal usage for Large Language Models (LLMs) are remarkable. However, significant challenges exist when transitioning reward signal to the multimodal domain, including labor-intensive annotations, over-reliance on one-step rewards, and inadequate evaluation. To address these issues, we propose SVIP, a novel approach to train a step-level multi-dimensional Chain-of-Thought~(CoT) reward model automatically. It generates code for solving visual tasks and transforms the analysis of code blocks into the evaluation of CoT step as training samples. Then, we train SVIP-Reward model using a multi-head attention mechanism called TriAtt-CoT. The advantages of SVIP-Reward are evident throughout the entire process of MLLM. We also introduce a benchmark for CoT reward model training and testing. Experimental results demonstrate that SVIP-Reward improves MLLM performance across training and inference-time scaling, yielding better results on benchmarks while reducing hallucinations and enhancing reasoning ability.
Evaluating Test-Time Scaling LLMs for Legal Reasoning: OpenAI o1, DeepSeek-R1, and Beyond
Mar 20, 2025



Recently, Test-Time Scaling Large Language Models (LLMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated exceptional capabilities across various domains and tasks, particularly in reasoning. While these models have shown impressive performance on general language tasks, their effectiveness in specialized fields like legal remains unclear. To address this, we present a preliminary evaluation of LLMs in various legal scenarios, covering both Chinese and English legal tasks. Our analysis includes 9 LLMs and 17 legal tasks, with a focus on newly published and more complex challenges such as multi-defendant legal judgments and legal argument reasoning. Our findings indicate that, despite DeepSeek-R1 and OpenAI o1 being among the most powerful models, their legal reasoning capabilities are still lacking. Specifically, these models score below 80\% on seven Chinese legal reasoning tasks and below 80\% on two English legal reasoning tasks. This suggests that, even among the most advanced reasoning models, legal reasoning abilities remain underdeveloped.
Modeling Fine-Grained Hand-Object Dynamics for Egocentric Video Representation Learning
Mar 02, 2025In egocentric video understanding, the motion of hands and objects as well as their interactions play a significant role by nature. However, existing egocentric video representation learning methods mainly focus on aligning video representation with high-level narrations, overlooking the intricate dynamics between hands and objects. In this work, we aim to integrate the modeling of fine-grained hand-object dynamics into the video representation learning process. Since no suitable data is available, we introduce HOD, a novel pipeline employing a hand-object detector and a large language model to generate high-quality narrations with detailed descriptions of hand-object dynamics. To learn these fine-grained dynamics, we propose EgoVideo, a model with a new lightweight motion adapter to capture fine-grained hand-object motion information. Through our co-training strategy, EgoVideo effectively and efficiently leverages the fine-grained hand-object dynamics in the HOD data. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple egocentric downstream tasks, including improvements of 6.3% in EK-100 multi-instance retrieval, 5.7% in EK-100 classification, and 16.3% in EGTEA classification in zero-shot settings. Furthermore, our model exhibits robust generalization capabilities in hand-object interaction and robot manipulation tasks. Code and data are available at https://github.com/OpenRobotLab/EgoHOD/.