 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccess Sets Matter: Budgeting Expert Reads for Scalable Weight-Space Model Merging
May 28, 2026Weight-space model merging is usually formulated as an algebraic operation on checkpoints, yet at LLM scale the limiting resource is often the set of expert weights that must be read. We introduce MergePipe, a budget-aware execution layer that casts LLM merging as an \emph{expert access-set} problem: given a merge operator and a checkpoint family in a shared weight coordinate system, choose which expert delta blocks to access under an explicit I/O budget. MergePipe indexes parameter blocks, builds deterministic access plans, and executes the induced budgeted merge with replayable manifests. The plan is budget-sound by construction and recovers the full-read merge at full budget; for fixed-coefficient additive operators, the omitted-update error is bounded by the norm of omitted deltas. Across Qwen and Llama merging workloads, MergePipe reduces expert-read I/O by up to an order of magnitude and achieves up to $11\times$ speedups. Representative budget sweeps show $O(10^{-3})$ parameter deviation from full-read merges and no monotonic degradation on downstream benchmarks.
Not All Disagreement Is Learnable: Token Teachability in On-Policy Distillation
May 26, 2026On-policy distillation (OPD) trains a student on its own rollouts with token-level teacher supervision. Recent selective OPD methods exploit the non-uniformity of OPD signals by prioritizing high-entropy or high-disagreement tokens. We revisit this principle and ask: which token-level teacher signals are actually learnable? Using a fixed-context diagnostic that measures same-context teacher-student KL reduction, we show that raw KL disagreement is a coarse proxy for learning value. It conflates learnable disagreement, where the teacher assigns corrective mass to the student's top-K candidates, with incompatible disagreement, where the teacher places mass mostly off the student's current support. We formalize this local compatibility as token teachability and show that it better predicts fixed-context improvement than raw KL alone. Motivated by this finding, we propose Teachability-Aware OPD (TA-OPD), a lightweight token-position selection method that applies OPD loss to high-teachability positions without reward models or verifiers. Across Qwen2.5 and Qwen 3 teacher-student settings, TA-OPD often surpasses full-token OPD with only 5% retained tokens and improves over entropy- and divergence-based baselines. Our results reframe selective OPD as selecting learnable teacher signals rather than merely salient tokens.
Discovering Physical Directions in Weight Space: Composing Neural PDE Experts
May 14, 2026Recent advances in neural operators have made partial differential equation (PDE) surrogate modeling increasingly scalable and transferable through large-scale pretraining and in-context adaptation. However, after a shared operator is fine-tuned to multiple regimes within a continuous physical family, it remains unclear whether the resulting weight-space updates merely form isolated regime experts or reveal reusable physical structure. Starting from a shared family anchor, we fine-tune low- and high-regime endpoint experts and show that their updates can be separated into a family-shared adaptation and a direction aligned with the underlying physical parameter. This separation reinterprets endpoint experts as finite-difference probes of a local physical direction in weight space, explaining why static averaging can interpolate between regimes but attenuates endpoint-specific physics. Building on this perspective, we propose Calibration-Conditioned Merge (CCM), a post-hoc coordinate readout method for composing neural PDE experts along this physical direction. Given physical metadata, a calibrated coordinate mapping, or a short observed rollout prefix, CCM infers the target composition coordinate and deploys a single merged checkpoint for the remaining rollout. We evaluate CCM on the reaction--diffusion system, viscosity-parameterized two-dimensional Navier--Stokes equations, and radial dam-break dynamics. Across these benchmarks, CCM achieves its strongest gains in extrapolative regimes, reducing out-of-distribution rollout error relative to the family anchor by 54.2%, 42.8%, and 13.8%, respectively. Further experiments across FNO scales, a DPOT-style backbone, and ablations confirm that endpoint fine-tuning is not arbitrary checkpoint drift, but reveals a calibratable physical direction for training-free transfer across PDE regimes.
FeatCal: Feature Calibration for Post-Merging Models
May 13, 2026Model merging combines task experts into one model and avoids joint training, retraining, or deploying many expert models, but the merged model often still underperforms task experts. We study this performance gap through feature drift, the difference between features produced by the merged model and by the expert on the same input. Our theory decomposes this drift into upstream propagation and local mismatch, tracks how it propagates and combines through later layers in forward order, and links final feature drift to output drift. This view motivates FeatCal, which uses a small calibration set to calibrate the merged model weights layer by layer in forward order, reducing feature drift while staying close to merged weights and preserving the benefits of model merging. FeatCal uses an efficient closed-form solution to update model weights, with no gradient descent, iterative optimization, or extra modules. On the main CLIP and GLUE benchmarks, FeatCal beats Surgery and ProbSurgery, the closest post-merging calibration baselines: 85.5% vs. 77.0%/78.8% on CLIP-ViT-B/32 Task Arithmetic (TA) and 85.2% vs. 83.7%/82.2% on FLAN-T5-base GLUE. On CLIP-ViT-B/32, 8 examples per task reach 82.9%, and 256 examples per task take 53 seconds, about 4x faster than both baselines, showing better sample efficiency and lower calibration cost.
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
May 10, 2026Continual post-training aims to extend large language models (LLMs) with new knowledge, skills, and behaviors, yet it remains unclear when sequential updates enable capability transfer and when they cause catastrophic forgetting. Existing methods mitigate forgetting through sequential fine-tuning, replay, regularization, or model merging, but offer limited criteria for determining when incorporating new updates is beneficial or harmful. In this work, we study LLM continual post-training through three questions: What drives forgetting? When do sequentially acquired capabilities transfer or interfere? How can compatibility be used to control update integration? We address these questions through task geometry: we represent each post-training task by its parameter update and study the covariance geometry induced by the update. Our central finding is that: forgetting can be considered as a state-relative update-integration failure, it arises when the covariance geometries induced by tasks misalign with the geometry of the evolving model state. Sequential updates transfer when they remain compatible with the model state shaped by previous updates, and interfere when state-relative geometry conflict becomes high. Motivated by this finding, we propose Geometry-Conflict Wasserstein Merging (GCWM), a data-free update-integration method that constructs a shared Wasserstein metric via Gaussian Wasserstein barycenters and uses geometry conflict to gate geometry-aware correction. Across Qwen3 0.6B--14B on domain-continual and capability-continual settings, GCWM consistently outperforms data-free baselines, improving retention and final performance without replay data. These results identify geometry conflict as both an explanatory signal for forgetting and a practical control signal for LLM continual post-training.
InfiCoEvalChain: A Blockchain-Based Decentralized Framework for Collaborative LLM Evaluation
Feb 09, 2026The rapid advancement of large language models (LLMs) demands increasingly reliable evaluation, yet current centralized evaluation suffers from opacity, overfitting, and hardware-induced variance. Our empirical analysis reveals an alarming inconsistency in existing evaluations: the standard deviation across ten repeated runs of a single model on HumanEval (1.67) actually exceeds the performance gap among the top-10 models on the official leaderboard (0.91), rendering current rankings statistically precarious. To mitigate these instabilities, we propose a decentralized evaluation framework that enables hardware and parameter diversity through large-scale benchmarking across heterogeneous compute nodes. By leveraging the blockchain-based protocol, the framework incentivizes global contributors to act as independent validators, using a robust reward system to ensure evaluation integrity and discourage dishonest participation. This collective verification transforms evaluation from a "centralized black box" into a "decentralized endorsement" where multi-party consensus and diverse inference environments yield a more stable, representative metric. Experimental results demonstrate that the decentralized evaluation framework reduces the standard deviation across ten runs on the same model to 0.28. This significant improvement over conventional frameworks ensures higher statistical confidence in model rankings. We have completely implemented this platform and will soon release it to the community.
MergePipe: A Budget-Aware Parameter Management System for Scalable LLM Merging
Feb 05, 2026Large language model (LLM) merging has become a key technique in modern LLM development pipelines, enabling the integration of multiple task- or domain-specific expert models without retraining. However, as the number of experts grows, existing merging implementations treat model parameters as unstructured files and execute merges in a stateless, one-shot manner, leading to excessive disk I/O, redundant parameter scans, and poor scalability. In this paper, we present \textbf{MergePipe}, a parameter management system for scalable LLM merging. MergePipe is the first system that treats LLM merging as a data management and execution problem, and introduces a catalog-driven abstraction over model parameters, merge plans, and execution lineage. At its core, MergePipe employs a cost-aware planner that explicitly models expert parameter I/O and enforces user-specified I/O budgets, followed by a streaming execution engine that materializes merged models under transactional guarantees. Our key insight is that while base model reads and output writes are unavoidable, expert parameter reads dominate merge cost and constitute the primary optimization target. By making expert access budget-aware throughout planning and execution, MergePipe mitigates the $O(K)$ I/O growth of naive pipelines and achieves predictable scaling behavior. Experiments show that MergePipe reduces total I/O by up to an order of magnitude and delivers up to $11\times$ end-to-end speedups (up to 90\% wall-time reduction) over state-of-the-art LLM merging pipelines.
InfiGFusion: Graph-on-Logits Distillation via Efficient Gromov-Wasserstein for Model Fusion
May 20, 2025

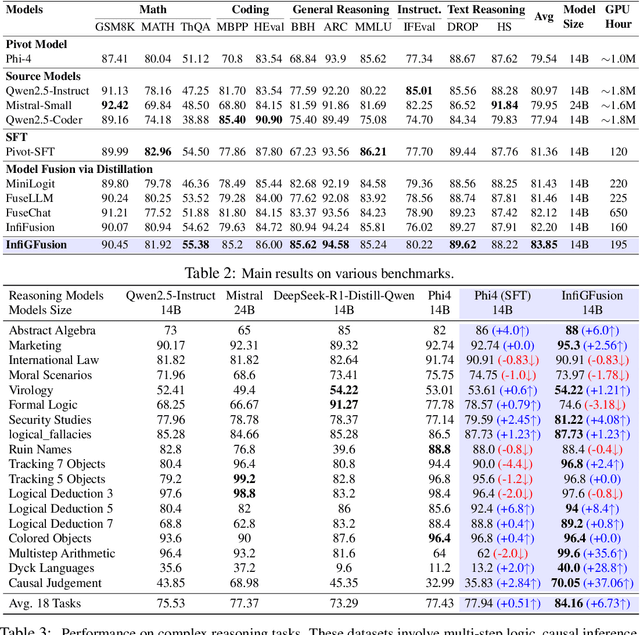

Recent advances in large language models (LLMs) have intensified efforts to fuse heterogeneous open-source models into a unified system that inherits their complementary strengths. Existing logit-based fusion methods maintain inference efficiency but treat vocabulary dimensions independently, overlooking semantic dependencies encoded by cross-dimension interactions. These dependencies reflect how token types interact under a model's internal reasoning and are essential for aligning models with diverse generation behaviors. To explicitly model these dependencies, we propose \textbf{InfiGFusion}, the first structure-aware fusion framework with a novel \textit{Graph-on-Logits Distillation} (GLD) loss. Specifically, we retain the top-$k$ logits per output and aggregate their outer products across sequence positions to form a global co-activation graph, where nodes represent vocabulary channels and edges quantify their joint activations. To ensure scalability and efficiency, we design a sorting-based closed-form approximation that reduces the original $O(n^4)$ cost of Gromov-Wasserstein distance to $O(n \log n)$, with provable approximation guarantees. Experiments across multiple fusion settings show that GLD consistently improves fusion quality and stability. InfiGFusion outperforms SOTA models and fusion baselines across 11 benchmarks spanning reasoning, coding, and mathematics. It shows particular strength in complex reasoning tasks, with +35.6 improvement on Multistep Arithmetic and +37.06 on Causal Judgement over SFT, demonstrating superior multi-step and relational inference.
InfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models
May 20, 2025Model fusion combines multiple Large Language Models (LLMs) with different strengths into a more powerful, integrated model through lightweight training methods. Existing works on model fusion focus primarily on supervised fine-tuning (SFT), leaving preference alignment (PA) --a critical phase for enhancing LLM performance--largely unexplored. The current few fusion methods on PA phase, like WRPO, simplify the process by utilizing only response outputs from source models while discarding their probability information. To address this limitation, we propose InfiFPO, a preference optimization method for implicit model fusion. InfiFPO replaces the reference model in Direct Preference Optimization (DPO) with a fused source model that synthesizes multi-source probabilities at the sequence level, circumventing complex vocabulary alignment challenges in previous works and meanwhile maintaining the probability information. By introducing probability clipping and max-margin fusion strategies, InfiFPO enables the pivot model to align with human preferences while effectively distilling knowledge from source models. Comprehensive experiments on 11 widely-used benchmarks demonstrate that InfiFPO consistently outperforms existing model fusion and preference optimization methods. When using Phi-4 as the pivot model, InfiFPO improve its average performance from 79.95 to 83.33 on 11 benchmarks, significantly improving its capabilities in mathematics, coding, and reasoning tasks.
Interdependency Matters: Graph Alignment for Multivariate Time Series Anomaly Detection
Oct 11, 2024



Anomaly detection in multivariate time series (MTS) is crucial for various applications in data mining and industry. Current industrial methods typically approach anomaly detection as an unsupervised learning task, aiming to identify deviations by estimating the normal distribution in noisy, label-free datasets. These methods increasingly incorporate interdependencies between channels through graph structures to enhance accuracy. However, the role of interdependencies is more critical than previously understood, as shifts in interdependencies between MTS channels from normal to anomalous data are significant. This observation suggests that \textit{anomalies could be detected by changes in these interdependency graph series}. To capitalize on this insight, we introduce MADGA (MTS Anomaly Detection via Graph Alignment), which redefines anomaly detection as a graph alignment (GA) problem that explicitly utilizes interdependencies for anomaly detection. MADGA dynamically transforms subsequences into graphs to capture the evolving interdependencies, and Graph alignment is performed between these graphs, optimizing an alignment plan that minimizes cost, effectively minimizing the distance for normal data and maximizing it for anomalous data. Uniquely, our GA approach involves explicit alignment of both nodes and edges, employing Wasserstein distance for nodes and Gromov-Wasserstein distance for edges. To our knowledge, this is the first application of GA to MTS anomaly detection that explicitly leverages interdependency for this purpose. Extensive experiments on diverse real-world datasets validate the effectiveness of MADGA, demonstrating its capability to detect anomalies and differentiate interdependencies, consistently achieving state-of-the-art across various scenarios.