 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Missing in Screen-to-Action? Towards a UI-in-the-Loop Paradigm for Multimodal GUI Reasoning
Apr 08, 2026Existing Graphical User Interface (GUI) reasoning tasks remain challenging, particularly in UI understanding. Current methods typically rely on direct screen-based decision-making, which lacks interpretability and overlooks a comprehensive understanding of UI elements, ultimately leading to task failure. To enhance the understanding and interaction with UIs, we propose an innovative GUI reasoning paradigm called UI-in-the-Loop (UILoop). Our approach treats the GUI reasoning task as a cyclic Screen-UI elements-Action process. By enabling Multimodal Large Language Models (MLLMs) to explicitly learn the localization, semantic functions, and practical usage of key UI elements, UILoop achieves precise element discovery and performs interpretable reasoning. Furthermore, we introduce a more challenging UI Comprehension task centered on UI elements with three evaluation metrics. Correspondingly, we contribute a benchmark of 26K samples (UI Comprehension-Bench) to comprehensively evaluate existing methods' mastery of UI elements. Extensive experiments demonstrate that UILoop achieves state-of-the-art UI understanding performance while yielding superior results in GUI reasoning tasks.
Practical Framework for Privacy-Preserving and Byzantine-robust Federated Learning
Dec 19, 2025Federated Learning (FL) allows multiple clients to collaboratively train a model without sharing their private data. However, FL is vulnerable to Byzantine attacks, where adversaries manipulate client models to compromise the federated model, and privacy inference attacks, where adversaries exploit client models to infer private data. Existing defenses against both backdoor and privacy inference attacks introduce significant computational and communication overhead, creating a gap between theory and practice. To address this, we propose ABBR, a practical framework for Byzantine-robust and privacy-preserving FL. We are the first to utilize dimensionality reduction to speed up the private computation of complex filtering rules in privacy-preserving FL. Additionally, we analyze the accuracy loss of vector-wise filtering in low-dimensional space and introduce an adaptive tuning strategy to minimize the impact of malicious models that bypass filtering on the global model. We implement ABBR with state-of-the-art Byzantine-robust aggregation rules and evaluate it on public datasets, showing that it runs significantly faster, has minimal communication overhead, and maintains nearly the same Byzantine-resilience as the baselines.
Gradient Surgery for Safe LLM Fine-Tuning
Aug 10, 2025Fine-tuning-as-a-Service introduces a critical vulnerability where a few malicious examples mixed into the user's fine-tuning dataset can compromise the safety alignment of Large Language Models (LLMs). While a recognized paradigm frames safe fine-tuning as a multi-objective optimization problem balancing user task performance with safety alignment, we find existing solutions are critically sensitive to the harmful ratio, with defenses degrading sharply as harmful ratio increases. We diagnose that this failure stems from conflicting gradients, where the user-task update directly undermines the safety objective. To resolve this, we propose SafeGrad, a novel method that employs gradient surgery. When a conflict is detected, SafeGrad nullifies the harmful component of the user-task gradient by projecting it onto the orthogonal plane of the alignment gradient, allowing the model to learn the user's task without sacrificing safety. To further enhance robustness and data efficiency, we employ a KL-divergence alignment loss that learns the rich, distributional safety profile of the well-aligned foundation model. Extensive experiments show that SafeGrad provides state-of-the-art defense across various LLMs and datasets, maintaining robust safety even at high harmful ratios without compromising task fidelity.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025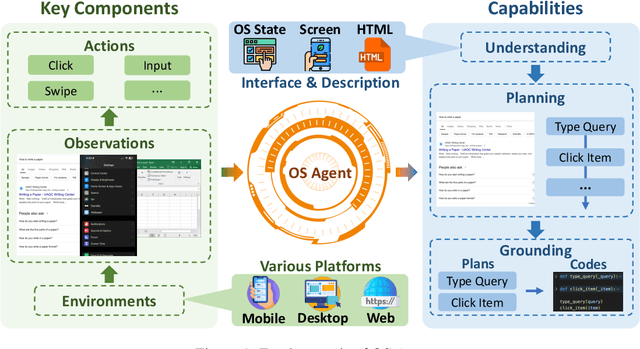
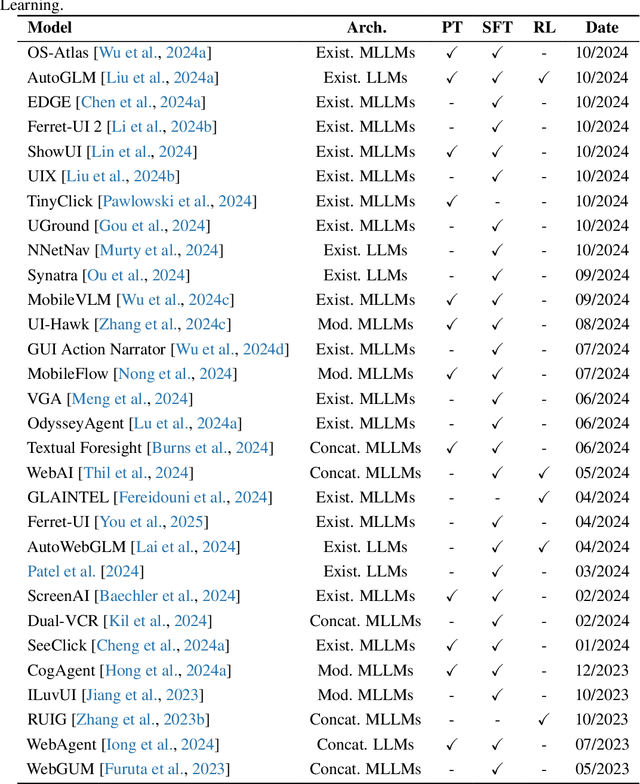
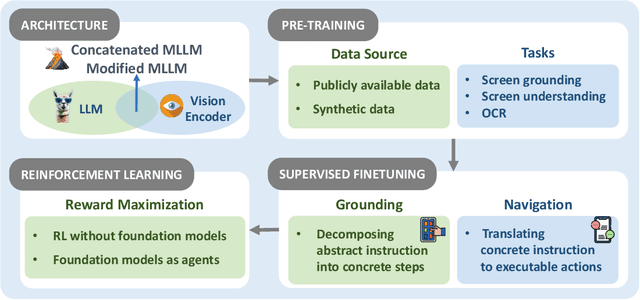
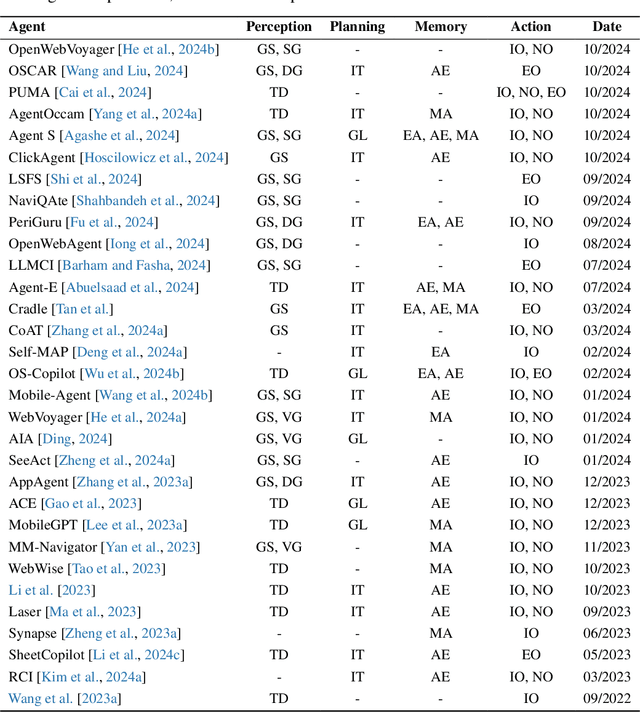
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
CTRAP: Embedding Collapse Trap to Safeguard Large Language Models from Harmful Fine-Tuning
May 22, 2025Fine-tuning-as-a-service, while commercially successful for Large Language Model (LLM) providers, exposes models to harmful fine-tuning attacks. As a widely explored defense paradigm against such attacks, unlearning attempts to remove malicious knowledge from LLMs, thereby essentially preventing them from being used to perform malicious tasks. However, we highlight a critical flaw: the powerful general adaptability of LLMs allows them to easily bypass selective unlearning by rapidly relearning or repurposing their capabilities for harmful tasks. To address this fundamental limitation, we propose a paradigm shift: instead of selective removal, we advocate for inducing model collapse--effectively forcing the model to "unlearn everything"--specifically in response to updates characteristic of malicious adaptation. This collapse directly neutralizes the very general capabilities that attackers exploit, tackling the core issue unaddressed by selective unlearning. We introduce the Collapse Trap (CTRAP) as a practical mechanism to implement this concept conditionally. Embedded during alignment, CTRAP pre-configures the model's reaction to subsequent fine-tuning dynamics. If updates during fine-tuning constitute a persistent attempt to reverse safety alignment, the pre-configured trap triggers a progressive degradation of the model's core language modeling abilities, ultimately rendering it inert and useless for the attacker. Crucially, this collapse mechanism remains dormant during benign fine-tuning, ensuring the model's utility and general capabilities are preserved for legitimate users. Extensive empirical results demonstrate that CTRAP effectively counters harmful fine-tuning risks across various LLMs and attack settings, while maintaining high performance in benign scenarios. Our code is available at https://anonymous.4open.science/r/CTRAP.
When Safety Detectors Aren't Enough: A Stealthy and Effective Jailbreak Attack on LLMs via Steganographic Techniques
May 22, 2025



Jailbreak attacks pose a serious threat to large language models (LLMs) by bypassing built-in safety mechanisms and leading to harmful outputs. Studying these attacks is crucial for identifying vulnerabilities and improving model security. This paper presents a systematic survey of jailbreak methods from the novel perspective of stealth. We find that existing attacks struggle to simultaneously achieve toxic stealth (concealing toxic content) and linguistic stealth (maintaining linguistic naturalness). Motivated by this, we propose StegoAttack, a fully stealthy jailbreak attack that uses steganography to hide the harmful query within benign, semantically coherent text. The attack then prompts the LLM to extract the hidden query and respond in an encrypted manner. This approach effectively hides malicious intent while preserving naturalness, allowing it to evade both built-in and external safety mechanisms. We evaluate StegoAttack on four safety-aligned LLMs from major providers, benchmarking against eight state-of-the-art methods. StegoAttack achieves an average attack success rate (ASR) of 92.00%, outperforming the strongest baseline by 11.0%. Its ASR drops by less than 1% even under external detection (e.g., Llama Guard). Moreover, it attains the optimal comprehensive scores on stealth detection metrics, demonstrating both high efficacy and exceptional stealth capabilities. The code is available at https://anonymous.4open.science/r/StegoAttack-Jail66
EcoAgent: An Efficient Edge-Cloud Collaborative Multi-Agent Framework for Mobile Automation
May 08, 2025Cloud-based mobile agents powered by (multimodal) large language models ((M)LLMs) offer strong reasoning abilities but suffer from high latency and cost. While fine-tuned (M)SLMs enable edge deployment, they often lose general capabilities and struggle with complex tasks. To address this, we propose EcoAgent, an Edge-Cloud cOllaborative multi-agent framework for mobile automation. EcoAgent features a closed-loop collaboration among a cloud-based Planning Agent and two edge-based agents: the Execution Agent for action execution and the Observation Agent for verifying outcomes. The Observation Agent uses a Pre-Understanding Module to compress screen images into concise text, reducing token usage. In case of failure, the Planning Agent retrieves screen history and replans via a Reflection Module. Experiments on AndroidWorld show that EcoAgent maintains high task success rates while significantly reducing MLLM token consumption, enabling efficient and practical mobile automation.
Traceback of Poisoning Attacks to Retrieval-Augmented Generation
Apr 30, 2025



Large language models (LLMs) integrated with retrieval-augmented generation (RAG) systems improve accuracy by leveraging external knowledge sources. However, recent research has revealed RAG's susceptibility to poisoning attacks, where the attacker injects poisoned texts into the knowledge database, leading to attacker-desired responses. Existing defenses, which predominantly focus on inference-time mitigation, have proven insufficient against sophisticated attacks. In this paper, we introduce RAGForensics, the first traceback system for RAG, designed to identify poisoned texts within the knowledge database that are responsible for the attacks. RAGForensics operates iteratively, first retrieving a subset of texts from the database and then utilizing a specially crafted prompt to guide an LLM in detecting potential poisoning texts. Empirical evaluations across multiple datasets demonstrate the effectiveness of RAGForensics against state-of-the-art poisoning attacks. This work pioneers the traceback of poisoned texts in RAG systems, providing a practical and promising defense mechanism to enhance their security.
Your Fixed Watermark is Fragile: Towards Semantic-Aware Watermark for EaaS Copyright Protection
Nov 14, 2024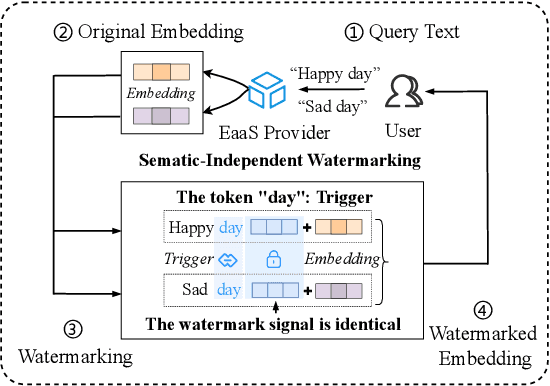
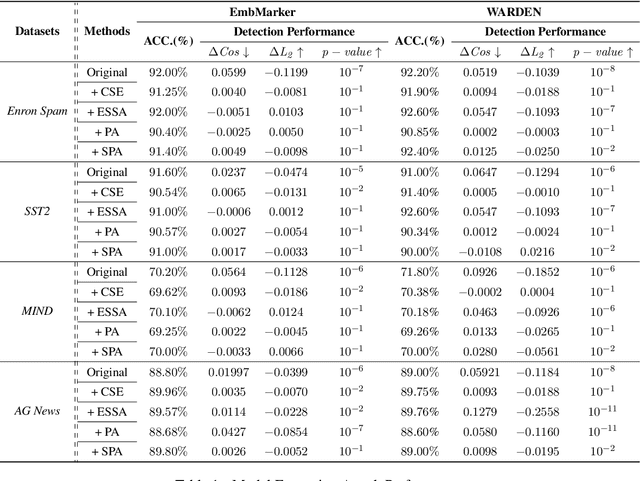
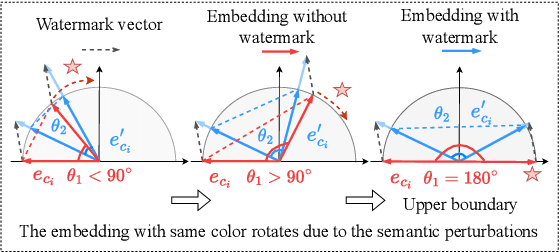
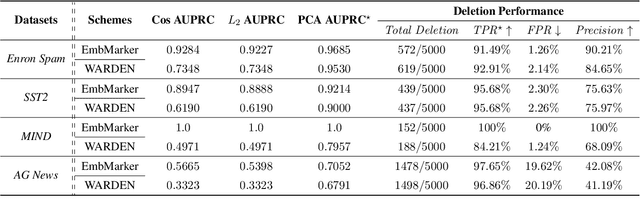
Embedding-as-a-Service (EaaS) has emerged as a successful business pattern but faces significant challenges related to various forms of copyright infringement, including API misuse and different attacks. Various studies have proposed backdoor-based watermarking schemes to protect the copyright of EaaS services. In this paper, we reveal that previous watermarking schemes possess semantic-independent characteristics and propose the Semantic Perturbation Attack (SPA). Our theoretical and experimental analyses demonstrate that this semantic-independent nature makes current watermarking schemes vulnerable to adaptive attacks that exploit semantic perturbations test to bypass watermark verification. To address this vulnerability, we propose the Semantic Aware Watermarking (SAW) scheme, a robust defense mechanism designed to resist SPA, by injecting a watermark that adapts to the text semantics. Extensive experimental results across multiple datasets demonstrate that the True Positive Rate (TPR) for detecting watermarked samples under SPA can reach up to more than 95%, rendering previous watermarks ineffective. Meanwhile, our watermarking scheme can resist such attack while ensuring the watermark verification capability. Our code is available at https://github.com/Zk4-ps/EaaS-Embedding-Watermark.
Prompt-Guided Internal States for Hallucination Detection of Large Language Models
Nov 07, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of tasks in different domains. However, they sometimes generate responses that are logically coherent but factually incorrect or misleading, which is known as LLM hallucinations. Data-driven supervised methods train hallucination detectors by leveraging the internal states of LLMs, but detectors trained on specific domains often struggle to generalize well to other domains. In this paper, we aim to enhance the cross-domain performance of supervised detectors with only in-domain data. We propose a novel framework, prompt-guided internal states for hallucination detection of LLMs, namely PRISM. By utilizing appropriate prompts to guide changes in the structure related to text truthfulness within the LLM's internal states, we make this structure more salient and consistent across texts from different domains. We integrated our framework with existing hallucination detection methods and conducted experiments on datasets from different domains. The experimental results indicate that our framework significantly enhances the cross-domain generalization of existing hallucination detection methods.