 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Efficient Domain Generalization via Collaborative Exploration and Generalization
Aug 07, 2022
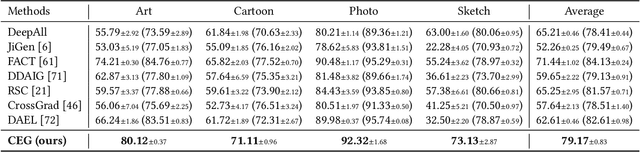
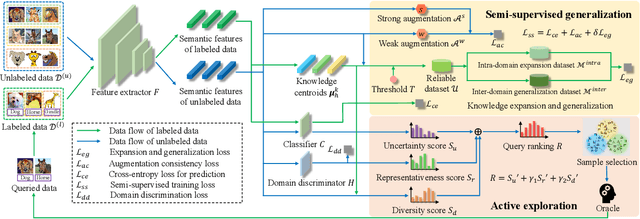

Considerable progress has been made in domain generalization (DG) which aims to learn a generalizable model from multiple well-annotated source domains to unknown target domains. However, it can be prohibitively expensive to obtain sufficient annotation for source datasets in many real scenarios. To escape from the dilemma between domain generalization and annotation costs, in this paper, we introduce a novel task named label-efficient domain generalization (LEDG) to enable model generalization with label-limited source domains. To address this challenging task, we propose a novel framework called Collaborative Exploration and Generalization (CEG) which jointly optimizes active exploration and semi-supervised generalization. Specifically, in active exploration, to explore class and domain discriminability while avoiding information divergence and redundancy, we query the labels of the samples with the highest overall ranking of class uncertainty, domain representativeness, and information diversity. In semi-supervised generalization, we design MixUp-based intra- and inter-domain knowledge augmentation to expand domain knowledge and generalize domain invariance. We unify active exploration and semi-supervised generalization in a collaborative way and promote mutual enhancement between them, boosting model generalization with limited annotation. Extensive experiments show that CEG yields superior generalization performance. In particular, CEG can even use only 5% data annotation budget to achieve competitive results compared to the previous DG methods with fully labeled data on PACS dataset.
E2-AEN: End-to-End Incremental Learning with Adaptively Expandable Network
Jul 14, 2022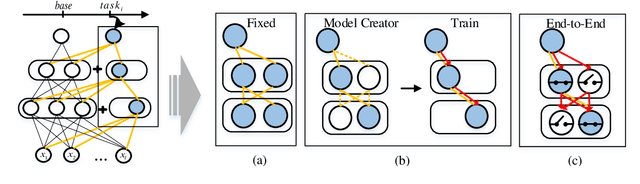
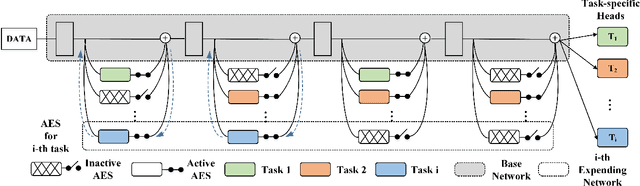
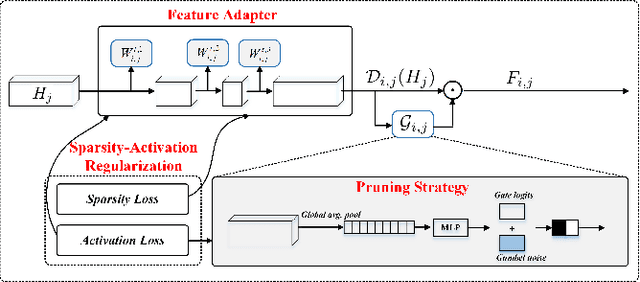
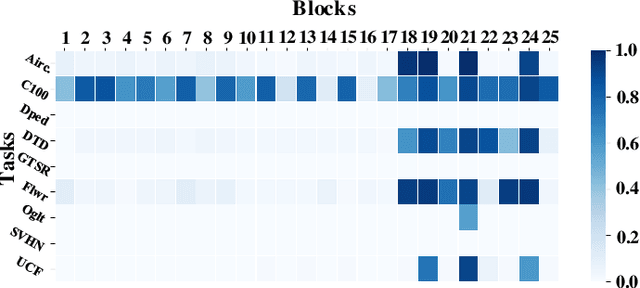
Expandable networks have demonstrated their advantages in dealing with catastrophic forgetting problem in incremental learning. Considering that different tasks may need different structures, recent methods design dynamic structures adapted to different tasks via sophisticated skills. Their routine is to search expandable structures first and then train on the new tasks, which, however, breaks tasks into multiple training stages, leading to suboptimal or overmuch computational cost. In this paper, we propose an end-to-end trainable adaptively expandable network named E2-AEN, which dynamically generates lightweight structures for new tasks without any accuracy drop in previous tasks. Specifically, the network contains a serial of powerful feature adapters for augmenting the previously learned representations to new tasks, and avoiding task interference. These adapters are controlled via an adaptive gate-based pruning strategy which decides whether the expanded structures can be pruned, making the network structure dynamically changeable according to the complexity of the new tasks. Moreover, we introduce a novel sparsity-activation regularization to encourage the model to learn discriminative features with limited parameters. E2-AEN reduces cost and can be built upon any feed-forward architectures in an end-to-end manner. Extensive experiments on both classification (i.e., CIFAR and VDD) and detection (i.e., COCO, VOC and ICCV2021 SSLAD challenge) benchmarks demonstrate the effectiveness of the proposed method, which achieves the new remarkable results.
TRIE++: Towards End-to-End Information Extraction from Visually Rich Documents
Jul 14, 2022
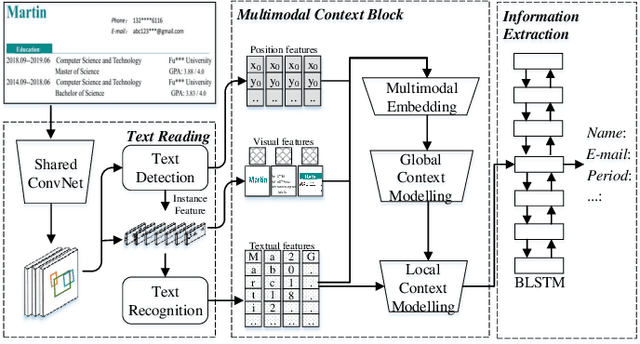
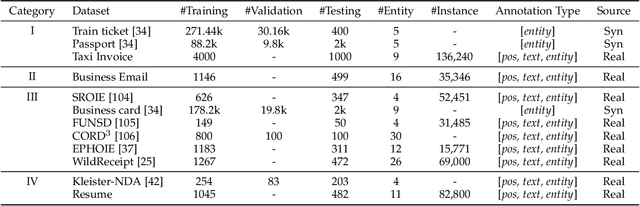
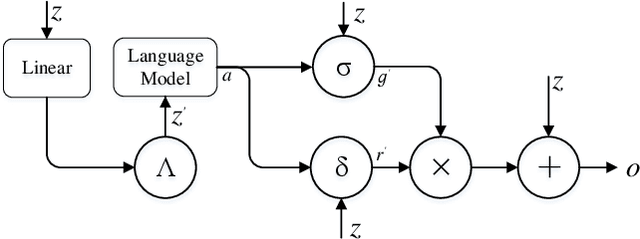
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.
Knowledge Distillation of Transformer-based Language Models Revisited
Jun 30, 2022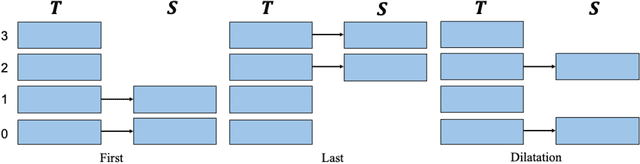
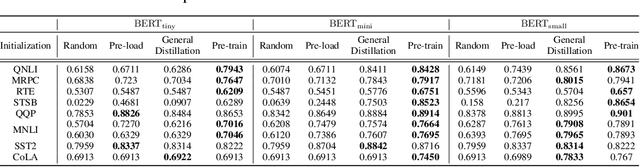
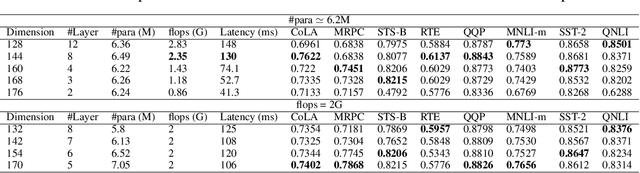
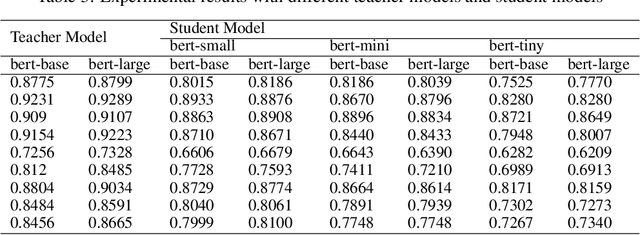
In the past few years, transformer-based pre-trained language models have achieved astounding success in both industry and academia. However, the large model size and high run-time latency are serious impediments to applying them in practice, especially on mobile phones and Internet of Things (IoT) devices. To compress the model, considerable literature has grown up around the theme of knowledge distillation (KD) recently. Nevertheless, how KD works in transformer-based models is still unclear. We tease apart the components of KD and propose a unified KD framework. Through the framework, systematic and extensive experiments that spent over 23,000 GPU hours render a comprehensive analysis from the perspectives of knowledge types, matching strategies, width-depth trade-off, initialization, model size, etc. Our empirical results shed light on the distillation in the pre-train language model and with relative significant improvement over previous state-of-the-arts(SOTA). Finally, we provide a best-practice guideline for the KD in transformer-based models.
Intelligent Request Strategy Design in Recommender System
Jun 23, 2022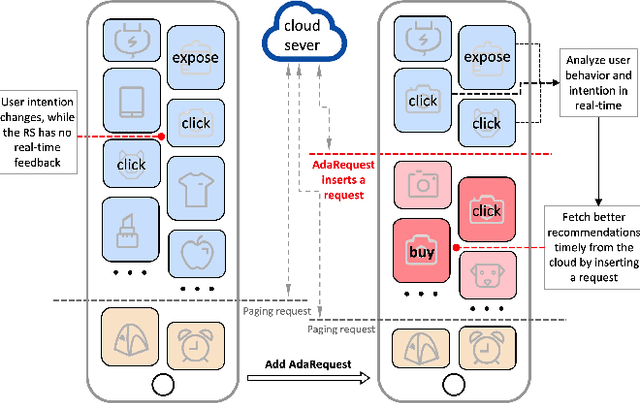

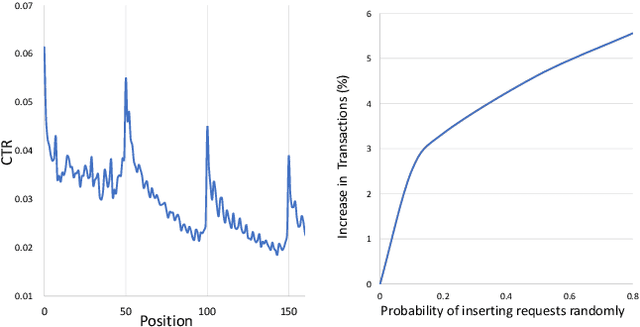
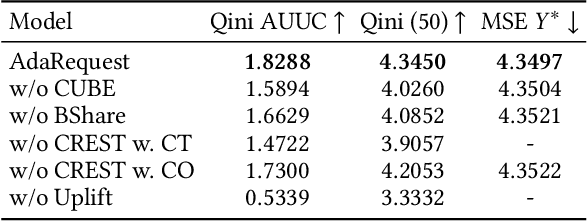
Waterfall Recommender System (RS), a popular form of RS in mobile applications, is a stream of recommended items consisting of successive pages that can be browsed by scrolling. In waterfall RS, when a user finishes browsing a page, the edge (e.g., mobile phones) would send a request to the cloud server to get a new page of recommendations, known as the paging request mechanism. RSs typically put a large number of items into one page to reduce excessive resource consumption from numerous paging requests, which, however, would diminish the RSs' ability to timely renew the recommendations according to users' real-time interest and lead to a poor user experience. Intuitively, inserting additional requests inside pages to update the recommendations with a higher frequency can alleviate the problem. However, previous attempts, including only non-adaptive strategies (e.g., insert requests uniformly), would eventually lead to resource overconsumption. To this end, we envision a new learning task of edge intelligence named Intelligent Request Strategy Design (IRSD). It aims to improve the effectiveness of waterfall RSs by determining the appropriate occasions of request insertion based on users' real-time intention. Moreover, we propose a new paradigm of adaptive request insertion strategy named Uplift-based On-edge Smart Request Framework (AdaRequest). AdaRequest 1) captures the dynamic change of users' intentions by matching their real-time behaviors with their historical interests based on attention-based neural networks. 2) estimates the counterfactual uplift of user purchase brought by an inserted request based on causal inference. 3) determines the final request insertion strategy by maximizing the utility function under online resource constraints. We conduct extensive experiments on both offline dataset and online A/B test to verify the effectiveness of AdaRequest.
Collaborative Intelligence Orchestration: Inconsistency-Based Fusion of Semi-Supervised Learning and Active Learning
Jun 07, 2022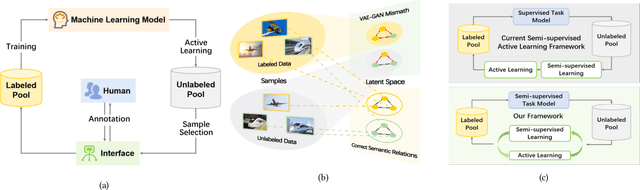
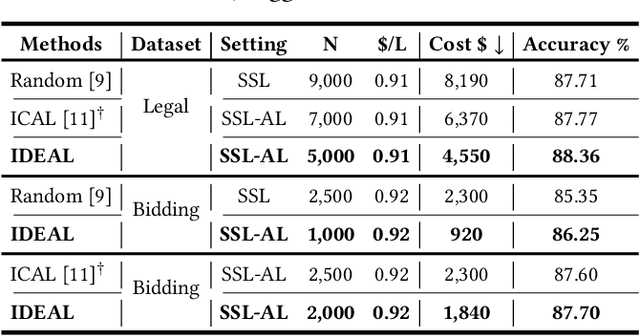
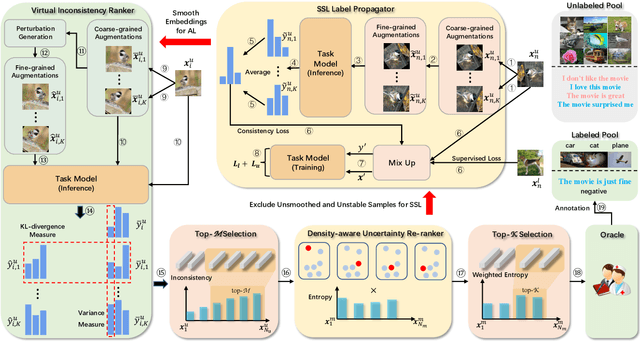
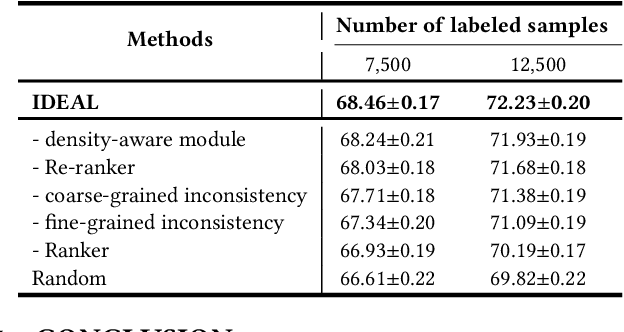
While annotating decent amounts of data to satisfy sophisticated learning models can be cost-prohibitive for many real-world applications. Active learning (AL) and semi-supervised learning (SSL) are two effective, but often isolated, means to alleviate the data-hungry problem. Some recent studies explored the potential of combining AL and SSL to better probe the unlabeled data. However, almost all these contemporary SSL-AL works use a simple combination strategy, ignoring SSL and AL's inherent relation. Further, other methods suffer from high computational costs when dealing with large-scale, high-dimensional datasets. Motivated by the industry practice of labeling data, we propose an innovative Inconsistency-based virtual aDvErsarial Active Learning (IDEAL) algorithm to further investigate SSL-AL's potential superiority and achieve mutual enhancement of AL and SSL, i.e., SSL propagates label information to unlabeled samples and provides smoothed embeddings for AL, while AL excludes samples with inconsistent predictions and considerable uncertainty for SSL. We estimate unlabeled samples' inconsistency by augmentation strategies of different granularities, including fine-grained continuous perturbation exploration and coarse-grained data transformations. Extensive experiments, in both text and image domains, validate the effectiveness of the proposed algorithm, comparing it against state-of-the-art baselines. Two real-world case studies visualize the practical industrial value of applying and deploying the proposed data sampling algorithm.
DE-Net: Dynamic Text-guided Image Editing Adversarial Networks
Jun 02, 2022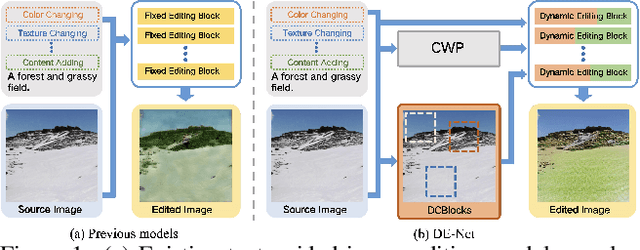
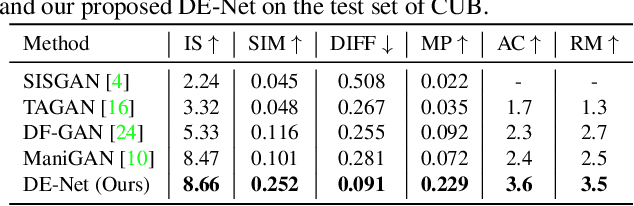
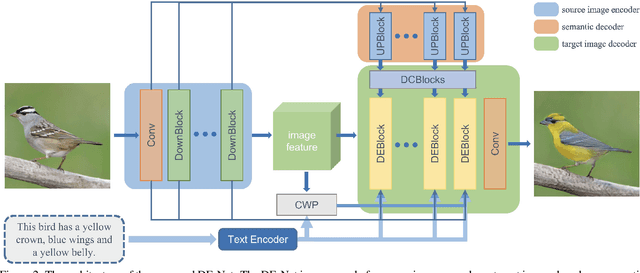
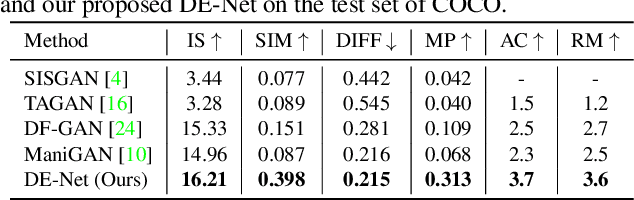
Text-guided image editing models have shown remarkable results. However, there remain two problems. First, they employ fixed manipulation modules for various editing requirements (e.g., color changing, texture changing, content adding and removing), which result in over-editing or insufficient editing. Second, they do not clearly distinguish between text-required parts and text-irrelevant parts, which leads to inaccurate editing. To solve these limitations, we propose: (i) a Dynamic Editing Block (DEBlock) which combines spatial- and channel-wise manipulations dynamically for various editing requirements. (ii) a Combination Weights Predictor (CWP) which predicts the combination weights for DEBlock according to the inference on text and visual features. (iii) a Dynamic text-adaptive Convolution Block (DCBlock) which queries source image features to distinguish text-required parts and text-irrelevant parts. Extensive experiments demonstrate that our DE-Net achieves excellent performance and manipulates source images more effectively and accurately. Code is available at \url{https://github.com/tobran/DE-Net}.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
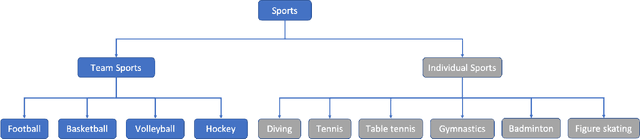
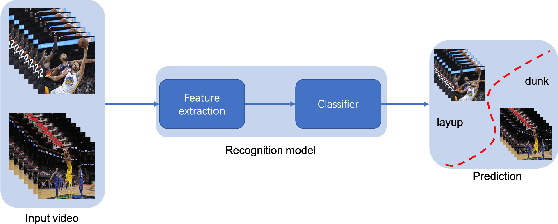
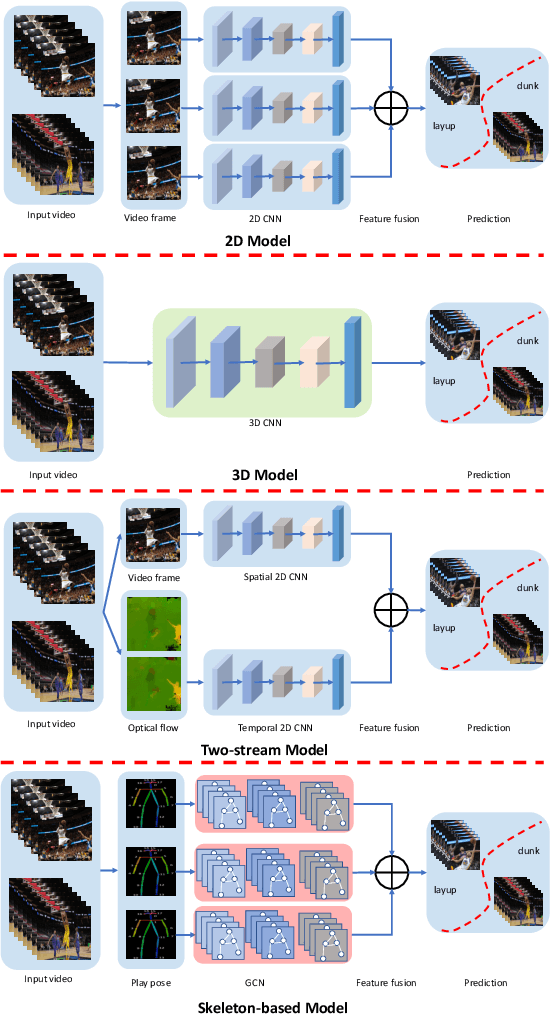
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning
May 30, 2022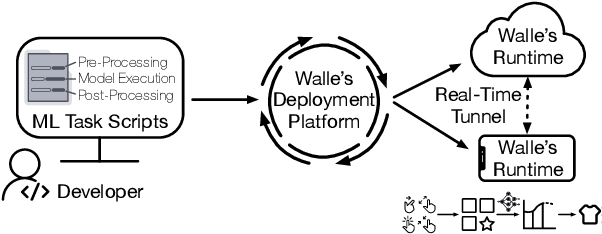
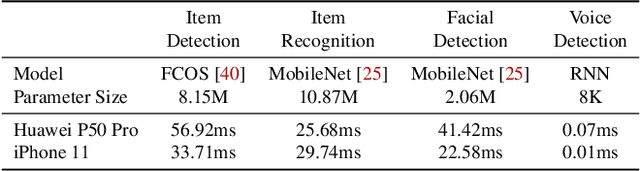
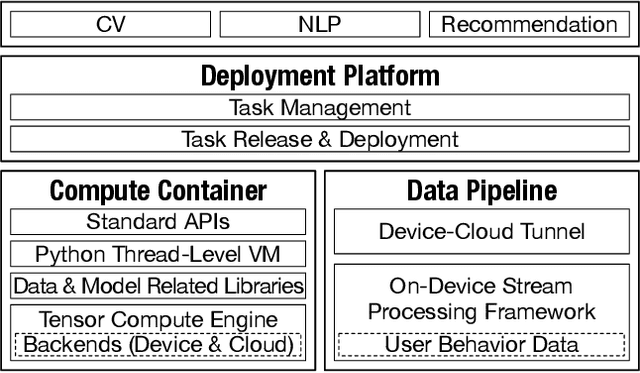

To break the bottlenecks of mainstream cloud-based machine learning (ML) paradigm, we adopt device-cloud collaborative ML and build the first end-to-end and general-purpose system, called Walle, as the foundation. Walle consists of a deployment platform, distributing ML tasks to billion-scale devices in time; a data pipeline, efficiently preparing task input; and a compute container, providing a cross-platform and high-performance execution environment, while facilitating daily task iteration. Specifically, the compute container is based on Mobile Neural Network (MNN), a tensor compute engine along with the data processing and model execution libraries, which are exposed through a refined Python thread-level virtual machine (VM) to support diverse ML tasks and concurrent task execution. The core of MNN is the novel mechanisms of operator decomposition and semi-auto search, sharply reducing the workload in manually optimizing hundreds of operators for tens of hardware backends and further quickly identifying the best backend with runtime optimization for a computation graph. The data pipeline introduces an on-device stream processing framework to enable processing user behavior data at source. The deployment platform releases ML tasks with an efficient push-then-pull method and supports multi-granularity deployment policies. We evaluate Walle in practical e-commerce application scenarios to demonstrate its effectiveness, efficiency, and scalability. Extensive micro-benchmarks also highlight the superior performance of MNN and the Python thread-level VM. Walle has been in large-scale production use in Alibaba, while MNN has been open source with a broad impact in the community.
RoSA: A Robust Self-Aligned Framework for Node-Node Graph Contrastive Learning
Apr 29, 2022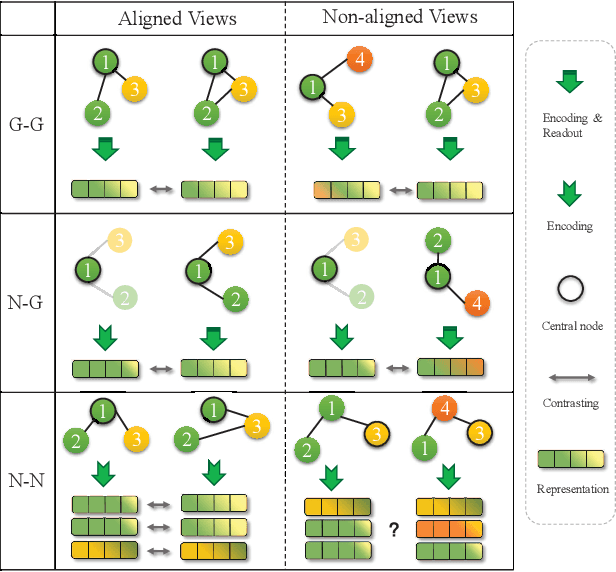
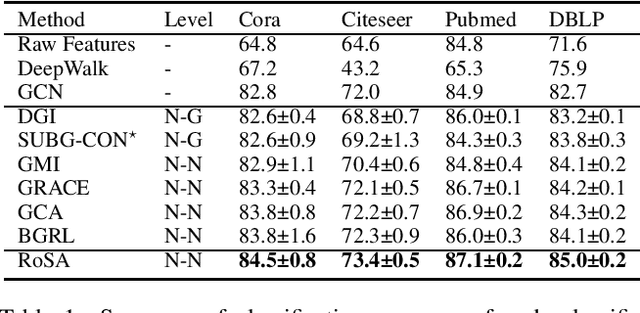
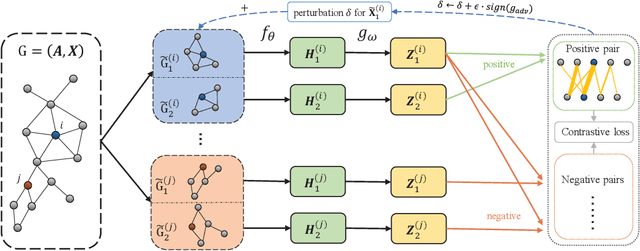
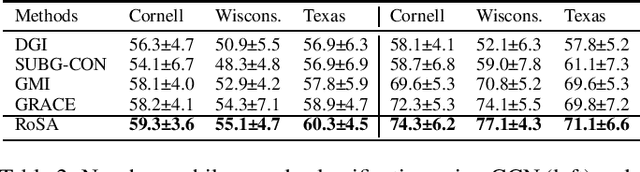
Graph contrastive learning has gained significant progress recently. However, existing works have rarely explored non-aligned node-node contrasting. In this paper, we propose a novel graph contrastive learning method named RoSA that focuses on utilizing non-aligned augmented views for node-level representation learning. First, we leverage the earth mover's distance to model the minimum effort to transform the distribution of one view to the other as our contrastive objective, which does not require alignment between views. Then we introduce adversarial training as an auxiliary method to increase sampling diversity and enhance the robustness of our model. Experimental results show that RoSA outperforms a series of graph contrastive learning frameworks on homophilous, non-homophilous and dynamic graphs, which validates the effectiveness of our work. To the best of our awareness, RoSA is the first work focuses on the non-aligned node-node graph contrastive learning problem. Our codes are available at: \href{https://github.com/ZhuYun97/RoSA}{\texttt{https://github.com/ZhuYun97/RoSA}}