 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study on Visual Token Redundancy for Discrete Diffusion-based Multimodal Large Language Models
Nov 19, 2025Discrete diffusion-based multimodal large language models (dMLLMs) have emerged as a promising alternative to autoregressive MLLMs thanks to their advantages in parallel decoding and bidirectional context modeling, but most existing dMLLMs incur significant computational overhead during inference due to the full-sequence attention computation in each denoising step. Pioneer studies attempt to resolve this issue from a modality-agnostic perspective via key-value cache optimization or efficient sampling but most of them overlook modality-specific visual token redundancy. In this work, we conduct a comprehensive study on how visual token redundancy evolves with different dMLLM architectures and tasks and how visual token pruning affects dMLLM responses and efficiency. Specifically, our study reveals that visual redundancy emerges only in from-scratch dMLLMs while handling long-answer tasks. In addition, we validate that visual token pruning introduces non-negligible information loss in dMLLMs and only from-scratch dMLLMs can recover the lost information progressively during late denoising steps. Furthermore, our study shows that layer-skipping is promising for accelerating AR-to-diffusion dMLLMs, whereas progressive or late-step pruning is more effective for from-scratch dMLLMs. Overall, this work offers a new perspective on efficiency optimization for dMLLMs, greatly advancing their applicability across various multimodal understanding tasks.
ToDRE: Visual Token Pruning via Diversity and Task Awareness for Efficient Large Vision-Language Models
May 24, 2025



The representation of visual inputs of large vision-language models (LVLMs) usually involves substantially more tokens than that of textual inputs, leading to significant computational overhead. Several recent studies strive to mitigate this issue by either conducting token compression to prune redundant visual tokens or guiding them to bypass certain computational stages. While most existing work exploits token importance as the redundancy indicator, our study reveals that two largely neglected factors, namely, the diversity of retained visual tokens and their task relevance, often offer more robust criteria in token pruning. To this end, we design ToDRE, a two-stage and training-free token compression framework that achieves superior performance by pruning Tokens based on token Diversity and token-task RElevance. Instead of pruning redundant tokens, ToDRE introduces a greedy k-center algorithm to select and retain a small subset of diverse visual tokens after the vision encoder. Additionally, ToDRE addresses the "information migration" by further eliminating task-irrelevant visual tokens within the decoder of large language model (LLM). Extensive experiments show that ToDRE effectively reduces 90% of visual tokens after vision encoder and adaptively prunes all visual tokens within certain LLM's decoder layers, leading to a 2.6x speed-up in total inference time while maintaining 95.1% of model performance and excellent compatibility with efficient attention operators.
Active Learning from Scene Embeddings for End-to-End Autonomous Driving
Mar 14, 2025



In the field of autonomous driving, end-to-end deep learning models show great potential by learning driving decisions directly from sensor data. However, training these models requires large amounts of labeled data, which is time-consuming and expensive. Considering that the real-world driving data exhibits a long-tailed distribution where simple scenarios constitute a majority part of the data, we are thus inspired to identify the most challenging scenarios within it. Subsequently, we can efficiently improve the performance of the model by training with the selected data of the highest value. Prior research has focused on the selection of valuable data by empirically designed strategies. However, manually designed methods suffer from being less generalizable to new data distributions. Observing that the BEV (Bird's Eye View) features in end-to-end models contain all the information required to represent the scenario, we propose an active learning framework that relies on these vectorized scene-level features, called SEAD. The framework selects initial data based on driving-environmental information and incremental data based on BEV features. Experiments show that we only need 30\% of the nuScenes training data to achieve performance close to what can be achieved with the full dataset. The source code will be released.
Anti-bullying Adaptive Cruise Control: A proactive right-of-way protection approach
Dec 14, 2024



The current Adaptive Cruise Control (ACC) systems are vulnerable to "road bully" such as cut-ins. This paper proposed an Anti-bullying Adaptive Cruise Control (AACC) approach with proactive right-of-way protection ability. It bears the following features: i) with the enhanced capability of preventing bullying from cut-ins; ii) optimal but not unsafe; iii) adaptive to various driving styles of cut-in vehicles; iv) with real-time field implementation capability. The proposed approach can identify other road users' driving styles online and conduct game-based motion planning for right-of-way protection. A detailed investigation of the simulation results shows that the proposed approach can prevent bullying from cut-ins and be adaptive to different cut-in vehicles' driving styles. The proposed approach is capable of enhancing travel efficiency by up to 29.55% under different cut-in gaps and can strengthen driving safety compared with the current ACC controller. The proposed approach is flexible and robust against traffic congestion levels. It can improve mobility by up to 11.93% and robustness by 8.74% in traffic flow. Furthermore, the proposed approach can support real-time field implementation by ensuring less than 50 milliseconds computation time.
Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators
Aug 11, 2024



This paper identifies significant redundancy in the query-key interactions within self-attention mechanisms of diffusion transformer models, particularly during the early stages of denoising diffusion steps. In response to this observation, we present a novel diffusion transformer framework incorporating an additional set of mediator tokens to engage with queries and keys separately. By modulating the number of mediator tokens during the denoising generation phases, our model initiates the denoising process with a precise, non-ambiguous stage and gradually transitions to a phase enriched with detail. Concurrently, integrating mediator tokens simplifies the attention module's complexity to a linear scale, enhancing the efficiency of global attention processes. Additionally, we propose a time-step dynamic mediator token adjustment mechanism that further decreases the required computational FLOPs for generation, simultaneously facilitating the generation of high-quality images within the constraints of varied inference budgets. Extensive experiments demonstrate that the proposed method can improve the generated image quality while also reducing the inference cost of diffusion transformers. When integrated with the recent work SiT, our method achieves a state-of-the-art FID score of 2.01. The source code is available at https://github.com/LeapLabTHU/Attention-Mediators.
Accelerating the Evolution of Personalized Automated Lane Change through Lesson Learning
May 13, 2024



Personalization is crucial for the widespread adoption of advanced driver assistance system. To match up with each user's preference, the online evolution capability is a must. However, conventional evolution methods learn from naturalistic driving data, which requires a lot computing power and cannot be applied online. To address this challenge, this paper proposes a lesson learning approach: learning from driver's takeover interventions. By leveraging online takeover data, the driving zone is generated to ensure perceived safety using Gaussian discriminant analysis. Real-time corrections to trajectory planning rewards are enacted through apprenticeship learning. Guided by the objective of optimizing rewards within the constraints of the driving zone, this approach employs model predictive control for trajectory planning. This lesson learning framework is highlighted for its faster evolution capability, adeptness at experience accumulating, assurance of perceived safety, and computational efficiency. Simulation results demonstrate that the proposed system consistently achieves a successful customization without further takeover interventions. Accumulated experience yields a 24% enhancement in evolution efficiency. The average number of learning iterations is only 13.8. The average computation time is 0.08 seconds.
Space Domain based Ecological Cooperative and Adaptive Cruise Control on Rolling Terrain
May 13, 2024Ecological Cooperative and Adaptive Cruise Control (Eco-CACC) is widely focused to enhance sustainability of CACC. However, state-of-the-art Eco-CACC studies are still facing challenges in adopting on rolling terrain. Furthermore, they cannot ensure both ecology optimality and computational efficiency. Hence, this paper proposes a nonlinear optimal control based Eco-CACC controller. It has the following features: i) enhancing performance across rolling terrains by modeling in space domain; ii) enhancing fuel efficiency via globally optimizing all vehicle's fuel consumptions; iii) ensuring computational efficiency by developing a differential dynamic programming-based solving method for the non-linear optimal control problem; iv) ensuring string stability through theoretically proving and experimentally validating. The performance of the proposed Eco-CACC controller was evaluated. Results showed that the proposed Eco-CACC controller can improve average fuel saving by 37.67% at collector road and about 17.30% at major arterial.
Few-Shot Class-Incremental Learning with Prior Knowledge
Feb 02, 2024To tackle the issues of catastrophic forgetting and overfitting in few-shot class-incremental learning (FSCIL), previous work has primarily concentrated on preserving the memory of old knowledge during the incremental phase. The role of pre-trained model in shaping the effectiveness of incremental learning is frequently underestimated in these studies. Therefore, to enhance the generalization ability of the pre-trained model, we propose Learning with Prior Knowledge (LwPK) by introducing nearly free prior knowledge from a few unlabeled data of subsequent incremental classes. We cluster unlabeled incremental class samples to produce pseudo-labels, then jointly train these with labeled base class samples, effectively allocating embedding space for both old and new class data. Experimental results indicate that LwPK effectively enhances the model resilience against catastrophic forgetting, with theoretical analysis based on empirical risk minimization and class distance measurement corroborating its operational principles. The source code of LwPK is publicly available at: \url{https://github.com/StevenJ308/LwPK}.
Uncertainty-aware Sampling for Long-tailed Semi-supervised Learning
Jan 09, 2024For semi-supervised learning with imbalance classes, the long-tailed distribution of data will increase the model prediction bias toward dominant classes, undermining performance on less frequent classes. Existing methods also face challenges in ensuring the selection of sufficiently reliable pseudo-labels for model training and there is a lack of mechanisms to adjust the selection of more reliable pseudo-labels based on different training stages. To mitigate this issue, we introduce uncertainty into the modeling process for pseudo-label sampling, taking into account that the model performance on the tailed classes varies over different training stages. For example, at the early stage of model training, the limited predictive accuracy of model results in a higher rate of uncertain pseudo-labels. To counter this, we propose an Uncertainty-Aware Dynamic Threshold Selection (UDTS) approach. This approach allows the model to perceive the uncertainty of pseudo-labels at different training stages, thereby adaptively adjusting the selection thresholds for different classes. Compared to other methods such as the baseline method FixMatch, UDTS achieves an increase in accuracy of at least approximately 5.26%, 1.75%, 9.96%, and 1.28% on the natural scene image datasets CIFAR10-LT, CIFAR100-LT, STL-10-LT, and the medical image dataset TissueMNIST, respectively. The source code of UDTS is publicly available at: https://github.com/yangk/UDTS.
E2-AEN: End-to-End Incremental Learning with Adaptively Expandable Network
Jul 14, 2022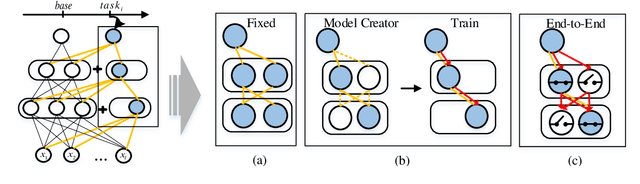
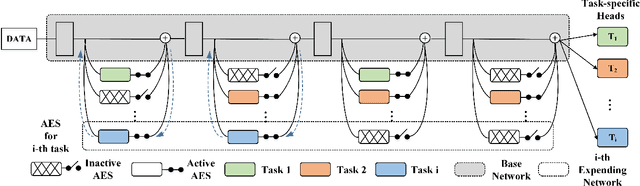
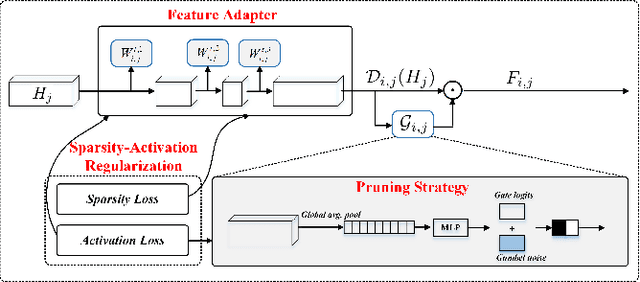
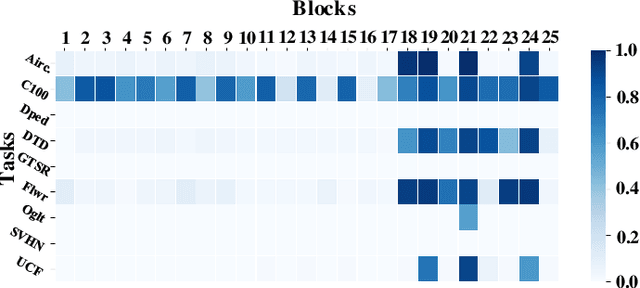
Expandable networks have demonstrated their advantages in dealing with catastrophic forgetting problem in incremental learning. Considering that different tasks may need different structures, recent methods design dynamic structures adapted to different tasks via sophisticated skills. Their routine is to search expandable structures first and then train on the new tasks, which, however, breaks tasks into multiple training stages, leading to suboptimal or overmuch computational cost. In this paper, we propose an end-to-end trainable adaptively expandable network named E2-AEN, which dynamically generates lightweight structures for new tasks without any accuracy drop in previous tasks. Specifically, the network contains a serial of powerful feature adapters for augmenting the previously learned representations to new tasks, and avoiding task interference. These adapters are controlled via an adaptive gate-based pruning strategy which decides whether the expanded structures can be pruned, making the network structure dynamically changeable according to the complexity of the new tasks. Moreover, we introduce a novel sparsity-activation regularization to encourage the model to learn discriminative features with limited parameters. E2-AEN reduces cost and can be built upon any feed-forward architectures in an end-to-end manner. Extensive experiments on both classification (i.e., CIFAR and VDD) and detection (i.e., COCO, VOC and ICCV2021 SSLAD challenge) benchmarks demonstrate the effectiveness of the proposed method, which achieves the new remarkable results.