 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Butterfly Effect in Pathology: Exploring Security in Pathology Foundation Models
May 30, 2025With the widespread adoption of pathology foundation models in both research and clinical decision support systems, exploring their security has become a critical concern. However, despite their growing impact, the vulnerability of these models to adversarial attacks remains largely unexplored. In this work, we present the first systematic investigation into the security of pathology foundation models for whole slide image~(WSI) analysis against adversarial attacks. Specifically, we introduce the principle of \textit{local perturbation with global impact} and propose a label-free attack framework that operates without requiring access to downstream task labels. Under this attack framework, we revise four classical white-box attack methods and redefine the perturbation budget based on the characteristics of WSI. We conduct comprehensive experiments on three representative pathology foundation models across five datasets and six downstream tasks. Despite modifying only 0.1\% of patches per slide with imperceptible noise, our attack leads to downstream accuracy degradation that can reach up to 20\% in the worst cases. Furthermore, we analyze key factors that influence attack success, explore the relationship between patch-level vulnerability and semantic content, and conduct a preliminary investigation into potential defence strategies. These findings lay the groundwork for future research on the adversarial robustness and reliable deployment of pathology foundation models. Our code is publicly available at: https://github.com/Jiashuai-Liu-hmos/Attack-WSI-pathology-foundation-models.
ST-Prompt Guided Histological Hypergraph Learning for Spatial Gene Expression Prediction
Mar 21, 2025



Spatial Transcriptomics (ST) reveals the spatial distribution of gene expression in tissues, offering critical insights into biological processes and disease mechanisms. However, predicting ST from H\&E-stained histology images is challenging due to the heterogeneous relationship between histomorphology and gene expression, which arises from substantial variability across different patients and tissue sections. A more practical and valuable approach is to utilize ST data from a few local regions to predict the spatial transcriptomic landscape across the remaining regions in H&E slides. In response, we propose PHG2ST, an ST-prompt guided histological hypergraph learning framework, which leverages sparse ST signals as prompts to guide histological hypergraph learning for global spatial gene expression prediction. Our framework fuses histological hypergraph representations at multiple scales through a masked ST-prompt encoding mechanism, improving robustness and generalizability. Benchmark evaluations on two public ST datasets demonstrate that PHG2ST outperforms the existing state-of-the-art methods and closely aligns with the ground truth. These results underscore the potential of leveraging sparse local ST data for scalable and cost-effective spatial gene expression mapping in real-world biomedical applications.
Adaptive Progressive Attention Graph Neural Network for EEG Emotion Recognition
Jan 24, 2025In recent years, numerous neuroscientific studies have shown that human emotions are closely linked to specific brain regions, with these regions exhibiting variability across individuals and emotional states. To fully leverage these neural patterns, we propose an Adaptive Progressive Attention Graph Neural Network (APAGNN), which dynamically captures the spatial relationships among brain regions during emotional processing. The APAGNN employs three specialized experts that progressively analyze brain topology. The first expert captures global brain patterns, the second focuses on region-specific features, and the third examines emotion-related channels. This hierarchical approach enables increasingly refined analysis of neural activity. Additionally, a weight generator integrates the outputs of all three experts, balancing their contributions to produce the final predictive label. Extensive experiments on three publicly available datasets (SEED, SEED-IV and MPED) demonstrate that the proposed method enhances EEG emotion recognition performance, achieving superior results compared to baseline methods.
Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation
Jul 18, 2024



Current weakly-supervised incremental learning for semantic segmentation (WILSS) approaches only consider replacing pixel-level annotations with image-level labels, while the training images are still from well-designed datasets. In this work, we argue that widely available web images can also be considered for the learning of new classes. To achieve this, firstly we introduce a strategy to select web images which are similar to previously seen examples in the latent space using a Fourier-based domain discriminator. Then, an effective caption-driven reharsal strategy is proposed to preserve previously learnt classes. To our knowledge, this is the first work to rely solely on web images for both the learning of new concepts and the preservation of the already learned ones in WILSS. Experimental results show that the proposed approach can reach state-of-the-art performances without using manually selected and annotated data in the incremental steps.
MOSE: Boosting Vision-based Roadside 3D Object Detection with Scene Cues
Apr 08, 2024



3D object detection based on roadside cameras is an additional way for autonomous driving to alleviate the challenges of occlusion and short perception range from vehicle cameras. Previous methods for roadside 3D object detection mainly focus on modeling the depth or height of objects, neglecting the stationary of cameras and the characteristic of inter-frame consistency. In this work, we propose a novel framework, namely MOSE, for MOnocular 3D object detection with Scene cuEs. The scene cues are the frame-invariant scene-specific features, which are crucial for object localization and can be intuitively regarded as the height between the surface of the real road and the virtual ground plane. In the proposed framework, a scene cue bank is designed to aggregate scene cues from multiple frames of the same scene with a carefully designed extrinsic augmentation strategy. Then, a transformer-based decoder lifts the aggregated scene cues as well as the 3D position embeddings for 3D object location, which boosts generalization ability in heterologous scenes. The extensive experiment results on two public benchmarks demonstrate the state-of-the-art performance of the proposed method, which surpasses the existing methods by a large margin.
Retinex-guided Channel-grouping based Patch Swap for Arbitrary Style Transfer
Sep 19, 2023



The basic principle of the patch-matching based style transfer is to substitute the patches of the content image feature maps by the closest patches from the style image feature maps. Since the finite features harvested from one single aesthetic style image are inadequate to represent the rich textures of the content natural image, existing techniques treat the full-channel style feature patches as simple signal tensors and create new style feature patches via signal-level fusion, which ignore the implicit diversities existed in style features and thus fail for generating better stylised results. In this paper, we propose a Retinex theory guided, channel-grouping based patch swap technique to solve the above challenges. Channel-grouping strategy groups the style feature maps into surface and texture channels, which prevents the winner-takes-all problem. Retinex theory based decomposition controls a more stable channel code rate generation. In addition, we provide complementary fusion and multi-scale generation strategy to prevent unexpected black area and over-stylised results respectively. Experimental results demonstrate that the proposed method outperforms the existing techniques in providing more style-consistent textures while keeping the content fidelity.
RECALL+: Adversarial Web-based Replay for Continual Learning in Semantic Segmentation
Sep 19, 2023Catastrophic forgetting of previous knowledge is a critical issue in continual learning typically handled through various regularization strategies. However, existing methods struggle especially when several incremental steps are performed. In this paper, we extend our previous approach (RECALL) and tackle forgetting by exploiting unsupervised web-crawled data to retrieve examples of old classes from online databases. Differently from the original approach that did not perform any evaluation of the web data, here we introduce two novel approaches based on adversarial learning and adaptive thresholding to select from web data only samples strongly resembling the statistics of the no longer available training ones. Furthermore, we improved the pseudo-labeling scheme to achieve a more accurate labeling of web data that also consider classes being learned in the current step. Experimental results show that this enhanced approach achieves remarkable results, especially when multiple incremental learning steps are performed.
Distilling Object Detectors With Global Knowledge
Oct 17, 2022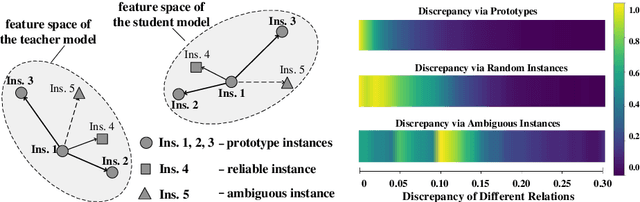
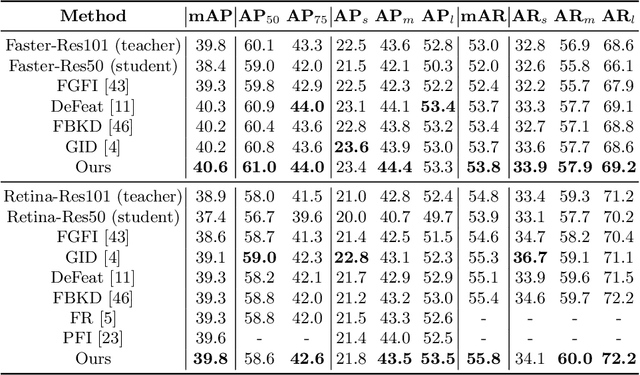
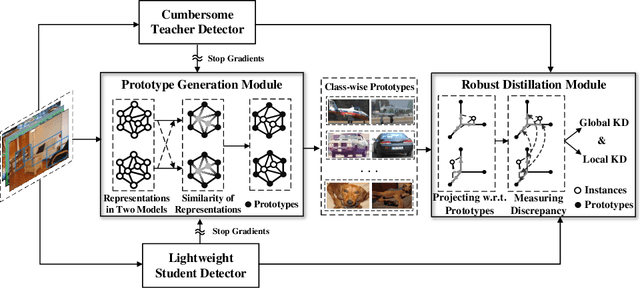
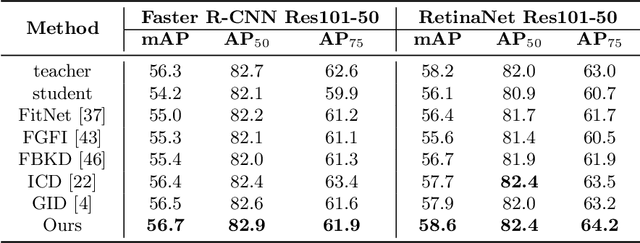
Knowledge distillation learns a lightweight student model that mimics a cumbersome teacher. Existing methods regard the knowledge as the feature of each instance or their relations, which is the instance-level knowledge only from the teacher model, i.e., the local knowledge. However, the empirical studies show that the local knowledge is much noisy in object detection tasks, especially on the blurred, occluded, or small instances. Thus, a more intrinsic approach is to measure the representations of instances w.r.t. a group of common basis vectors in the two feature spaces of the teacher and the student detectors, i.e., global knowledge. Then, the distilling algorithm can be applied as space alignment. To this end, a novel prototype generation module (PGM) is proposed to find the common basis vectors, dubbed prototypes, in the two feature spaces. Then, a robust distilling module (RDM) is applied to construct the global knowledge based on the prototypes and filtrate noisy global and local knowledge by measuring the discrepancy of the representations in two feature spaces. Experiments with Faster-RCNN and RetinaNet on PASCAL and COCO datasets show that our method achieves the best performance for distilling object detectors with various backbones, which even surpasses the performance of the teacher model. We also show that the existing methods can be easily combined with global knowledge and obtain further improvement. Code is available: https://github.com/hikvision-research/DAVAR-Lab-ML.
Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting
Jul 15, 2022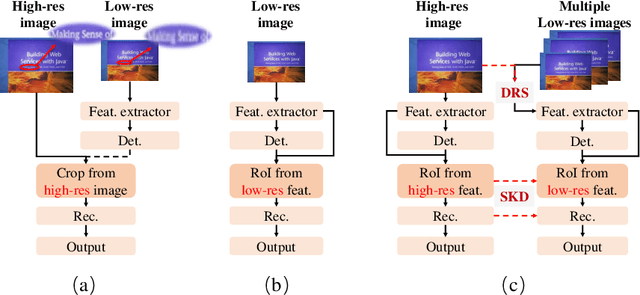
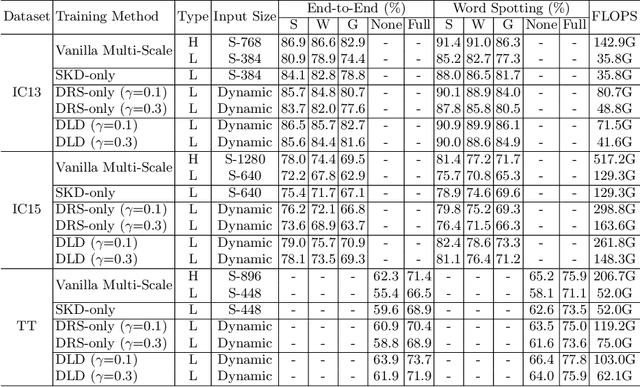
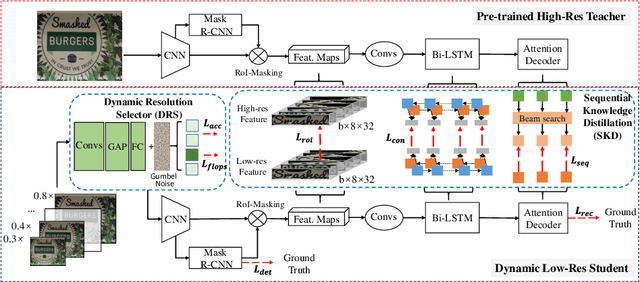
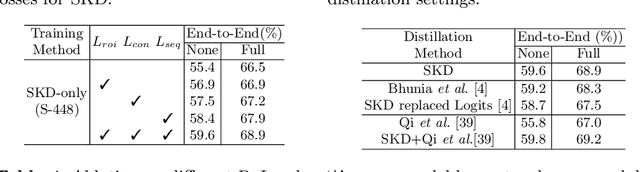
End-to-end text spotting has attached great attention recently due to its benefits on global optimization and high maintainability for real applications. However, the input scale has always been a tough trade-off since recognizing a small text instance usually requires enlarging the whole image, which brings high computational costs. In this paper, to address this problem, we propose a novel cost-efficient Dynamic Low-resolution Distillation (DLD) text spotting framework, which aims to infer images in different small but recognizable resolutions and achieve a better balance between accuracy and efficiency. Concretely, we adopt a resolution selector to dynamically decide the input resolutions for different images, which is constraint by both inference accuracy and computational cost. Another sequential knowledge distillation strategy is conducted on the text recognition branch, making the low-res input obtains comparable performance to a high-res image. The proposed method can be optimized end-to-end and adopted in any current text spotting framework to improve the practicability. Extensive experiments on several text spotting benchmarks show that the proposed method vastly improves the usability of low-res models. The code is available at https://github.com/hikopensource/DAVAR-Lab-OCR/.
E2-AEN: End-to-End Incremental Learning with Adaptively Expandable Network
Jul 14, 2022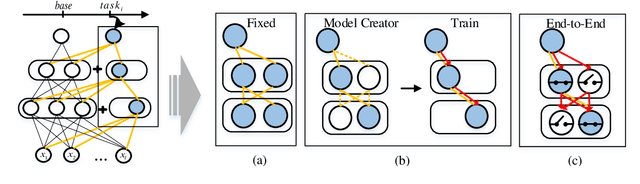
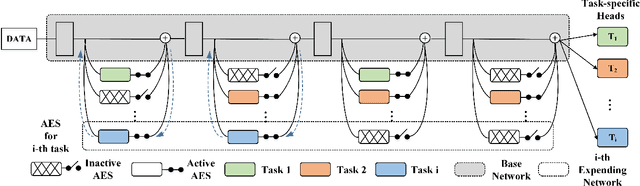
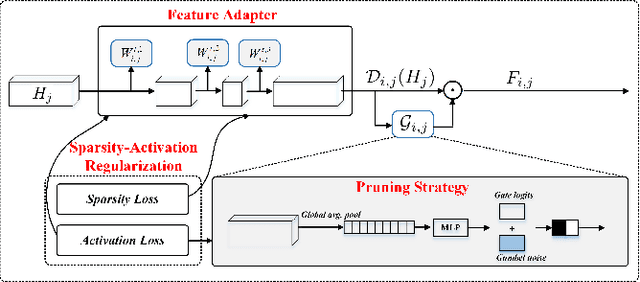
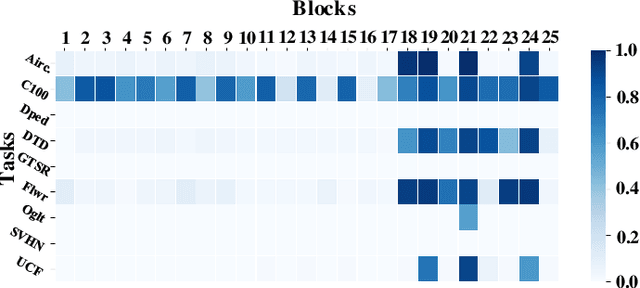
Expandable networks have demonstrated their advantages in dealing with catastrophic forgetting problem in incremental learning. Considering that different tasks may need different structures, recent methods design dynamic structures adapted to different tasks via sophisticated skills. Their routine is to search expandable structures first and then train on the new tasks, which, however, breaks tasks into multiple training stages, leading to suboptimal or overmuch computational cost. In this paper, we propose an end-to-end trainable adaptively expandable network named E2-AEN, which dynamically generates lightweight structures for new tasks without any accuracy drop in previous tasks. Specifically, the network contains a serial of powerful feature adapters for augmenting the previously learned representations to new tasks, and avoiding task interference. These adapters are controlled via an adaptive gate-based pruning strategy which decides whether the expanded structures can be pruned, making the network structure dynamically changeable according to the complexity of the new tasks. Moreover, we introduce a novel sparsity-activation regularization to encourage the model to learn discriminative features with limited parameters. E2-AEN reduces cost and can be built upon any feed-forward architectures in an end-to-end manner. Extensive experiments on both classification (i.e., CIFAR and VDD) and detection (i.e., COCO, VOC and ICCV2021 SSLAD challenge) benchmarks demonstrate the effectiveness of the proposed method, which achieves the new remarkable results.