 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Text Hashing: Efficient Semantic Text Retrieval with Binary Representation
Oct 31, 2025



With the rapid growth of textual content on the Internet, efficient large-scale semantic text retrieval has garnered increasing attention from both academia and industry. Text hashing, which projects original texts into compact binary hash codes, is a crucial method for this task. By using binary codes, the semantic similarity computation for text pairs is significantly accelerated via fast Hamming distance calculations, and storage costs are greatly reduced. With the advancement of deep learning, deep text hashing has demonstrated significant advantages over traditional, data-independent hashing techniques. By leveraging deep neural networks, these methods can learn compact and semantically rich binary representations directly from data, overcoming the performance limitations of earlier approaches. This survey investigates current deep text hashing methods by categorizing them based on their core components: semantic extraction, hash code quality preservation, and other key technologies. We then present a detailed evaluation schema with results on several popular datasets, followed by a discussion of practical applications and open-source tools for implementation. Finally, we conclude by discussing key challenges and future research directions, including the integration of deep text hashing with large language models to further advance the field. The project for this survey can be accessed at https://github.com/hly1998/DeepTextHashing.
A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Sep 26, 2025



Recent Large Reasoning Models have achieved significant improvements in complex task-solving capabilities by allocating more computation at the inference stage with a "thinking longer" paradigm. Even as the foundational reasoning capabilities of models advance rapidly, the persistent gap between a model's performance in a single attempt and its latent potential, often revealed only across multiple solution paths, starkly highlights the disparity between its realized and inherent capabilities. To address this, we present A2R, an Asymmetric Two-Stage Reasoning framework designed to explicitly bridge the gap between a model's potential and its actual performance. In this framework, an "explorer" model first generates potential solutions in parallel through repeated sampling. Subsequently,a "synthesizer" model integrates these references for a more refined, second stage of reasoning. This two-stage process allows computation to be scaled orthogonally to existing sequential methods. Our work makes two key innovations: First, we present A2R as a plug-and-play parallel reasoning framework that explicitly enhances a model's capabilities on complex questions. For example, using our framework, the Qwen3-8B-distill model achieves a 75% performance improvement compared to its self-consistency baseline. Second, through a systematic analysis of the explorer and synthesizer roles, we identify an effective asymmetric scaling paradigm. This insight leads to A2R-Efficient, a "small-to-big" variant that combines a Qwen3-4B explorer with a Qwen3-8B synthesizer. This configuration surpasses the average performance of a monolithic Qwen3-32B model at a nearly 30% lower cost. Collectively, these results show that A2R is not only a performance-boosting framework but also an efficient and practical solution for real-world applications.
LLM Cache Bandit Revisited: Addressing Query Heterogeneity for Cost-Effective LLM Inference
Sep 19, 2025This paper revisits the LLM cache bandit problem, with a special focus on addressing the query heterogeneity for cost-effective LLM inference. Previous works often assume uniform query sizes. Heterogeneous query sizes introduce a combinatorial structure for cache selection, making the cache replacement process more computationally and statistically challenging. We treat optimal cache selection as a knapsack problem and employ an accumulation-based strategy to effectively balance computational overhead and cache updates. In theoretical analysis, we prove that the regret of our algorithm achieves an $O(\sqrt{MNT})$ bound, improving the coefficient of $\sqrt{MN}$ compared to the $O(MN\sqrt{T})$ result in Berkeley, where $N$ is the total number of queries and $M$ is the cache size. Additionally, we also provide a problem-dependent bound, which was absent in previous works. The experiment rely on real-world data show that our algorithm reduces the total cost by approximately 12\%.
Composable Score-based Graph Diffusion Model for Multi-Conditional Molecular Generation
Sep 11, 2025Controllable molecular graph generation is essential for material and drug discovery, where generated molecules must satisfy diverse property constraints. While recent advances in graph diffusion models have improved generation quality, their effectiveness in multi-conditional settings remains limited due to reliance on joint conditioning or continuous relaxations that compromise fidelity. To address these limitations, we propose Composable Score-based Graph Diffusion model (CSGD), the first model that extends score matching to discrete graphs via concrete scores, enabling flexible and principled manipulation of conditional guidance. Building on this foundation, we introduce two score-based techniques: Composable Guidance (CoG), which allows fine-grained control over arbitrary subsets of conditions during sampling, and Probability Calibration (PC), which adjusts estimated transition probabilities to mitigate train-test mismatches. Empirical results on four molecular datasets show that CSGD achieves state-of-the-art performance, with a 15.3% average improvement in controllability over prior methods, while maintaining high validity and distributional fidelity. Our findings highlight the practical advantages of score-based modeling for discrete graph generation and its capacity for flexible, multi-property molecular design.
SelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025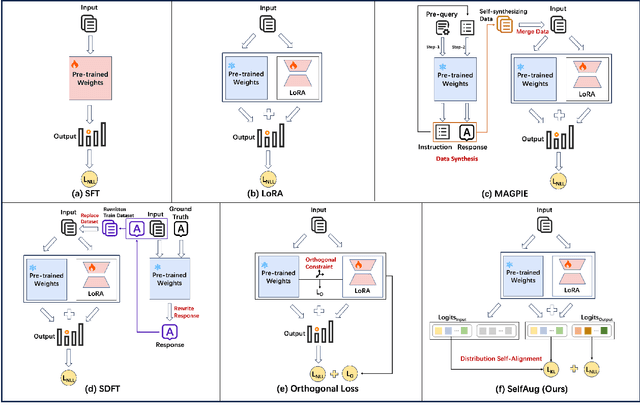
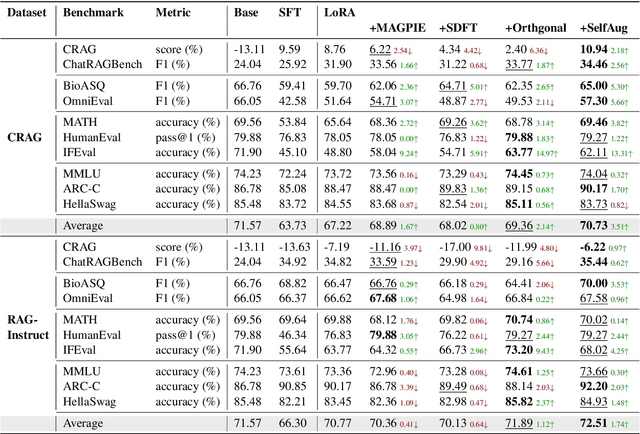
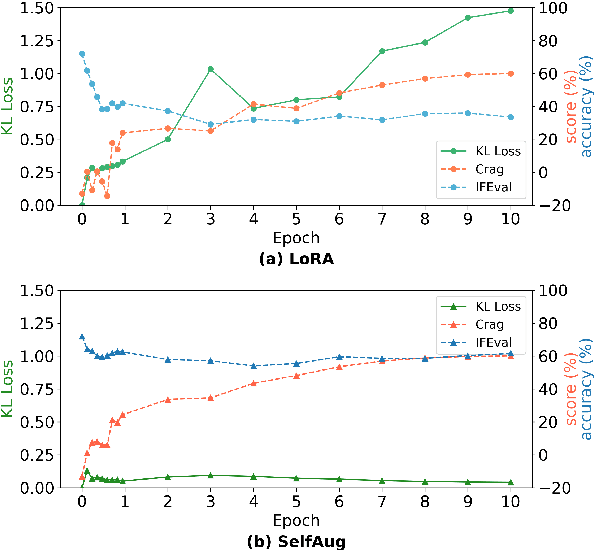
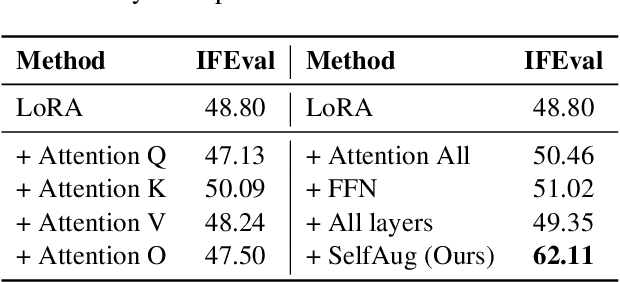
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
Preference Trajectory Modeling via Flow Matching for Sequential Recommendation
Aug 25, 2025



Sequential recommendation predicts each user's next item based on their historical interaction sequence. Recently, diffusion models have attracted significant attention in this area due to their strong ability to model user interest distributions. They typically generate target items by denoising Gaussian noise conditioned on historical interactions. However, these models face two critical limitations. First, they exhibit high sensitivity to the condition, making it difficult to recover target items from pure Gaussian noise. Second, the inference process is computationally expensive, limiting practical deployment. To address these issues, we propose FlowRec, a simple yet effective sequential recommendation framework which leverages flow matching to explicitly model user preference trajectories from current states to future interests. Flow matching is an emerging generative paradigm, which offers greater flexibility in initial distributions and enables more efficient sampling. Based on this, we construct a personalized behavior-based prior distribution to replace Gaussian noise and learn a vector field to model user preference trajectories. To better align flow matching with the recommendation objective, we further design a single-step alignment loss incorporating both positive and negative samples, improving sampling efficiency and generation quality. Extensive experiments on four benchmark datasets verify the superiority of FlowRec over the state-of-the-art baselines.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025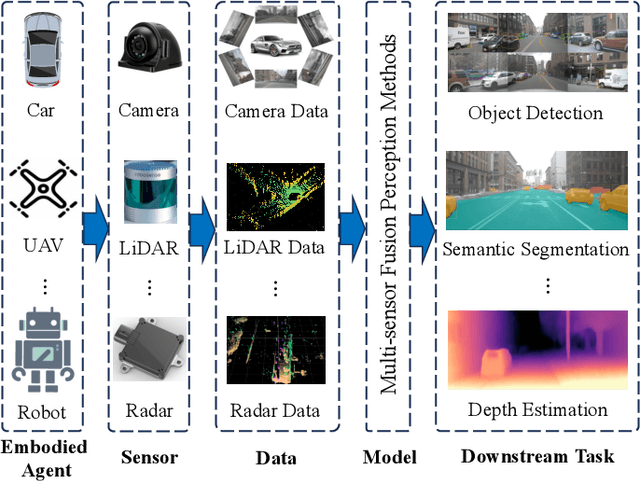
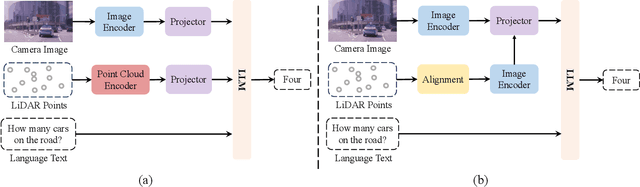
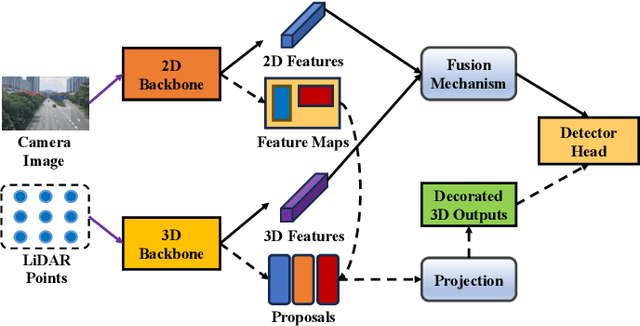
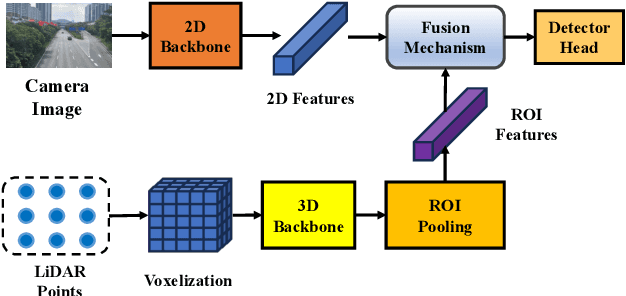
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
Bind-Your-Avatar: Multi-Talking-Character Video Generation with Dynamic 3D-mask-based Embedding Router
Jun 24, 2025
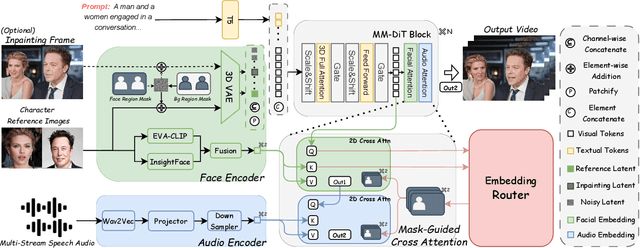
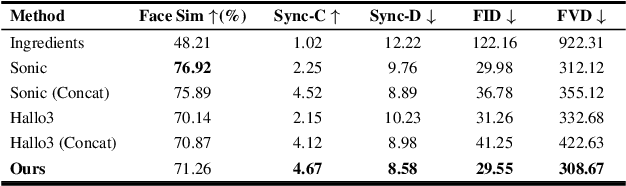
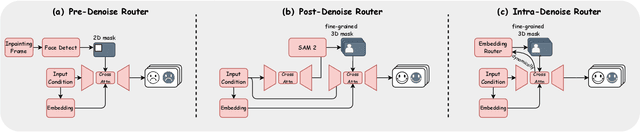
Recent years have witnessed remarkable advances in audio-driven talking head generation. However, existing approaches predominantly focus on single-character scenarios. While some methods can create separate conversation videos between two individuals, the critical challenge of generating unified conversation videos with multiple physically co-present characters sharing the same spatial environment remains largely unaddressed. This setting presents two key challenges: audio-to-character correspondence control and the lack of suitable datasets featuring multi-character talking videos within the same scene. To address these challenges, we introduce Bind-Your-Avatar, an MM-DiT-based model specifically designed for multi-talking-character video generation in the same scene. Specifically, we propose (1) A novel framework incorporating a fine-grained Embedding Router that binds `who' and `speak what' together to address the audio-to-character correspondence control. (2) Two methods for implementing a 3D-mask embedding router that enables frame-wise, fine-grained control of individual characters, with distinct loss functions based on observed geometric priors and a mask refinement strategy to enhance the accuracy and temporal smoothness of the predicted masks. (3) The first dataset, to the best of our knowledge, specifically constructed for multi-talking-character video generation, and accompanied by an open-source data processing pipeline, and (4) A benchmark for the dual-talking-characters video generation, with extensive experiments demonstrating superior performance over multiple state-of-the-art methods.
Benchmarking Multimodal LLMs on Recognition and Understanding over Chemical Tables
Jun 13, 2025Chemical tables encode complex experimental knowledge through symbolic expressions, structured variables, and embedded molecular graphics. Existing benchmarks largely overlook this multimodal and domain-specific complexity, limiting the ability of multimodal large language models to support scientific understanding in chemistry. In this work, we introduce ChemTable, a large-scale benchmark of real-world chemical tables curated from the experimental sections of literature. ChemTable includes expert-annotated cell polygons, logical layouts, and domain-specific labels, including reagents, catalysts, yields, and graphical components and supports two core tasks: (1) Table Recognition, covering structure parsing and content extraction; and (2) Table Understanding, encompassing both descriptive and reasoning-oriented question answering grounded in table structure and domain semantics. We evaluated a range of representative multimodal models, including both open-source and closed-source models, on ChemTable and reported a series of findings with practical and conceptual insights. Although models show reasonable performance on basic layout parsing, they exhibit substantial limitations on both descriptive and inferential QA tasks compared to human performance, and we observe significant performance gaps between open-source and closed-source models across multiple dimensions. These results underscore the challenges of chemistry-aware table understanding and position ChemTable as a rigorous and realistic benchmark for advancing scientific reasoning.
NDCG-Consistent Softmax Approximation with Accelerated Convergence
Jun 11, 2025



Ranking tasks constitute fundamental components of extreme similarity learning frameworks, where extremely large corpora of objects are modeled through relative similarity relationships adhering to predefined ordinal structures. Among various ranking surrogates, Softmax (SM) Loss has been widely adopted due to its natural capability to handle listwise ranking via global negative comparisons, along with its flexibility across diverse application scenarios. However, despite its effectiveness, SM Loss often suffers from significant computational overhead and scalability limitations when applied to large-scale object spaces. To address this challenge, we propose novel loss formulations that align directly with ranking metrics: the Ranking-Generalizable \textbf{squared} (RG$^2$) Loss and the Ranking-Generalizable interactive (RG$^\times$) Loss, both derived through Taylor expansions of the SM Loss. Notably, RG$^2$ reveals the intrinsic mechanisms underlying weighted squared losses (WSL) in ranking methods and uncovers fundamental connections between sampling-based and non-sampling-based loss paradigms. Furthermore, we integrate the proposed RG losses with the highly efficient Alternating Least Squares (ALS) optimization method, providing both generalization guarantees and convergence rate analyses. Empirical evaluations on real-world datasets demonstrate that our approach achieves comparable or superior ranking performance relative to SM Loss, while significantly accelerating convergence. This framework offers the similarity learning community both theoretical insights and practically efficient tools, with methodologies applicable to a broad range of tasks where balancing ranking quality and computational efficiency is essential.