 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholarQuest: A Taxonomy-Guided Benchmark for Agentic Academic Paper Search in Open Literature Environments
Jun 18, 2026Academic paper search is a core step in scientific research, and LLM-based search agents are emerging as a promising paradigm for iterative, intent-driven literature exploration. However, existing benchmarks are insufficient for systematically evaluating agentic academic search under realistic open literature environments. We propose ScholarQuest, a large-scale, taxonomy-guided benchmark for agentic academic paper search. ScholarQuest is constructed from over 1,000 computer science topics and four representative research intents, including method-oriented, setting-anchored, comparison-based, and scope-controlled queries. It further provides scalable answer construction and a shared retrieval backend ScholarBase for reproducible evaluation. Benchmarking results show that agentic methods outperform single-shot retrieval baselines, yet the best-performing agent only achieves 0.314 Recall@100 and 0.355 Recall@All, indicating substantial room for improvement. In addition, analyses of search efficiency, intent-level robustness, and failure cases further highlight the benchmark's ability to provide multi-dimensional evaluation signals for academic paper search agents.
TabClaw: An Interactive and Self-Evolving Agent for Spreadsheet Manipulation and Table Reasoning
Jun 09, 2026Spreadsheets and tables are widely used representations for structured data analysis, but effective analysis still requires substantial manual effort and domain expertise. Recent large language model (LLM) agents can automate parts of this process, but they often provide limited transparency into intermediate decisions, rely on implicit assumptions, struggle with multi-table comparison, and repeat similar workflows without adapting to a user's preferences. This paper presents TabClaw, an open-source interactive AI agent for spreadsheet manipulation and table reasoning. Users upload CSV or Excel files and issue natural-language requests; TabClaw clarifies ambiguous intent, exposes an editable execution plan, streams a ReAct-style tool-using analysis loop, dispatches specialist agents for parallel multi-table reasoning, and synthesizes findings with explicit consensus and uncertainty markers. Beyond one-off analysis, TabClaw records completed workflows, extracts persistent user memory, distills reusable skills from repeated tool-use patterns, supports package-style skill import, and upgrades skills from negative feedback. Experiments on spreadsheet manipulation and table reasoning benchmarks show that TabClaw improves executable task completion and reasoning performance while preserving an inspectable user workflow. This paper shows how TabClaw turns spreadsheets and tables into inspectable analytical workflows while gradually personalizing itself to recurring data-analysis tasks. Our code is available.
GeoDecider: A Coarse-to-Fine Agentic Workflow for Explainable Lithology Classification
May 05, 2026Lithology classification aims to infer subsurface rock types from well-logging signals, supporting downstream applications like reservoir characterization. Despite substantial progress, most existing methods still treat lithology classification as a single-pass classification task. In contrast, practical experts incorporate geological principles, external knowledge, and tool-use capabilities to perform accurate classification. In this work, we propose GeoDecider, a coarse-to-fine agentic workflow that enables accurate and explainable lithology classification through training-free use of large language models (LLMs). GeoDecider reformulates lithology classification as an expert-like structured process and organizes it into a multi-stage workflow involving coarse-to-fine reasoning. Specifically, GeoDecider includes the following stages: (1) base classifier-guided coarse classification, which uses a pre-trained classifier to provide a rough reference for downstream tasks, thus reducing the overall cost of downstream reasoning, (2) tool-augmented reasoning, which utilizes several tools such as contextual analysis and neighbor retrieval to achieve finer and more precise classifications, (3) geological refinement, which post-processes the final results to enforce geological consistency. Experiments on four benchmarks show that GeoDecider outperforms representative baselines. Further analysis demonstrates that the proposed framework produces geologically interpretable predictions while achieving a better trade-off between classification performance and inference efficiency.
GeoMind: An Agentic Workflow for Lithology Classification with Reasoned Tool Invocation
Apr 23, 2026Lithology classification in well logs is a fundamental geoscience data mining task that aims to infer rock types from multi dimensional geophysical sequences. Despite recent progress, existing approaches typically formulate the problem as a static, single-step discriminative mapping. This static paradigm limits evidence-based diagnostic reasoning against geological standards, often yielding predictions that are detached from geological reality due to a lack of domain priors. In this work, we propose GeoMind, a tool-augmented agentic framework that models lithology classification as a sequential reasoning process. GeoMind organizes its toolkit into perception, reasoning, and analysis modules, which respectively translate raw logs into semantic trends, infer lithology hypotheses from multi-source evidence, and verify predictions against stratigraphic constraints. A global planner adaptively coordinates these modules based on input characteristics, enabling geologically plausible and evidence-grounded decisions. To guarantee the logical consistency of GeoMind, we introduce a fine-grained process supervision strategy. Unlike standard methods that focus solely on final outcomes, our approach optimizes intermediate reasoning steps, ensuring the validity of decision trajectories and alignment to geological constraints. Experiments on four benchmark well-log datasets demonstrate that GeoMind consistently outperforms strong baselines in classification performance while providing transparent and traceable decision-making processes.
Loosely-Structured Software: Engineering Context, Structure, and Evolution Entropy in Runtime-Rewired Multi-Agent Systems
Mar 16, 2026As LLM-based multi-agent systems (MAS) become more autonomous, their free-form interactions increasingly dominate system behavior. However, scaling the number of agents often amplifies context pressure, coordination errors, and system drift. It is well known that building robust MAS requires more than prompt tuning or increased model intelligence. It necessitates engineering discipline focused on architecture to manage complexity under uncertainty. We characterize agentic software by a core property: \emph{runtime generation and evolution under uncertainty}. Drawing upon and extending software engineering experience, especially object-oriented programming, this paper introduces \emph{Loosely-Structured Software (LSS)}, a new class of software systems that shifts the engineering focus from constructing deterministic logic to managing the runtime entropy generated by View-constructed programming, semantic-driven self-organization, and endogenous evolution. To make this entropy governable, we introduce design principles under a three-layer engineering framework: \emph{View/Context Engineering} to manage the execution environment and maintain task-relevant Views, \emph{Structure Engineering} to organize dynamic binding over artifacts and agents, and \emph{Evolution Engineering} to govern the lifecycle of self-rewriting artifacts. Building on this framework, we develop LSS design patterns as semantic control blocks that stabilize fluid, inference-mediated interactions while preserving agent adaptability. Together, these abstractions improve the \emph{designability}, \emph{scalability}, and \emph{evolvability} of agentic infrastructure. We provide basic experimental validation of key mechanisms, demonstrating the effectiveness of LSS.
A 28nm 0.22 μJ/token memory-compute-intensity-aware CNN-Transformer accelerator with hybrid-attention-based layer-fusion and cascaded pruning for semanticsegmentation
Dec 19, 2025This work presents a 28nm 13.93mm2 CNN-Transformer accelerator for semantic segmentation, achieving 3.86-to-10.91x energy reduction over previous designs. It features a hybrid attention unit, layer-fusion scheduler, and cascaded feature-map pruner, with peak energy efficiency of 52.90TOPS/W (INT8).
* 3 pages,7 pages, 2025 IEEE International Solid-State Circuits Conference (ISSCC)
BLADE: A Behavior-Level Data Augmentation Framework with Dual Fusion Modeling for Multi-Behavior Sequential Recommendation
Dec 15, 2025Multi-behavior sequential recommendation aims to capture users' dynamic interests by modeling diverse types of user interactions over time. Although several studies have explored this setting, the recommendation performance remains suboptimal, mainly due to two fundamental challenges: the heterogeneity of user behaviors and data sparsity. To address these challenges, we propose BLADE, a framework that enhances multi-behavior modeling while mitigating data sparsity. Specifically, to handle behavior heterogeneity, we introduce a dual item-behavior fusion architecture that incorporates behavior information at both the input and intermediate levels, enabling preference modeling from multiple perspectives. To mitigate data sparsity, we design three behavior-level data augmentation methods that operate directly on behavior sequences rather than core item sequences. These methods generate diverse augmented views while preserving the semantic consistency of item sequences. These augmented views further enhance representation learning and generalization via contrastive learning. Experiments on three real-world datasets demonstrate the effectiveness of our approach.
Towards Stable and Structured Time Series Generation with Perturbation-Aware Flow Matching
Nov 18, 2025



Time series generation is critical for a wide range of applications, which greatly supports downstream analytical and decision-making tasks. However, the inherent temporal heterogeneous induced by localized perturbations present significant challenges for generating structurally consistent time series. While flow matching provides a promising paradigm by modeling temporal dynamics through trajectory-level supervision, it fails to adequately capture abrupt transitions in perturbed time series, as the use of globally shared parameters constrains the velocity field to a unified representation. To address these limitations, we introduce \textbf{PAFM}, a \textbf{P}erturbation-\textbf{A}ware \textbf{F}low \textbf{M}atching framework that models perturbed trajectories to ensure stable and structurally consistent time series generation. The framework incorporates perturbation-guided training to simulate localized disturbances and leverages a dual-path velocity field to capture trajectory deviations under perturbation, enabling refined modeling of perturbed behavior to enhance the structural coherence. In order to further improve sensitivity to trajectory perturbations while enhancing expressiveness, a mixture-of-experts decoder with flow routing dynamically allocates modeling capacity in response to different trajectory dynamics. Extensive experiments on both unconditional and conditional generation tasks demonstrate that PAFM consistently outperforms strong baselines. Code is available at https://anonymous.4open.science/r/PAFM-03B2.
Benchmarking Multimodal LLMs on Recognition and Understanding over Chemical Tables
Jun 13, 2025Chemical tables encode complex experimental knowledge through symbolic expressions, structured variables, and embedded molecular graphics. Existing benchmarks largely overlook this multimodal and domain-specific complexity, limiting the ability of multimodal large language models to support scientific understanding in chemistry. In this work, we introduce ChemTable, a large-scale benchmark of real-world chemical tables curated from the experimental sections of literature. ChemTable includes expert-annotated cell polygons, logical layouts, and domain-specific labels, including reagents, catalysts, yields, and graphical components and supports two core tasks: (1) Table Recognition, covering structure parsing and content extraction; and (2) Table Understanding, encompassing both descriptive and reasoning-oriented question answering grounded in table structure and domain semantics. We evaluated a range of representative multimodal models, including both open-source and closed-source models, on ChemTable and reported a series of findings with practical and conceptual insights. Although models show reasonable performance on basic layout parsing, they exhibit substantial limitations on both descriptive and inferential QA tasks compared to human performance, and we observe significant performance gaps between open-source and closed-source models across multiple dimensions. These results underscore the challenges of chemistry-aware table understanding and position ChemTable as a rigorous and realistic benchmark for advancing scientific reasoning.
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Jun 12, 2025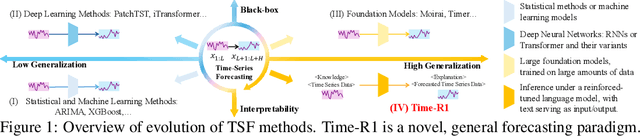

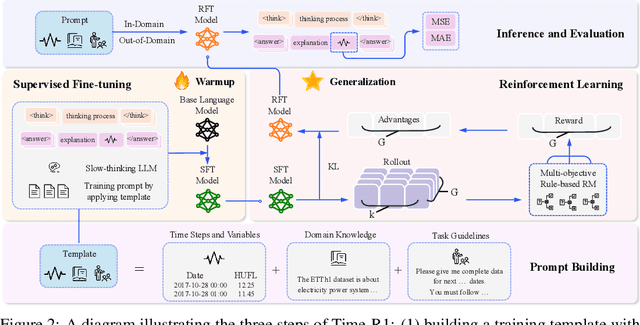
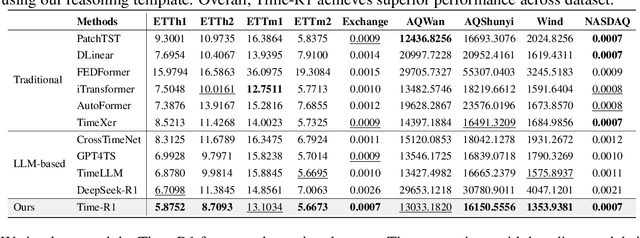
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.