 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClore: Interactive Pathology Image Segmentation with Click-based Local Refinement
Mar 29, 2026Recent advancements in deep learning-based interactive segmentation methods have significantly improved pathology image segmentation. Most existing approaches utilize user-provided positive and negative clicks to guide the segmentation process. However, these methods primarily rely on iterative global updates for refinement, which lead to redundant re-prediction and often fail to capture fine-grained structures or correct subtle errors during localized adjustments. To address this limitation, we propose the Click-based Local Refinement (Clore) pipeline, a simple yet efficient method designed to enhance interactive segmentation. The key innovation of Clore lies in its hierarchical interaction paradigm: the initial clicks drive global segmentation to rapidly outline large target regions, while subsequent clicks progressively refine local details to achieve precise boundaries. This approach not only improves the ability to handle fine-grained segmentation tasks but also achieves high-quality results with fewer interactions. Experimental results on four datasets demonstrate that Clore achieves the best balance between segmentation accuracy and interaction cost, making it an effective solution for efficient and accurate interactive pathology image segmentation.
Frequency Error-Guided Under-sampling Optimization for Multi-Contrast MRI Reconstruction
Jan 14, 2026Magnetic resonance imaging (MRI) plays a vital role in clinical diagnostics, yet it remains hindered by long acquisition times and motion artifacts. Multi-contrast MRI reconstruction has emerged as a promising direction by leveraging complementary information from fully-sampled reference scans. However, existing approaches suffer from three major limitations: (1) superficial reference fusion strategies, such as simple concatenation, (2) insufficient utilization of the complementary information provided by the reference contrast, and (3) fixed under-sampling patterns. We propose an efficient and interpretable frequency error-guided reconstruction framework to tackle these issues. We first employ a conditional diffusion model to learn a Frequency Error Prior (FEP), which is then incorporated into a unified framework for jointly optimizing both the under-sampling pattern and the reconstruction network. The proposed reconstruction model employs a model-driven deep unfolding framework that jointly exploits frequency- and image-domain information. In addition, a spatial alignment module and a reference feature decomposition strategy are incorporated to improve reconstruction quality and bridge model-based optimization with data-driven learning for improved physical interpretability. Comprehensive validation across multiple imaging modalities, acceleration rates (4-30x), and sampling schemes demonstrates consistent superiority over state-of-the-art methods in both quantitative metrics and visual quality. All codes are available at https://github.com/fangxinming/JUF-MRI.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Mamba-Based Modality Disentanglement Network for Multi-Contrast MRI Reconstruction
Dec 22, 2025Magnetic resonance imaging (MRI) is a cornerstone of modern clinical diagnosis, offering unparalleled soft-tissue contrast without ionizing radiation. However, prolonged scan times remain a major barrier to patient throughput and comfort. Existing accelerated MRI techniques often struggle with two key challenges: (1) failure to effectively utilize inherent K-space prior information, leading to persistent aliasing artifacts from zero-filled inputs; and (2) contamination of target reconstruction quality by irrelevant information when employing multi-contrast fusion strategies. To overcome these challenges, we present MambaMDN, a dual-domain framework for multi-contrast MRI reconstruction. Our approach first employs fully-sampled reference K-space data to complete the undersampled target data, generating structurally aligned but modality-mixed inputs. Subsequently, we develop a Mamba-based modality disentanglement network to extract and remove reference-specific features from the mixed representation. Furthermore, we introduce an iterative refinement mechanism to progressively enhance reconstruction accuracy through repeated feature purification. Extensive experiments demonstrate that MambaMDN can significantly outperform existing multi-contrast reconstruction methods.
DIFFUMA: High-Fidelity Spatio-Temporal Video Prediction via Dual-Path Mamba and Diffusion Enhancement
Jul 09, 2025



Spatio-temporal video prediction plays a pivotal role in critical domains, ranging from weather forecasting to industrial automation. However, in high-precision industrial scenarios such as semiconductor manufacturing, the absence of specialized benchmark datasets severely hampers research on modeling and predicting complex processes. To address this challenge, we make a twofold contribution.First, we construct and release the Chip Dicing Lane Dataset (CHDL), the first public temporal image dataset dedicated to the semiconductor wafer dicing process. Captured via an industrial-grade vision system, CHDL provides a much-needed and challenging benchmark for high-fidelity process modeling, defect detection, and digital twin development.Second, we propose DIFFUMA, an innovative dual-path prediction architecture specifically designed for such fine-grained dynamics. The model captures global long-range temporal context through a parallel Mamba module, while simultaneously leveraging a diffusion module, guided by temporal features, to restore and enhance fine-grained spatial details, effectively combating feature degradation. Experiments demonstrate that on our CHDL benchmark, DIFFUMA significantly outperforms existing methods, reducing the Mean Squared Error (MSE) by 39% and improving the Structural Similarity (SSIM) from 0.926 to a near-perfect 0.988. This superior performance also generalizes to natural phenomena datasets. Our work not only delivers a new state-of-the-art (SOTA) model but, more importantly, provides the community with an invaluable data resource to drive future research in industrial AI.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025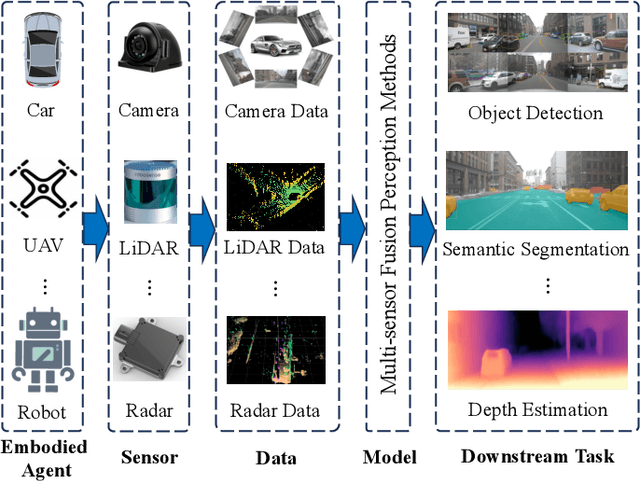
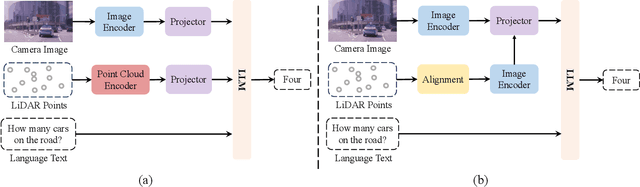
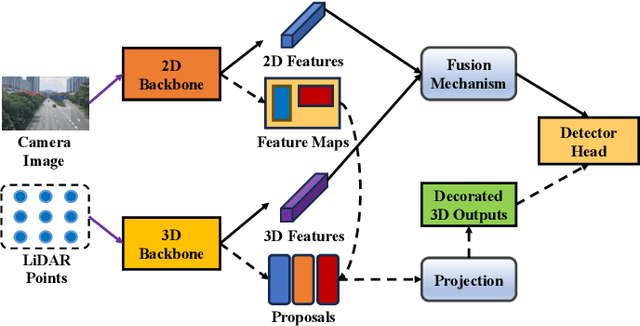
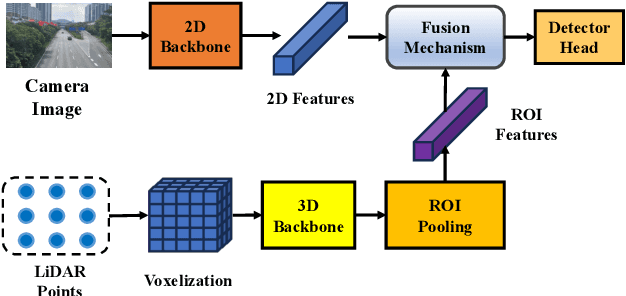
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
LMS-Net: A Learned Mumford-Shah Network For Few-Shot Medical Image Segmentation
Feb 08, 2025



Few-shot semantic segmentation (FSS) methods have shown great promise in handling data-scarce scenarios, particularly in medical image segmentation tasks. However, most existing FSS architectures lack sufficient interpretability and fail to fully incorporate the underlying physical structures of semantic regions. To address these issues, in this paper, we propose a novel deep unfolding network, called the Learned Mumford-Shah Network (LMS-Net), for the FSS task. Specifically, motivated by the effectiveness of pixel-to-prototype comparison in prototypical FSS methods and the capability of deep priors to model complex spatial structures, we leverage our learned Mumford-Shah model (LMS model) as a mathematical foundation to integrate these insights into a unified framework. By reformulating the LMS model into prototype update and mask update tasks, we propose an alternating optimization algorithm to solve it efficiently. Further, the iterative steps of this algorithm are unfolded into corresponding network modules, resulting in LMS-Net with clear interpretability. Comprehensive experiments on three publicly available medical segmentation datasets verify the effectiveness of our method, demonstrating superior accuracy and robustness in handling complex structures and adapting to challenging segmentation scenarios. These results highlight the potential of LMS-Net to advance FSS in medical imaging applications. Our code will be available at: https://github.com/SDZhang01/LMSNet