 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLADE: A Behavior-Level Data Augmentation Framework with Dual Fusion Modeling for Multi-Behavior Sequential Recommendation
Dec 15, 2025Multi-behavior sequential recommendation aims to capture users' dynamic interests by modeling diverse types of user interactions over time. Although several studies have explored this setting, the recommendation performance remains suboptimal, mainly due to two fundamental challenges: the heterogeneity of user behaviors and data sparsity. To address these challenges, we propose BLADE, a framework that enhances multi-behavior modeling while mitigating data sparsity. Specifically, to handle behavior heterogeneity, we introduce a dual item-behavior fusion architecture that incorporates behavior information at both the input and intermediate levels, enabling preference modeling from multiple perspectives. To mitigate data sparsity, we design three behavior-level data augmentation methods that operate directly on behavior sequences rather than core item sequences. These methods generate diverse augmented views while preserving the semantic consistency of item sequences. These augmented views further enhance representation learning and generalization via contrastive learning. Experiments on three real-world datasets demonstrate the effectiveness of our approach.
Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
Nov 18, 2025Large Language Models (LLMs) are increasingly being explored for building Agents capable of active environmental interaction (e.g., via tool use) to solve complex problems. Reinforcement Learning (RL) is considered a key technology with significant potential for training such Agents; however, the effective application of RL to LLM Agents is still in its nascent stages and faces considerable challenges. Currently, this emerging field lacks in-depth exploration into RL approaches specifically tailored for the LLM Agent context, alongside a scarcity of flexible and easily extensible training frameworks designed for this purpose. To help advance this area, this paper first revisits and clarifies Reinforcement Learning methodologies for LLM Agents by systematically extending the Markov Decision Process (MDP) framework to comprehensively define the key components of an LLM Agent. Secondly, we introduce Agent-R1, a modular, flexible, and user-friendly training framework for RL-based LLM Agents, designed for straightforward adaptation across diverse task scenarios and interactive environments. We conducted experiments on Multihop QA benchmark tasks, providing initial validation for the effectiveness of our proposed methods and framework.
STaR: Towards Cognitive Table Reasoning via Slow-Thinking Large Language Models
Nov 14, 2025Table reasoning with the large language models (LLMs) is a fundamental path toward building intelligent systems that can understand and analyze over structured data. While recent progress has shown promising results, they still suffer from two key limitations: (i) the reasoning processes lack the depth and iterative refinement characteristic of human cognition; and (ii) the reasoning processes exhibit instability, which compromises their reliability in downstream applications. In this work, we present STaR (slow-thinking for table reasoning), a new framework achieving cognitive table reasoning, in which LLMs are equipped with slow-thinking capabilities by explicitly modeling step-by-step thinking and uncertainty-aware inference. During training, STaR employs two-stage difficulty-aware reinforcement learning (DRL), progressively learning from simple to complex queries under a composite reward. During inference, STaR performs trajectory-level uncertainty quantification by integrating token-level confidence and answer consistency, enabling selection of more credible reasoning paths. Extensive experiments on benchmarks demonstrate that STaR achieves superior performance and enhanced reasoning stability. Moreover, strong generalization over out-of-domain datasets further demonstrates STaR's potential as a reliable and cognitively inspired solution for table reasoning with LLMs.
DARTS: A Dual-View Attack Framework for Targeted Manipulation in Federated Sequential Recommendation
Jul 02, 2025Federated recommendation (FedRec) preserves user privacy by enabling decentralized training of personalized models, but this architecture is inherently vulnerable to adversarial attacks. Significant research has been conducted on targeted attacks in FedRec systems, motivated by commercial and social influence considerations. However, much of this work has largely overlooked the differential robustness of recommendation models. Moreover, our empirical findings indicate that existing targeted attack methods achieve only limited effectiveness in Federated Sequential Recommendation(FSR) tasks. Driven by these observations, we focus on investigating targeted attacks in FSR and propose a novel dualview attack framework, named DV-FSR. This attack method uniquely combines a sampling-based explicit strategy with a contrastive learning-based implicit gradient strategy to orchestrate a coordinated attack. Additionally, we introduce a specific defense mechanism tailored for targeted attacks in FSR, aiming to evaluate the mitigation effects of the attack method we proposed. Extensive experiments validate the effectiveness of our proposed approach on representative sequential models. Our codes are publicly available.
Benchmarking Multimodal LLMs on Recognition and Understanding over Chemical Tables
Jun 13, 2025Chemical tables encode complex experimental knowledge through symbolic expressions, structured variables, and embedded molecular graphics. Existing benchmarks largely overlook this multimodal and domain-specific complexity, limiting the ability of multimodal large language models to support scientific understanding in chemistry. In this work, we introduce ChemTable, a large-scale benchmark of real-world chemical tables curated from the experimental sections of literature. ChemTable includes expert-annotated cell polygons, logical layouts, and domain-specific labels, including reagents, catalysts, yields, and graphical components and supports two core tasks: (1) Table Recognition, covering structure parsing and content extraction; and (2) Table Understanding, encompassing both descriptive and reasoning-oriented question answering grounded in table structure and domain semantics. We evaluated a range of representative multimodal models, including both open-source and closed-source models, on ChemTable and reported a series of findings with practical and conceptual insights. Although models show reasonable performance on basic layout parsing, they exhibit substantial limitations on both descriptive and inferential QA tasks compared to human performance, and we observe significant performance gaps between open-source and closed-source models across multiple dimensions. These results underscore the challenges of chemistry-aware table understanding and position ChemTable as a rigorous and realistic benchmark for advancing scientific reasoning.
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Jun 12, 2025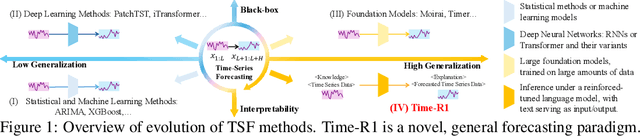

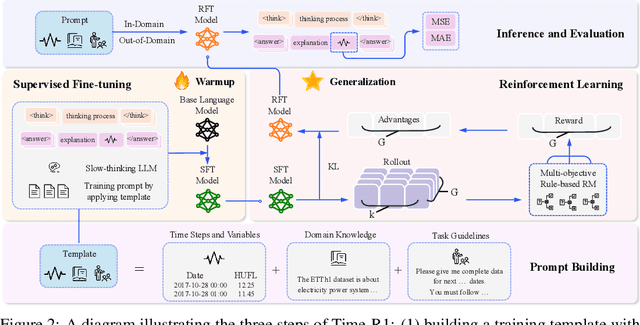
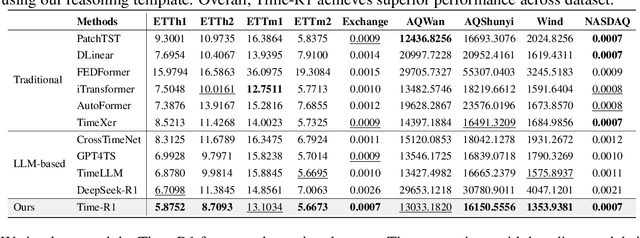
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.
TextMatch: Enhancing Image-Text Consistency Through Multimodal Optimization
Dec 24, 2024Text-to-image generative models excel in creating images from text but struggle with ensuring alignment and consistency between outputs and prompts. This paper introduces TextMatch, a novel framework that leverages multimodal optimization to address image-text discrepancies in text-to-image (T2I) generation and editing. TextMatch employs a scoring strategy powered by large language models (LLMs) and visual question-answering (VQA) models to evaluate semantic consistency between prompts and generated images. By integrating multimodal in-context learning and chain of thought reasoning, our method dynamically refines prompts through iterative optimization. This process ensures that the generated images better capture user intent of, resulting in higher fidelity and relevance. Extensive experiments demonstrate that TextMatch significantly improves text-image consistency across multiple benchmarks, establishing a reliable framework for advancing the capabilities of text-to-image generative models. Our code is available at https://anonymous.4open.science/r/TextMatch-F55C/.
Molar: Multimodal LLMs with Collaborative Filtering Alignment for Enhanced Sequential Recommendation
Dec 24, 2024Sequential recommendation (SR) systems have evolved significantly over the past decade, transitioning from traditional collaborative filtering to deep learning approaches and, more recently, to large language models (LLMs). While the adoption of LLMs has driven substantial advancements, these models inherently lack collaborative filtering information, relying primarily on textual content data neglecting other modalities and thus failing to achieve optimal recommendation performance. To address this limitation, we propose Molar, a Multimodal large language sequential recommendation framework that integrates multiple content modalities with ID information to capture collaborative signals effectively. Molar employs an MLLM to generate unified item representations from both textual and non-textual data, facilitating comprehensive multimodal modeling and enriching item embeddings. Additionally, it incorporates collaborative filtering signals through a post-alignment mechanism, which aligns user representations from content-based and ID-based models, ensuring precise personalization and robust performance. By seamlessly combining multimodal content with collaborative filtering insights, Molar captures both user interests and contextual semantics, leading to superior recommendation accuracy. Extensive experiments validate that Molar significantly outperforms traditional and LLM-based baselines, highlighting its strength in utilizing multimodal data and collaborative signals for sequential recommendation tasks. The source code is available at https://anonymous.4open.science/r/Molar-8B06/.
Hierarchical Multimodal LLMs with Semantic Space Alignment for Enhanced Time Series Classification
Oct 24, 2024



Leveraging large language models (LLMs) has garnered increasing attention and introduced novel perspectives in time series classification. However, existing approaches often overlook the crucial dynamic temporal information inherent in time series data and face challenges in aligning this data with textual semantics. To address these limitations, we propose HiTime, a hierarchical multi-modal model that seamlessly integrates temporal information into LLMs for multivariate time series classification (MTSC). Our model employs a hierarchical feature encoder to capture diverse aspects of time series data through both data-specific and task-specific embeddings. To facilitate semantic space alignment between time series and text, we introduce a dual-view contrastive alignment module that bridges the gap between modalities. Additionally, we adopt a hybrid prompting strategy to fine-tune the pre-trained LLM in a parameter-efficient manner. By effectively incorporating dynamic temporal features and ensuring semantic alignment, HiTime enables LLMs to process continuous time series data and achieves state-of-the-art classification performance through text generation. Extensive experiments on benchmark datasets demonstrate that HiTime significantly enhances time series classification accuracy compared to most competitive baseline methods. Our findings highlight the potential of integrating temporal features into LLMs, paving the way for advanced time series analysis. The code is publicly available for further research and validation. Our codes are publicly available1.
Learning Recommender Systems with Soft Target: A Decoupled Perspective
Oct 09, 2024



Learning recommender systems with multi-class optimization objective is a prevalent setting in recommendation. However, as observed user feedback often accounts for a tiny fraction of the entire item pool, the standard Softmax loss tends to ignore the difference between potential positive feedback and truly negative feedback. To address this challenge, we propose a novel decoupled soft label optimization framework to consider the objectives as two aspects by leveraging soft labels, including target confidence and the latent interest distribution of non-target items. Futhermore, based on our carefully theoretical analysis, we design a decoupled loss function to flexibly adjust the importance of these two aspects. To maximize the performance of the proposed method, we additionally present a sensible soft-label generation algorithm that models a label propagation algorithm to explore users' latent interests in unobserved feedback via neighbors. We conduct extensive experiments on various recommendation system models and public datasets, the results demonstrate the effectiveness and generality of the proposed method.