 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
Mar 11, 2025



Recent advances in long video understanding typically mitigate visual redundancy through visual token pruning based on attention distribution. However, while existing methods employ post-hoc low-response token pruning in decoder layers, they overlook the input-level semantic correlation between visual tokens and instructions (query). In this paper, we propose QuoTA, an ante-hoc training-free modular that extends existing large video-language models (LVLMs) for visual token assignment based on query-oriented frame-level importance assessment. The query-oriented token selection is crucial as it aligns visual processing with task-specific requirements, optimizing token budget utilization while preserving semantically relevant content. Specifically, (i) QuoTA strategically allocates frame-level importance scores based on query relevance, enabling one-time visual token assignment before cross-modal interactions in decoder layers, (ii) we decouple the query through Chain-of-Thoughts reasoning to facilitate more precise LVLM-based frame importance scoring, and (iii) QuoTA offers a plug-and-play functionality that extends to existing LVLMs. Extensive experimental results demonstrate that implementing QuoTA with LLaVA-Video-7B yields an average performance improvement of 3.2% across six benchmarks (including Video-MME and MLVU) while operating within an identical visual token budget as the baseline. Codes are open-sourced at https://github.com/MAC-AutoML/QuoTA.
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency
Feb 13, 2025



Answering questions with Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), yet its impact on Large Multimodal Models (LMMs) still lacks a systematic assessment and in-depth investigation. In this paper, we introduce MME-CoT, a specialized benchmark evaluating the CoT reasoning performance of LMMs, spanning six domains: math, science, OCR, logic, space-time, and general scenes. As the first comprehensive study in this area, we propose a thorough evaluation suite incorporating three novel metrics that assess the reasoning quality, robustness, and efficiency at a fine-grained level. Leveraging curated high-quality data and a unique evaluation strategy, we conduct an in-depth analysis of state-of-the-art LMMs, uncovering several key insights: 1) Models with reflection mechanism demonstrate a superior CoT quality, with Kimi k1.5 outperforming GPT-4o and demonstrating the highest quality results; 2) CoT prompting often degrades LMM performance on perception-heavy tasks, suggesting a potentially harmful overthinking behavior; and 3) Although the CoT quality is high, LMMs with reflection exhibit significant inefficiency in both normal response and self-correction phases. We hope MME-CoT serves as a foundation for advancing multimodal reasoning in LMMs. Project Page: https://mmecot.github.io/
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray
Feb 07, 2025Establishing the long-context capability of large vision-language models is crucial for video understanding, high-resolution image understanding, multi-modal agents and reasoning. We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logits-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of $17$M samples from public datasets only and demonstrates the state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully reproducible and supports both NPU and GPU platforms for training and testing. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open-source community in advancing long-context multi-modal understanding.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025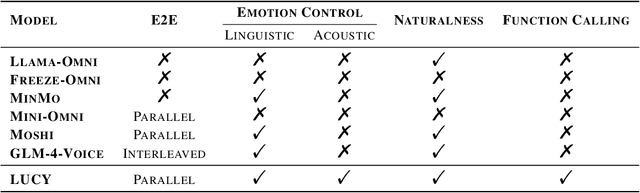
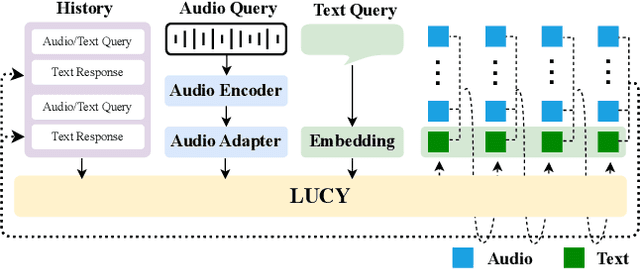
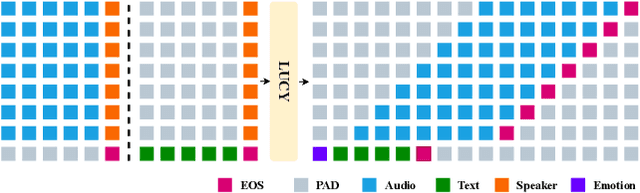
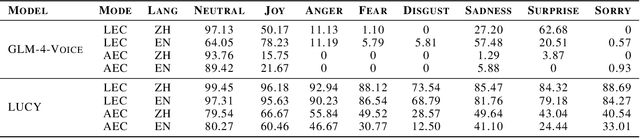
The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Jan 03, 2025



Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption
Dec 12, 2024



Text-to-video generation has evolved rapidly in recent years, delivering remarkable results. Training typically relies on video-caption paired data, which plays a crucial role in enhancing generation performance. However, current video captions often suffer from insufficient details, hallucinations and imprecise motion depiction, affecting the fidelity and consistency of generated videos. In this work, we propose a novel instance-aware structured caption framework, termed InstanceCap, to achieve instance-level and fine-grained video caption for the first time. Based on this scheme, we design an auxiliary models cluster to convert original video into instances to enhance instance fidelity. Video instances are further used to refine dense prompts into structured phrases, achieving concise yet precise descriptions. Furthermore, a 22K InstanceVid dataset is curated for training, and an enhancement pipeline that tailored to InstanceCap structure is proposed for inference. Experimental results demonstrate that our proposed InstanceCap significantly outperform previous models, ensuring high fidelity between captions and videos while reducing hallucinations.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
MME-Survey: A Comprehensive Survey on Evaluation of Multimodal LLMs
Nov 22, 2024



As a prominent direction of Artificial General Intelligence (AGI), Multimodal Large Language Models (MLLMs) have garnered increased attention from both industry and academia. Building upon pre-trained LLMs, this family of models further develops multimodal perception and reasoning capabilities that are impressive, such as writing code given a flow chart or creating stories based on an image. In the development process, evaluation is critical since it provides intuitive feedback and guidance on improving models. Distinct from the traditional train-eval-test paradigm that only favors a single task like image classification, the versatility of MLLMs has spurred the rise of various new benchmarks and evaluation methods. In this paper, we aim to present a comprehensive survey of MLLM evaluation, discussing four key aspects: 1) the summarised benchmarks types divided by the evaluation capabilities, including foundation capabilities, model self-analysis, and extented applications; 2) the typical process of benchmark counstruction, consisting of data collection, annotation, and precautions; 3) the systematic evaluation manner composed of judge, metric, and toolkit; 4) the outlook for the next benchmark. This work aims to offer researchers an easy grasp of how to effectively evaluate MLLMs according to different needs and to inspire better evaluation methods, thereby driving the progress of MLLM research.
MME-Finance: A Multimodal Finance Benchmark for Expert-level Understanding and Reasoning
Nov 05, 2024



In recent years, multimodal benchmarks for general domains have guided the rapid development of multimodal models on general tasks. However, the financial field has its peculiarities. It features unique graphical images (e.g., candlestick charts, technical indicator charts) and possesses a wealth of specialized financial knowledge (e.g., futures, turnover rate). Therefore, benchmarks from general fields often fail to measure the performance of multimodal models in the financial domain, and thus cannot effectively guide the rapid development of large financial models. To promote the development of large financial multimodal models, we propose MME-Finance, an bilingual open-ended and practical usage-oriented Visual Question Answering (VQA) benchmark. The characteristics of our benchmark are finance and expertise, which include constructing charts that reflect the actual usage needs of users (e.g., computer screenshots and mobile photography), creating questions according to the preferences in financial domain inquiries, and annotating questions by experts with 10+ years of experience in the financial industry. Additionally, we have developed a custom-designed financial evaluation system in which visual information is first introduced in the multi-modal evaluation process. Extensive experimental evaluations of 19 mainstream MLLMs are conducted to test their perception, reasoning, and cognition capabilities. The results indicate that models performing well on general benchmarks cannot do well on MME-Finance; for instance, the top-performing open-source and closed-source models obtain 65.69 (Qwen2VL-72B) and 63.18 (GPT-4o), respectively. Their performance is particularly poor in categories most relevant to finance, such as candlestick charts and technical indicator charts. In addition, we propose a Chinese version, which helps compare performance of MLLMs under a Chinese context.
Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM
Nov 01, 2024



The rapid development of large language models has brought many new smart applications, especially the excellent multimodal human-computer interaction in GPT-4o has brought impressive experience to users. In this background, researchers have proposed many multimodal LLMs that can achieve speech-to-speech dialogue recently. In this paper, we propose a speech-text multimodal LLM architecture called Freeze-Omni. Our main contribution is the speech input and output modalities can connected to the LLM while keeping the LLM frozen throughout the training process. We designed 3-stage training strategies both for the modeling of speech input and output, enabling Freeze-Omni to obtain speech-to-speech dialogue ability using text-speech paired data (such as ASR and TTS data) and only 60,000 multi-round text Q&A data on 8 GPUs. Moreover, we can effectively ensure that the intelligence of the Freeze-Omni in the speech modality is at the same level compared with that in the text modality of its backbone LLM, while the end-to-end latency of the spoken response achieves a low level. In addition, we also designed a method to achieve duplex dialogue ability through multi-task training, making Freeze-Omni have a more natural style of dialogue ability between the users. Freeze-Omni mainly provides a possibility for researchers to conduct multimodal LLM under the condition of a frozen LLM, avoiding various impacts caused by the catastrophic forgetting of LLM caused by fewer data and training resources.