 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Landscape Diagnosis for Gradient-Based Gray-Scott System Inversion: Disentangling the Roles of PINN Components
Jun 09, 2026Gradient-based inversion of reaction-diffusion systems is typically approached via surrogate models or physics-informed neural networks (PINNs), while the most direct route, backpropagation through the PDE's structure itself, has largely been avoided. We pursue this direct route as a diagnostic probe, backpropagating a steady-state loss through unrolled Gray-Scott simulation to recover its parameters, with no surrogate or neural-network augmentation. Optimization fails to converge, and plotting the landscape directly locates the failure in its geometry -- flat plateaus with no gradient signal, bounded by sharp cliffs that align with bifurcation boundaries -- a structure that recurs across loss functions and is inherited however the gradients are routed to parameters. Reading this minimal setup as an ablation of PINN, we disentangle each component's role: with the neural network fixed, the residual loss is quadratic in the PDE parameters and yields a smooth landscape, so it alone already avoids the pathology, by implicitly encoding the full PDE dynamics across all initial conditions. The neural network, for its part, cannot repair an ill-posed parameter subspace, and so serves only to complete the observed data -- a division of labor not previously made explicit. These findings carry concrete design implications for PINN-type methods and a broader heuristic on when added dimensions actually help.
Optimization over the intersection of manifolds
May 21, 2026Optimization over the intersection of two manifolds arises in a broad range of applications, but is hindered by the coupled geometry of the feasible region. In this paper, we prove that the regularities -- clean intersection and intrinsic transversality -- are equivalent, which yields a tractable projection onto the tangent space of the intersection. Therefore, we propose a geometric method that employs a retraction on only one manifold and updates the iterate along two orthogonal directions. Specifically, the iterates stay on one manifold, and the two directions are responsible for asymptotically approaching the other manifold and decreasing the objective function, respectively. Under intrinsic transversality, we derive the convergence rate for both the feasibility and optimality measures, and show that every accumulation point is first-order stationary. Numerical experiments on problems stemming from sparse and low-rank optimization, including fitting spherical data, approximating hyperbolic embeddings on real data, and computing compressed modes, demonstrate the effectiveness of the proposed method.
Benchmarking and Improving GUI Agents in High-Dynamic Environments
Apr 28, 2026Recent advancements in Graphical User Interface (GUI) agents have predominantly focused on training paradigms like supervised fine-tuning (SFT) and reinforcement learning (RL). However, the challenge of high-dynamic GUI environments remains largely underexplored. Existing agents typically rely on a single screenshot after each action for decision-making, leading to a partially observable (or even unobservable) Markov decision process, where the key GUI state including important information for actions is often inadequately captured. To systematically explore this challenge, we introduce DynamicGUIBench, a comprehensive online GUI benchmark spanning ten applications and diverse interaction scenarios characterized by important interface changes between actions. Furthermore, we present DynamicUI, an agent designed for dynamic interfaces, which takes screen-recording videos of the interaction process as input and consists of three components: a dynamic perceiver, a refinement strategy, and a reflection. Specifically, the dynamic perceiver clusters frames of the GUI video, generates captions for the centroids, and iteratively selects the most informative frames as the salient dynamic context. Considering that there may be inconsistencies and noise between the selected frames and the textual context of the agent, the refinement strategy employs an action-conditioned filtering to refine thoughts to mitigate thought-action inconsistency and redundancy. Based on the refined agent trajectories, the reflection module provides effective and accurate guidance for further actions. Experiments on DynamicGUIBench demonstrate that DynamicUI significantly improves the performance in dynamic GUI environments, while maintaining competitive performance on other public benchmarks.
CGC: Compositional Grounded Contrast for Fine-Grained Multi-Image Understanding
Apr 24, 2026Although Multimodal Large Language Models (MLLMs) have advanced rapidly, they still face notable challenges in fine-grained multi-image understanding, often exhibiting spatial hallucination, attention leakage, and failures in object constancy. In addition, existing approaches typically rely on expensive human annotations or large-scale chain-of-thought (CoT) data generation. We propose Compositional Grounded Contrast (abbr. CGC), a low-cost full framework for boosting fine-grained multi-image understanding of MLLMs. Built on existing single-image grounding annotations, CGC constructs compositional multi-image training instances through Inter-Image Contrast and Intra-Image Contrast, which introduce semantically decoupled distractor contexts for cross-image discrimination and correlated cross-view samples for object constancy, respectively. CGC further introduces a Rule-Based Spatial Reward within the GRPO framework to improve source-image attribution, spatial alignment, and structured output validity under a Think-before-Grounding paradigm. Experiments show that CGC achieves state-of-the-art results on fine-grained multi-image benchmarks, including MIG-Bench and VLM2-Bench. The learned multi-image understanding capability also transfers to broader multimodal understanding and reasoning tasks, yielding consistent gains over the Qwen3-VL-8B base model on MathVista (+2.90), MuirBench (+2.88), MMStar (+1.93), MMMU (+1.77), and BLINK (+1.69).
Progressive Video Condensation with MLLM Agent for Long-form Video Understanding
Apr 03, 2026Understanding long videos requires extracting query-relevant information from long sequences under tight compute budgets. Existing text-then-LLM pipelines lose fine-grained visual cues, while video-based multimodal large language models (MLLMs) can keep visual details but are too frame-hungry and computationally expensive. In this work, we aim to harness MLLMs for efficient video understanding. We propose ProVCA, a progressive video condensation agent that iteratively locates key video frames at multiple granularities. ProVCA first adopts a segment localization module to identify the video segment relevant to the query, then a snippet selection module to select important snippets based on similarity, and finally a keyframe refinement module to pinpoint specific keyframes in those snippets. By progressively narrowing the scope from coarse segments to fine frames, ProVCA identifies a small set of keyframes for MLLM-based reasoning. ProVCA achieves state-of-the-art zero-shot accuracies of 69.3\% on EgoSchema, 80.5\% on NExT-QA, and 77.7\% on IntentQA, while using fewer frames than previous training-free methods.
GPA: Learning GUI Process Automation from Demonstrations
Apr 02, 2026GUI Process Automation (GPA) is a lightweight but general vision-based Robotic Process Automation (RPA), which enables fast and stable process replay with only a single demo. Addressing the fragility of traditional RPA and the non-deterministic risks of current vision language model-based GUI agents, GPA introduces three core benefits: (1) Robustness via Sequential Monte Carlo-based localization to handle rescaling and detection uncertainty; (2) Deterministic and Reliability safeguarded by readiness calibration; and (3) Privacy through fast, fully local execution. This approach delivers the adaptability, robustness, and security required for enterprise workflows. It can also be used as an MCP/CLI tool by other agents with coding capabilities so that the agent only reasons and orchestrates while GPA handles the GUI execution. We conducted a pilot experiment to compare GPA with Gemini 3 Pro (with CUA tools) and found that GPA achieves higher success rate with 10 times faster execution speed in finishing long-horizon GUI tasks.
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
Mar 17, 2026Omni-modal large language models (OLMs) redefine human-machine interaction by natively integrating audio, vision, and text. However, existing OLM benchmarks remain anchored to static, accuracy-centric tasks, leaving a critical gap in assessing social interactivity, the fundamental capacity to navigate dynamic cues in natural dialogues. To this end, we propose SocialOmni, a comprehensive benchmark that operationalizes the evaluation of this conversational interactivity across three core dimensions: (i) speaker separation and identification (who is speaking), (ii) interruption timing control (when to interject), and (iii) natural interruption generation (how to phrase the interruption). SocialOmni features 2,000 perception samples and a quality-controlled diagnostic set of 209 interaction-generation instances with strict temporal and contextual constraints, complemented by controlled audio-visual inconsistency scenarios to test model robustness. We benchmarked 12 leading OLMs, which uncovers significant variance in their social-interaction capabilities across models. Furthermore, our analysis reveals a pronounced decoupling between a model's perceptual accuracy and its ability to generate contextually appropriate interruptions, indicating that understanding-centric metrics alone are insufficient to characterize conversational social competence. More encouragingly, these diagnostics from SocialOmni yield actionable signals for bridging the perception-interaction divide in future OLMs.
Two-Step Data Augmentation for Masked Face Detection and Recognition: Turning Fake Masks to Real
Dec 13, 2025Data scarcity and distribution shift pose major challenges for masked face detection and recognition. We propose a two-step generative data augmentation framework that combines rule-based mask warping with unpaired image-to-image translation using GANs, enabling the generation of realistic masked-face samples beyond purely synthetic transformations. Compared to rule-based warping alone, the proposed approach yields consistent qualitative improvements and complements existing GAN-based masked face generation methods such as IAMGAN. We introduce a non-mask preservation loss and stochastic noise injection to stabilize training and enhance sample diversity. Experimental observations highlight the effectiveness of the proposed components and suggest directions for future improvements in data-centric augmentation for face recognition tasks.
* 9 pages, 9 figures. Conference version
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?
Nov 17, 2025



Large Language Models (LLMs) are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-Gödel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that Live-SWE-agent can achieve an impressive solve rate of 75.4% without test-time scaling, outperforming all existing open-source software agents and approaching the performance of the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.
Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Nov 10, 2025

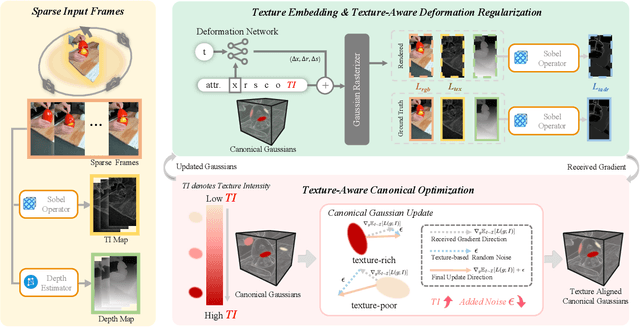
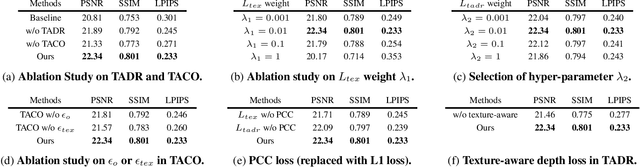
Dynamic Gaussian Splatting approaches have achieved remarkable performance for 4D scene reconstruction. However, these approaches rely on dense-frame video sequences for photorealistic reconstruction. In real-world scenarios, due to equipment constraints, sometimes only sparse frames are accessible. In this paper, we propose Sparse4DGS, the first method for sparse-frame dynamic scene reconstruction. We observe that dynamic reconstruction methods fail in both canonical and deformed spaces under sparse-frame settings, especially in areas with high texture richness. Sparse4DGS tackles this challenge by focusing on texture-rich areas. For the deformation network, we propose Texture-Aware Deformation Regularization, which introduces a texture-based depth alignment loss to regulate Gaussian deformation. For the canonical Gaussian field, we introduce Texture-Aware Canonical Optimization, which incorporates texture-based noise into the gradient descent process of canonical Gaussians. Extensive experiments show that when taking sparse frames as inputs, our method outperforms existing dynamic or few-shot techniques on NeRF-Synthetic, HyperNeRF, NeRF-DS, and our iPhone-4D datasets.