 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Real-World Dexterous Grasping Policies via Implicit Shape Augmentation
Oct 24, 2022



Dexterous robotic hands have the capability to interact with a wide variety of household objects to perform tasks like grasping. However, learning robust real world grasping policies for arbitrary objects has proven challenging due to the difficulty of generating high quality training data. In this work, we propose a learning system (ISAGrasp) for leveraging a small number of human demonstrations to bootstrap the generation of a much larger dataset containing successful grasps on a variety of novel objects. Our key insight is to use a correspondence-aware implicit generative model to deform object meshes and demonstrated human grasps in order to generate a diverse dataset of novel objects and successful grasps for supervised learning, while maintaining semantic realism. We use this dataset to train a robust grasping policy in simulation which can be deployed in the real world. We demonstrate grasping performance with a four-fingered Allegro hand in both simulation and the real world, and show this method can handle entirely new semantic classes and achieve a 79% success rate on grasping unseen objects in the real world.
DexTransfer: Real World Multi-fingered Dexterous Grasping with Minimal Human Demonstrations
Sep 28, 2022

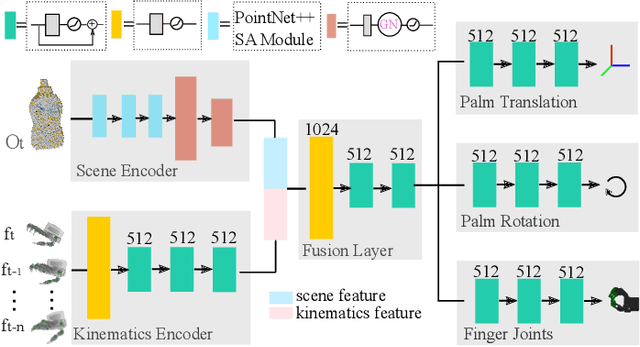
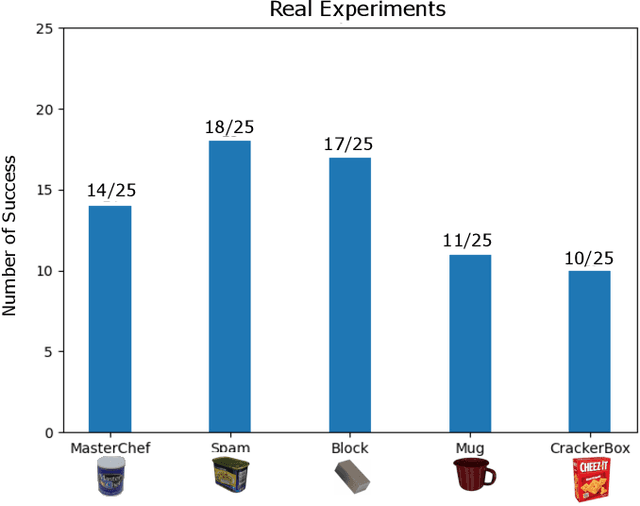
Teaching a multi-fingered dexterous robot to grasp objects in the real world has been a challenging problem due to its high dimensional state and action space. We propose a robot-learning system that can take a small number of human demonstrations and learn to grasp unseen object poses given partially occluded observations. Our system leverages a small motion capture dataset and generates a large dataset with diverse and successful trajectories for a multi-fingered robot gripper. By adding domain randomization, we show that our dataset provides robust grasping trajectories that can be transferred to a policy learner. We train a dexterous grasping policy that takes the point clouds of the object as input and predicts continuous actions to grasp objects from different initial robot states. We evaluate the effectiveness of our system on a 22-DoF floating Allegro Hand in simulation and a 23-DoF Allegro robot hand with a KUKA arm in real world. The policy learned from our dataset can generalize well on unseen object poses in both simulation and the real world
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022
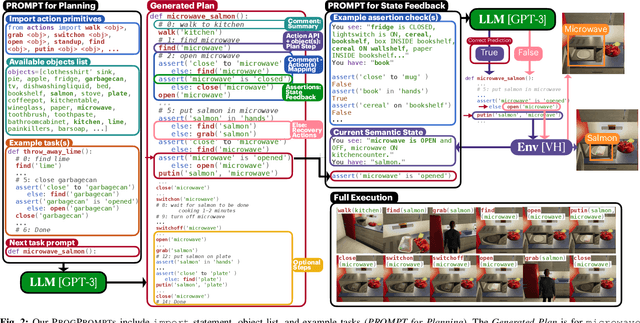


Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
IFOR: Iterative Flow Minimization for Robotic Object Rearrangement
Feb 01, 2022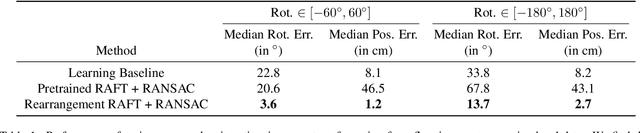
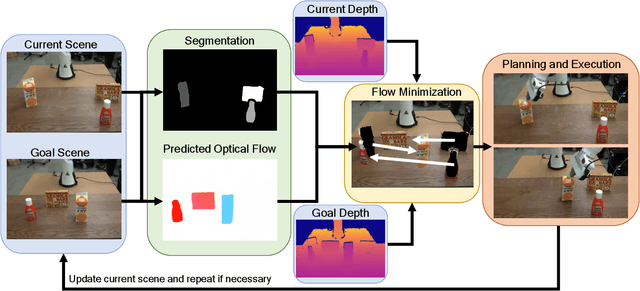
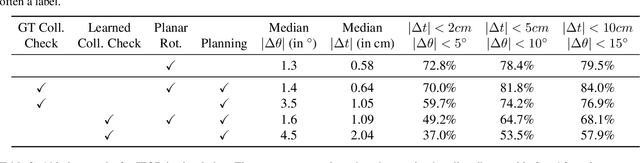

Accurate object rearrangement from vision is a crucial problem for a wide variety of real-world robotics applications in unstructured environments. We propose IFOR, Iterative Flow Minimization for Robotic Object Rearrangement, an end-to-end method for the challenging problem of object rearrangement for unknown objects given an RGBD image of the original and final scenes. First, we learn an optical flow model based on RAFT to estimate the relative transformation of the objects purely from synthetic data. This flow is then used in an iterative minimization algorithm to achieve accurate positioning of previously unseen objects. Crucially, we show that our method applies to cluttered scenes, and in the real world, while training only on synthetic data. Videos are available at https://imankgoyal.github.io/ifor.html.
RICE: Refining Instance Masks in Cluttered Environments with Graph Neural Networks
Jun 29, 2021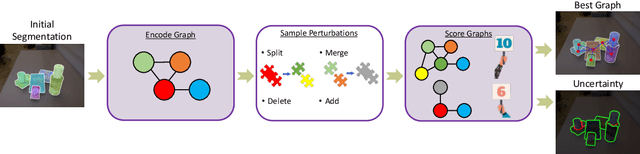

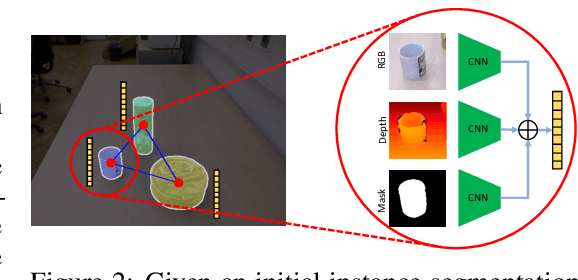
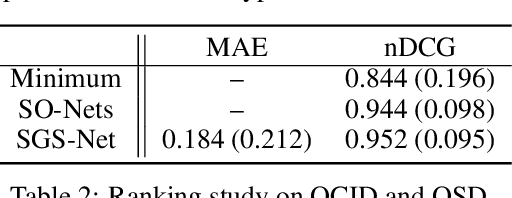
Segmenting unseen object instances in cluttered environments is an important capability that robots need when functioning in unstructured environments. While previous methods have exhibited promising results, they still tend to provide incorrect results in highly cluttered scenes. We postulate that a network architecture that encodes relations between objects at a high-level can be beneficial. Thus, in this work, we propose a novel framework that refines the output of such methods by utilizing a graph-based representation of instance masks. We train deep networks capable of sampling smart perturbations to the segmentations, and a graph neural network, which can encode relations between objects, to evaluate the perturbed segmentations. Our proposed method is orthogonal to previous works and achieves state-of-the-art performance when combined with them. We demonstrate an application that uses uncertainty estimates generated by our method to guide a manipulator, leading to efficient understanding of cluttered scenes. Code, models, and video can be found at https://github.com/chrisdxie/rice .
NeRP: Neural Rearrangement Planning for Unknown Objects
Jun 04, 2021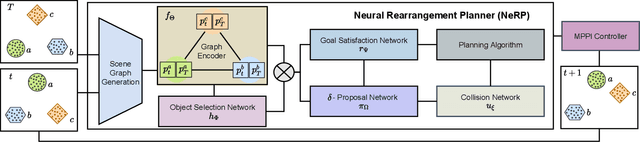



Robots will be expected to manipulate a wide variety of objects in complex and arbitrary ways as they become more widely used in human environments. As such, the rearrangement of objects has been noted to be an important benchmark for AI capabilities in recent years. We propose NeRP (Neural Rearrangement Planning), a deep learning based approach for multi-step neural object rearrangement planning which works with never-before-seen objects, that is trained on simulation data, and generalizes to the real world. We compare NeRP to several naive and model-based baselines, demonstrating that our approach is measurably better and can efficiently arrange unseen objects in fewer steps and with less planning time. Finally, we demonstrate it on several challenging rearrangement problems in the real world.
Fast Joint Space Model-Predictive Control for Reactive Manipulation
Apr 28, 2021
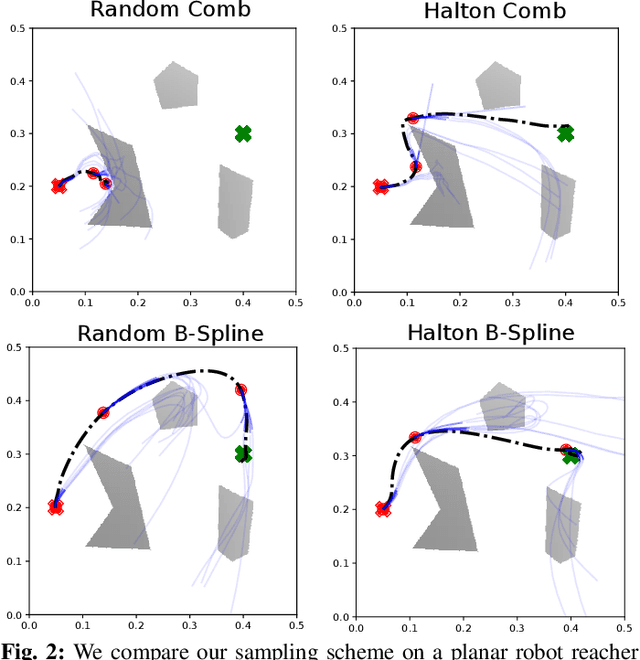
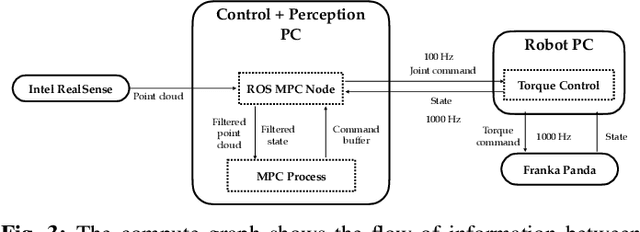
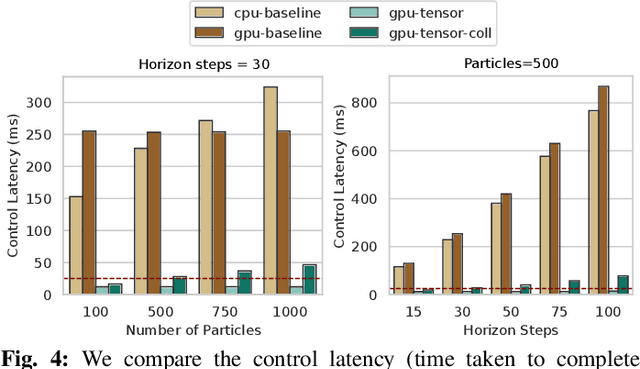
Sampling-based model predictive control (MPC) is a promising tool for feedback control of robots with complex and non-smooth dynamics and cost functions. The computationally demanding nature of sampling-based MPC algorithms is a key bottleneck in their application to high-dimensional robotic manipulation problems. Previous methods have addressed this issue by running MPC in the task space while relying on a low-level operational space controller for joint control. However, by not using the joint space of the robot in the MPC formulation, existing methods cannot directly account for non-task space related constraints such as avoiding joint limits, singular configurations, and link collisions. In this paper, we develop a joint space sampling-based MPC for manipulators that can be efficiently parallelized using GPUs. Our approach can handle task and joint space constraints while taking less than 0.02 seconds (50Hz) to compute the next control command. Further, our method can integrate perception into the control problem by utilizing learned cost functions from raw sensor data. We validate our approach by deploying it on a Franka Panda robot for a variety of common manipulation tasks. We study the effect of different cost formulations and MPC parameters on the synthesized behavior and provide key insights that pave the way for the application of sampling-based MPC for manipulators in a principled manner. Videos of experiments can be found at: https://sites.google.com/view/manipulation-mppi.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021
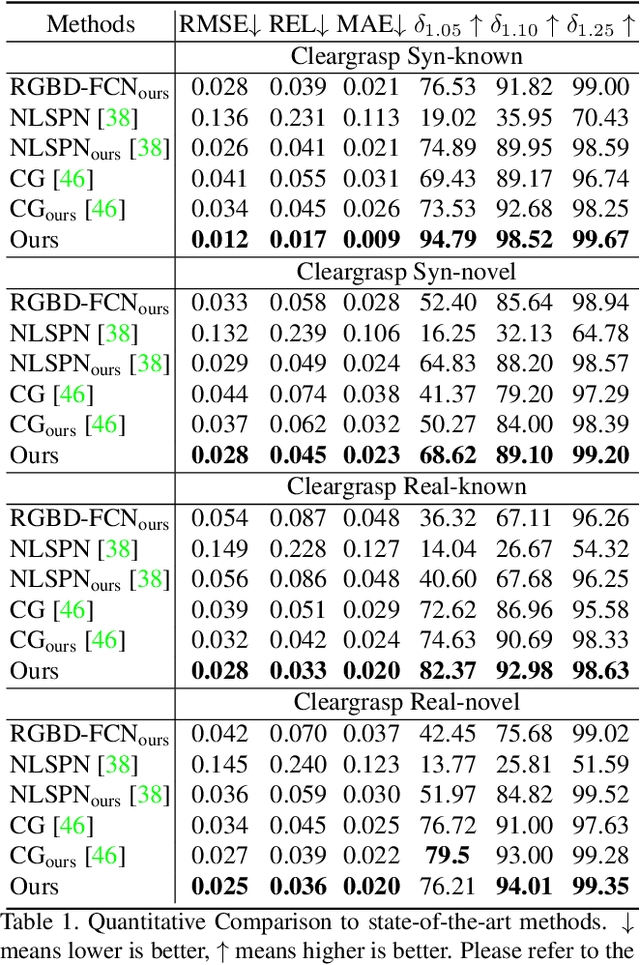


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Sim-to-Real for Robotic Tactile Sensing via Physics-Based Simulation and Learned Latent Projections
Mar 31, 2021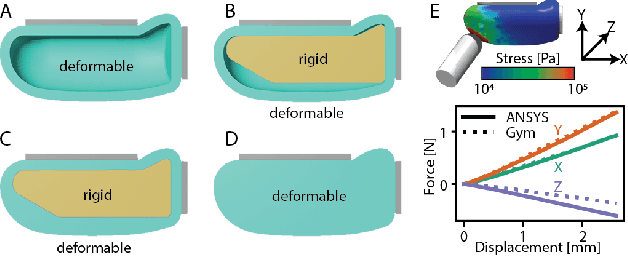
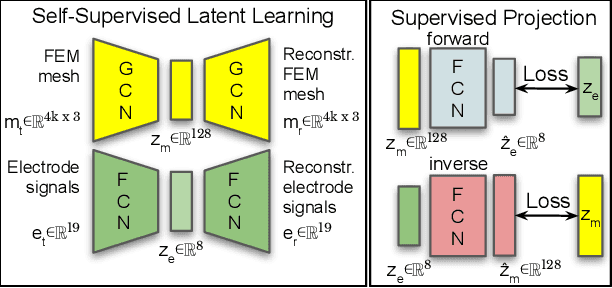

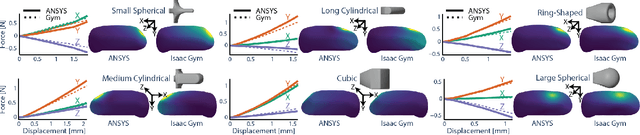
Tactile sensing is critical for robotic grasping and manipulation of objects under visual occlusion. However, in contrast to simulations of robot arms and cameras, current simulations of tactile sensors have limited accuracy, speed, and utility. In this work, we develop an efficient 3D finite element method (FEM) model of the SynTouch BioTac sensor using an open-access, GPU-based robotics simulator. Our simulations closely reproduce results from an experimentally-validated model in an industry-standard, CPU-based simulator, but at 75x the speed. We then learn latent representations for simulated BioTac deformations and real-world electrical output through self-supervision, as well as projections between the latent spaces using a small supervised dataset. Using these learned latent projections, we accurately synthesize real-world BioTac electrical output and estimate contact patches, both for unseen contact interactions. This work contributes an efficient, freely-accessible FEM model of the BioTac and comprises one of the first efforts to combine self-supervision, cross-modal transfer, and sim-to-real transfer for tactile sensors.