 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Execution Horizon Prediction for Chunk-based Robot Policies
Jun 09, 2026Action chunking has become a standard design in modern robot policies, from diffusion/flow policies to vision-language-action models, where the policy predicts a sequence of actions and executes a fixed number of them instead of acting one step at a time. However, this paradigm relies on a key assumption: a fixed execution horizon. During chunk execution, the policy operates open-loop, which is particularly problematic for fine-grained manipulation tasks that require frequent replanning. In practice, the execution horizon is typically chosen through empirical tuning and is highly task-dependent. To this end, we propose Dynamic Execution Horizon Prediction (DEHP), an effective method that trains a lightweight execution-horizon prediction branch using online reinforcement learning while keeping the pretrained chunk policy completely frozen. This makes the method compatible with black-box chunk policies and isolates the effect of adapting the execution horizon from changes to the underlying action generator. Across our evaluations, DEHP improves the success rate of different high-precision and long-horizon manipulation tasks by a large margin. Our qualitative analysis further shows that DEHP predicts shorter execution horizons during fine-grained stages of the task and longer horizons during free-space motion. In this way, DEHP balances the efficiency of open-loop chunk execution with the reactivity of closed-loop single-step control. Project page: https://dehp-chunking.github.io/
COBALT: Crowdsourcing Robot Learning via Cloud-Based Teleoperation with Smartphones
May 20, 2026The scarcity of large-scale, high-quality demonstration data remains a bottleneck in scaling imitation learning for robotic manipulation. We present COBALT, a teleoperation platform designed to democratize robot learning at scale both in simulation and in the real world. By leveraging vectorized environments, our scalable, load-balanced infrastructure supports concurrent teleoperation by multiple users on a single GPU, yielding a significant reduction in teleoperation cost. Operators can connect from nearly anywhere on Earth using commonly available devices, including single or dual smartphones, VR headsets, 3D mice, and keyboards. An inmemory data cache and efficient video streaming keep control and rendering synchronous, sustaining dozens of concurrent users at 20 Hz with sub-100 ms end-to-end latency for up to 8 concurrent users per GPU. We also demonstrate stable operation supporting 256 simulated clients across 8 GPUs, underscoring the system's ability to scale across hardware and within individual servers. We perform a comprehensive user study showing that phone-based teleoperation performs comparably to or better than specialized hardware, enabling faster, more ergonomic data collection. To ensure data quality, COBALT logs a suite of real-time metrics to automatically filter suboptimal demonstrations. We further demonstrate that a structured user training curriculum significantly improves data collection quality. Guided by insights from our user study, we crowdsource the collection of a large-scale, high-quality pilot dataset with 7500+ demonstrations (50+ hours) collected with smartphones across nine countries over five days. We validate the dataset's quality by training state-of-the-art imitation learning algorithms. Please visit https://cobalt-teleop.github.io/ for more details.
SoftMimicGen: A Data Generation System for Scalable Robot Learning in Deformable Object Manipulation
Mar 26, 2026Large-scale robot datasets have facilitated the learning of a wide range of robot manipulation skills, but these datasets remain difficult to collect and scale further, owing to the intractable amount of human time, effort, and cost required. Simulation and synthetic data generation have proven to be an effective alternative to fuel this need for data, especially with the advent of recent work showing that such synthetic datasets can dramatically reduce real-world data requirements and facilitate generalization to novel scenarios unseen in real-world demonstrations. However, this paradigm has been limited to rigid-body tasks, which are easy to simulate. Deformable object manipulation encompasses a large portion of real-world manipulation and remains a crucial gap to address towards increasing adoption of the synthetic simulation data paradigm. In this paper, we introduce SoftMimicGen, an automated data generation pipeline for deformable object manipulation tasks. We introduce a suite of high-fidelity simulation environments that encompasses a wide range of deformable objects (stuffed animal, rope, tissue, towel) and manipulation behaviors (high-precision threading, dynamic whipping, folding, pick-and-place), across four robot embodiments: a single-arm manipulator, bimanual arms, a humanoid, and a surgical robot. We apply SoftMimicGen to generate datasets across the task suite, train high-performing policies from the data, and systematically analyze the data generation system. Project website: \href{https://softmimicgen.github.io}{softmimicgen.github.io}.
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Mar 17, 2026Video diffusion models are moving beyond short, plausible clips toward world simulators that must remain consistent under camera motion, revisits, and intervention. Yet spatial memory remains a key bottleneck: explicit 3D structures can improve reprojection-based consistency but struggle to depict moving objects, while implicit memory often produces inaccurate camera motion even with correct poses. We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval, while exploiting the model's native conditioning to preserve prompt-following generation. MosaicMem composes spatially aligned patches in the queried view via a patch-and-compose interface, preserving what should persist while allowing the model to inpaint what should evolve. With PRoPE camera conditioning and two new memory alignment methods, experiments show improved pose adherence compared to implicit memory and stronger dynamic modeling than explicit baselines. MosaicMem further enables minute-level navigation, memory-based scene editing, and autoregressive rollout.
MATTERIX: toward a digital twin for robotics-assisted chemistry laboratory automation
Jan 19, 2026Accelerated materials discovery is critical for addressing global challenges. However, developing new laboratory workflows relies heavily on real-world experimental trials, and this can hinder scalability because of the need for numerous physical make-and-test iterations. Here we present MATTERIX, a multiscale, graphics processing unit-accelerated robotic simulation framework designed to create high-fidelity digital twins of chemistry laboratories, thus accelerating workflow development. This multiscale digital twin simulates robotic physical manipulation, powder and liquid dynamics, device functionalities, heat transfer and basic chemical reaction kinetics. This is enabled by integrating realistic physics simulation and photorealistic rendering with a modular graphics processing unit-accelerated semantics engine, which models logical states and continuous behaviors to simulate chemistry workflows across different levels of abstraction. MATTERIX streamlines the creation of digital twin environments through open-source asset libraries and interfaces, while enabling flexible workflow design via hierarchical plan definition and a modular skill library that incorporates learning-based methods. Our approach demonstrates sim-to-real transfer in robotic chemistry setups, reducing reliance on costly real-world experiments and enabling the testing of hypothetical automated workflows in silico. The project website is available at https://accelerationconsortium.github.io/Matterix/ .
ReinforceGen: Hybrid Skill Policies with Automated Data Generation and Reinforcement Learning
Dec 18, 2025Long-horizon manipulation has been a long-standing challenge in the robotics community. We propose ReinforceGen, a system that combines task decomposition, data generation, imitation learning, and motion planning to form an initial solution, and improves each component through reinforcement-learning-based fine-tuning. ReinforceGen first segments the task into multiple localized skills, which are connected through motion planning. The skills and motion planning targets are trained with imitation learning on a dataset generated from 10 human demonstrations, and then fine-tuned through online adaptation and reinforcement learning. When benchmarked on the Robosuite dataset, ReinforceGen reaches 80% success rate on all tasks with visuomotor controls in the highest reset range setting. Additional ablation studies show that our fine-tuning approaches contributes to an 89% average performance increase. More results and videos available in https://reinforcegen.github.io/
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
AMPLIFY: Actionless Motion Priors for Robot Learning from Videos
Jun 17, 2025Action-labeled data for robotics is scarce and expensive, limiting the generalization of learned policies. In contrast, vast amounts of action-free video data are readily available, but translating these observations into effective policies remains a challenge. We introduce AMPLIFY, a novel framework that leverages large-scale video data by encoding visual dynamics into compact, discrete motion tokens derived from keypoint trajectories. Our modular approach separates visual motion prediction from action inference, decoupling the challenges of learning what motion defines a task from how robots can perform it. We train a forward dynamics model on abundant action-free videos and an inverse dynamics model on a limited set of action-labeled examples, allowing for independent scaling. Extensive evaluations demonstrate that the learned dynamics are both accurate, achieving up to 3.7x better MSE and over 2.5x better pixel prediction accuracy compared to prior approaches, and broadly useful. In downstream policy learning, our dynamics predictions enable a 1.2-2.2x improvement in low-data regimes, a 1.4x average improvement by learning from action-free human videos, and the first generalization to LIBERO tasks from zero in-distribution action data. Beyond robotic control, we find the dynamics learned by AMPLIFY to be a versatile latent world model, enhancing video prediction quality. Our results present a novel paradigm leveraging heterogeneous data sources to build efficient, generalizable world models. More information can be found at https://amplify-robotics.github.io/.
SuFIA-BC: Generating High Quality Demonstration Data for Visuomotor Policy Learning in Surgical Subtasks
Apr 21, 2025
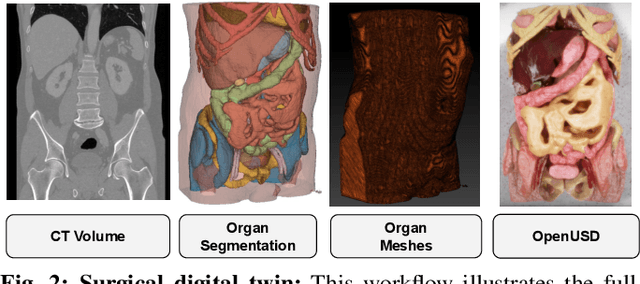
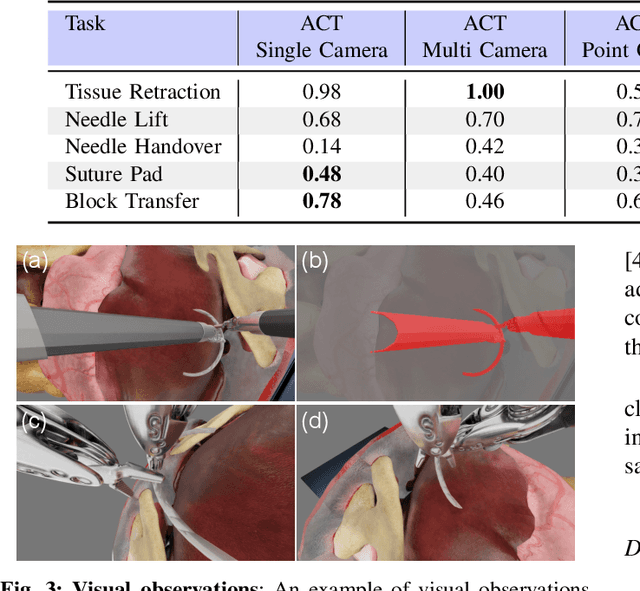

Behavior cloning facilitates the learning of dexterous manipulation skills, yet the complexity of surgical environments, the difficulty and expense of obtaining patient data, and robot calibration errors present unique challenges for surgical robot learning. We provide an enhanced surgical digital twin with photorealistic human anatomical organs, integrated into a comprehensive simulator designed to generate high-quality synthetic data to solve fundamental tasks in surgical autonomy. We present SuFIA-BC: visual Behavior Cloning policies for Surgical First Interactive Autonomy Assistants. We investigate visual observation spaces including multi-view cameras and 3D visual representations extracted from a single endoscopic camera view. Through systematic evaluation, we find that the diverse set of photorealistic surgical tasks introduced in this work enables a comprehensive evaluation of prospective behavior cloning models for the unique challenges posed by surgical environments. We observe that current state-of-the-art behavior cloning techniques struggle to solve the contact-rich and complex tasks evaluated in this work, regardless of their underlying perception or control architectures. These findings highlight the importance of customizing perception pipelines and control architectures, as well as curating larger-scale synthetic datasets that meet the specific demands of surgical tasks. Project website: https://orbit-surgical.github.io/sufia-bc/
Can LLM feedback enhance review quality? A randomized study of 20K reviews at ICLR 2025
Apr 13, 2025Peer review at AI conferences is stressed by rapidly rising submission volumes, leading to deteriorating review quality and increased author dissatisfaction. To address these issues, we developed Review Feedback Agent, a system leveraging multiple large language models (LLMs) to improve review clarity and actionability by providing automated feedback on vague comments, content misunderstandings, and unprofessional remarks to reviewers. Implemented at ICLR 2025 as a large randomized control study, our system provided optional feedback to more than 20,000 randomly selected reviews. To ensure high-quality feedback for reviewers at this scale, we also developed a suite of automated reliability tests powered by LLMs that acted as guardrails to ensure feedback quality, with feedback only being sent to reviewers if it passed all the tests. The results show that 27% of reviewers who received feedback updated their reviews, and over 12,000 feedback suggestions from the agent were incorporated by those reviewers. This suggests that many reviewers found the AI-generated feedback sufficiently helpful to merit updating their reviews. Incorporating AI feedback led to significantly longer reviews (an average increase of 80 words among those who updated after receiving feedback) and more informative reviews, as evaluated by blinded researchers. Moreover, reviewers who were selected to receive AI feedback were also more engaged during paper rebuttals, as seen in longer author-reviewer discussions. This work demonstrates that carefully designed LLM-generated review feedback can enhance peer review quality by making reviews more specific and actionable while increasing engagement between reviewers and authors. The Review Feedback Agent is publicly available at https://github.com/zou-group/review_feedback_agent.