 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024



We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
M&M VTO: Multi-Garment Virtual Try-On and Editing
Jun 06, 2024



We present M&M VTO, a mix and match virtual try-on method that takes as input multiple garment images, text description for garment layout and an image of a person. An example input includes: an image of a shirt, an image of a pair of pants, "rolled sleeves, shirt tucked in", and an image of a person. The output is a visualization of how those garments (in the desired layout) would look like on the given person. Key contributions of our method are: 1) a single stage diffusion based model, with no super resolution cascading, that allows to mix and match multiple garments at 1024x512 resolution preserving and warping intricate garment details, 2) architecture design (VTO UNet Diffusion Transformer) to disentangle denoising from person specific features, allowing for a highly effective finetuning strategy for identity preservation (6MB model per individual vs 4GB achieved with, e.g., dreambooth finetuning); solving a common identity loss problem in current virtual try-on methods, 3) layout control for multiple garments via text inputs specifically finetuned over PaLI-3 for virtual try-on task. Experimental results indicate that M&M VTO achieves state-of-the-art performance both qualitatively and quantitatively, as well as opens up new opportunities for virtual try-on via language-guided and multi-garment try-on.
TryOnDiffusion: A Tale of Two UNets
Jun 14, 2023



Given two images depicting a person and a garment worn by another person, our goal is to generate a visualization of how the garment might look on the input person. A key challenge is to synthesize a photorealistic detail-preserving visualization of the garment, while warping the garment to accommodate a significant body pose and shape change across the subjects. Previous methods either focus on garment detail preservation without effective pose and shape variation, or allow try-on with the desired shape and pose but lack garment details. In this paper, we propose a diffusion-based architecture that unifies two UNets (referred to as Parallel-UNet), which allows us to preserve garment details and warp the garment for significant pose and body change in a single network. The key ideas behind Parallel-UNet include: 1) garment is warped implicitly via a cross attention mechanism, 2) garment warp and person blend happen as part of a unified process as opposed to a sequence of two separate tasks. Experimental results indicate that TryOnDiffusion achieves state-of-the-art performance both qualitatively and quantitatively.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021
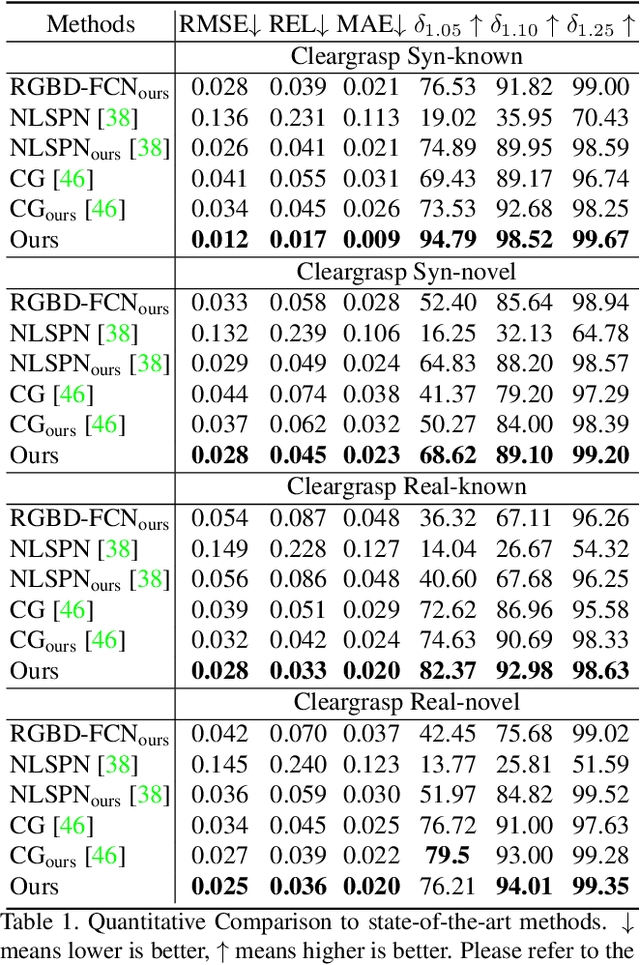


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Reconstructing NBA Players
Jul 27, 2020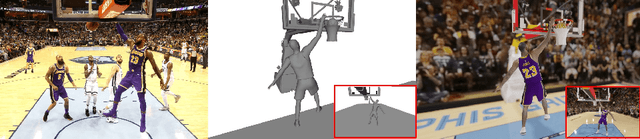

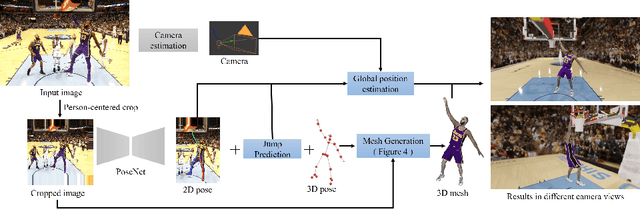

Great progress has been made in 3D body pose and shape estimation from a single photo. Yet, state-of-the-art results still suffer from errors due to challenging body poses, modeling clothing, and self occlusions. The domain of basketball games is particularly challenging, as it exhibits all of these challenges. In this paper, we introduce a new approach for reconstruction of basketball players that outperforms the state-of-the-art. Key to our approach is a new method for creating poseable, skinned models of NBA players, and a large database of meshes (derived from the NBA2K19 video game), that we are releasing to the research community. Based on these models, we introduce a new method that takes as input a single photo of a clothed player in any basketball pose and outputs a high resolution mesh and 3D pose for that player. We demonstrate substantial improvement over state-of-the-art, single-image methods for body shape reconstruction.
Learning to Estimate 3D Human Pose and Shape from a Single Color Image
May 10, 2018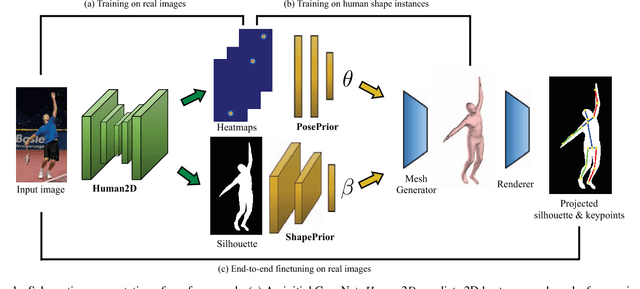
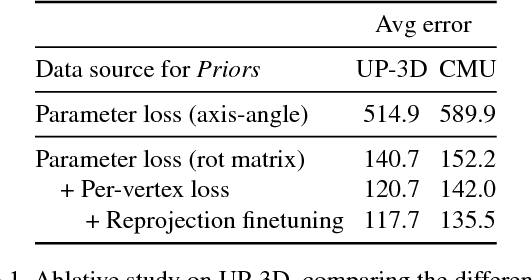
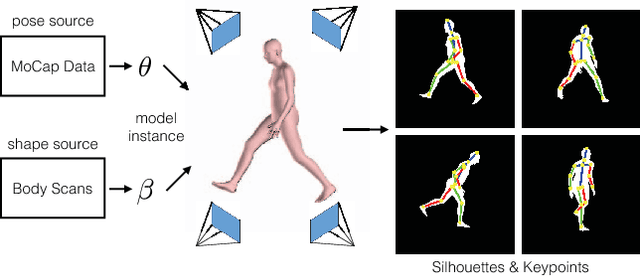

This work addresses the problem of estimating the full body 3D human pose and shape from a single color image. This is a task where iterative optimization-based solutions have typically prevailed, while Convolutional Networks (ConvNets) have suffered because of the lack of training data and their low resolution 3D predictions. Our work aims to bridge this gap and proposes an efficient and effective direct prediction method based on ConvNets. Central part to our approach is the incorporation of a parametric statistical body shape model (SMPL) within our end-to-end framework. This allows us to get very detailed 3D mesh results, while requiring estimation only of a small number of parameters, making it friendly for direct network prediction. Interestingly, we demonstrate that these parameters can be predicted reliably only from 2D keypoints and masks. These are typical outputs of generic 2D human analysis ConvNets, allowing us to relax the massive requirement that images with 3D shape ground truth are available for training. Simultaneously, by maintaining differentiability, at training time we generate the 3D mesh from the estimated parameters and optimize explicitly for the surface using a 3D per-vertex loss. Finally, a differentiable renderer is employed to project the 3D mesh to the image, which enables further refinement of the network, by optimizing for the consistency of the projection with 2D annotations (i.e., 2D keypoints or masks). The proposed approach outperforms previous baselines on this task and offers an attractive solution for direct prediction of 3D shape from a single color image.