 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillS: Adaptive Skill Sequencing for Efficient Temporally-Extended Exploration
Dec 03, 2022



The ability to effectively reuse prior knowledge is a key requirement when building general and flexible Reinforcement Learning (RL) agents. Skill reuse is one of the most common approaches, but current methods have considerable limitations.For example, fine-tuning an existing policy frequently fails, as the policy can degrade rapidly early in training. In a similar vein, distillation of expert behavior can lead to poor results when given sub-optimal experts. We compare several common approaches for skill transfer on multiple domains including changes in task and system dynamics. We identify how existing methods can fail and introduce an alternative approach to mitigate these problems. Our approach learns to sequence existing temporally-extended skills for exploration but learns the final policy directly from the raw experience. This conceptual split enables rapid adaptation and thus efficient data collection but without constraining the final solution.It significantly outperforms many classical methods across a suite of evaluation tasks and we use a broad set of ablations to highlight the importance of differentc omponents of our method.
How to Spend Your Robot Time: Bridging Kickstarting and Offline Reinforcement Learning for Vision-based Robotic Manipulation
May 06, 2022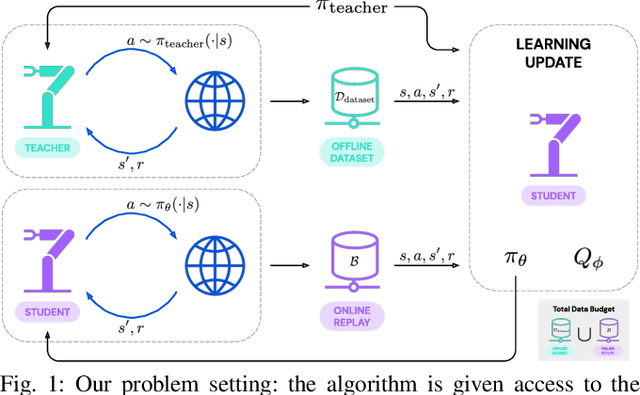

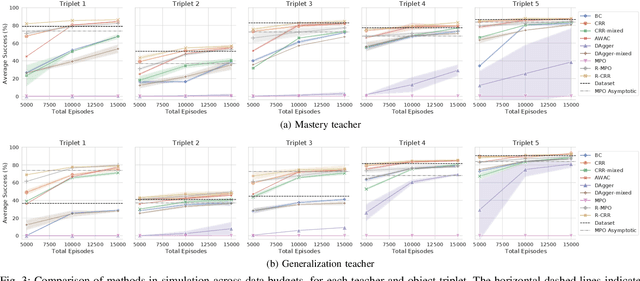
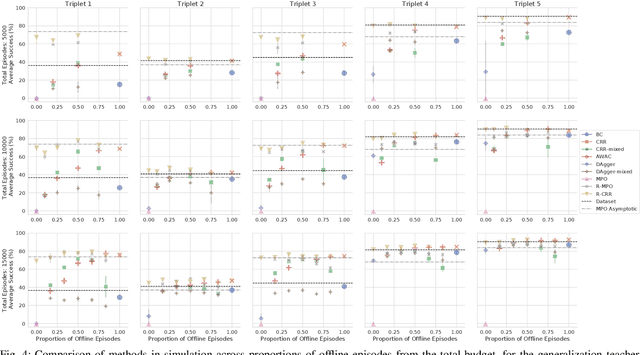
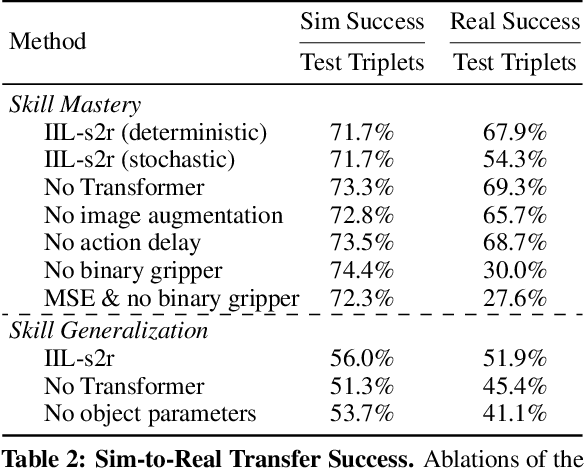
Reinforcement learning (RL) has been shown to be effective at learning control from experience. However, RL typically requires a large amount of online interaction with the environment. This limits its applicability to real-world settings, such as in robotics, where such interaction is expensive. In this work we investigate ways to minimize online interactions in a target task, by reusing a suboptimal policy we might have access to, for example from training on related prior tasks, or in simulation. To this end, we develop two RL algorithms that can speed up training by using not only the action distributions of teacher policies, but also data collected by such policies on the task at hand. We conduct a thorough experimental study of how to use suboptimal teachers on a challenging robotic manipulation benchmark on vision-based stacking with diverse objects. We compare our methods to offline, online, offline-to-online, and kickstarting RL algorithms. By doing so, we find that training on data from both the teacher and student, enables the best performance for limited data budgets. We examine how to best allocate a limited data budget -- on the target task -- between the teacher and the student policy, and report experiments using varying budgets, two teachers with different degrees of suboptimality, and five stacking tasks that require a diverse set of behaviors. Our analysis, both in simulation and in the real world, shows that our approach is the best across data budgets, while standard offline RL from teacher rollouts is surprisingly effective when enough data is given.
Revisiting Gaussian mixture critics in off-policy reinforcement learning: a sample-based approach
Apr 22, 2022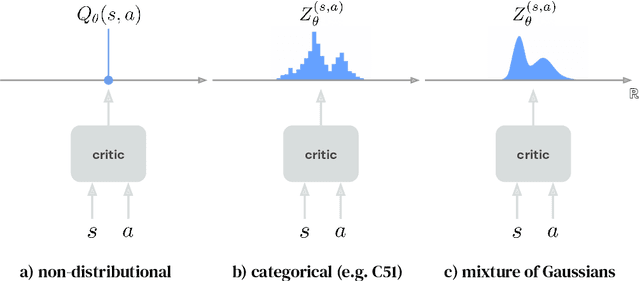
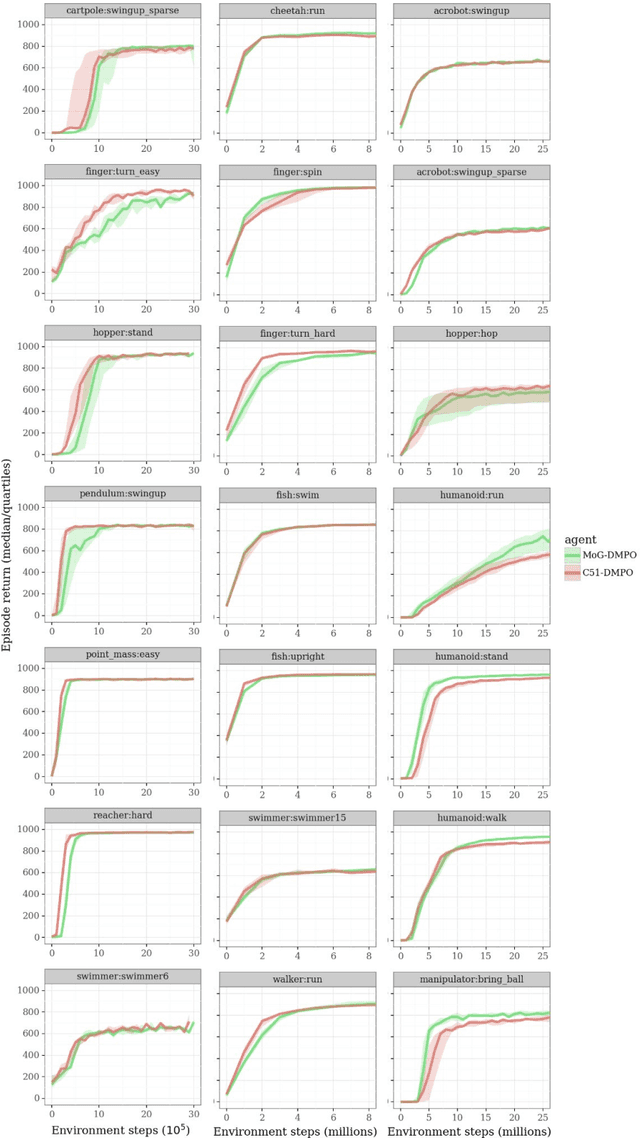
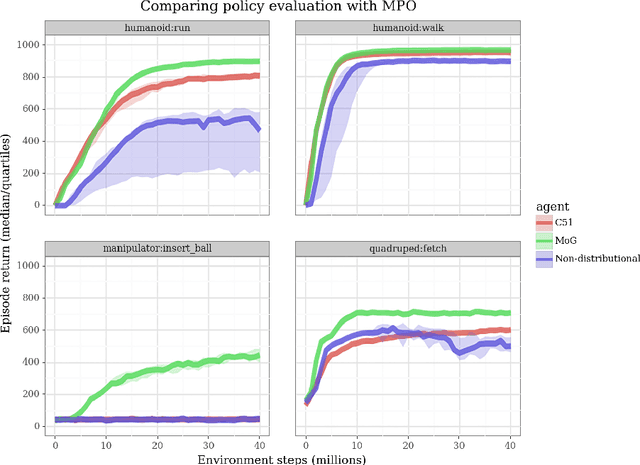
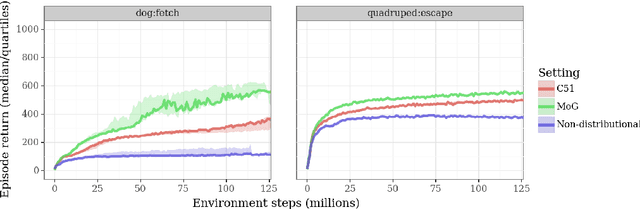
Actor-critic algorithms that make use of distributional policy evaluation have frequently been shown to outperform their non-distributional counterparts on many challenging control tasks. Examples of this behavior include the D4PG and DMPO algorithms as compared to DDPG and MPO, respectively [Barth-Maron et al., 2018; Hoffman et al., 2020]. However, both agents rely on the C51 critic for value estimation.One major drawback of the C51 approach is its requirement of prior knowledge about the minimum andmaximum values a policy can attain as well as the number of bins used, which fixes the resolution ofthe distributional estimate. While the DeepMind control suite of tasks utilizes standardized rewards and episode lengths, thus enabling the entire suite to be solved with a single setting of these hyperparameters, this is often not the case. This paper revisits a natural alternative that removes this requirement, namelya mixture of Gaussians, and a simple sample-based loss function to train it in an off-policy regime. We empirically evaluate its performance on a broad range of continuous control tasks and demonstrate that it eliminates the need for these distributional hyperparameters and achieves state-of-the-art performance on a variety of challenging tasks (e.g. the humanoid, dog, quadruped, and manipulator domains). Finallywe provide an implementation in the Acme agent repository.
Offline Distillation for Robot Lifelong Learning with Imbalanced Experience
Apr 12, 2022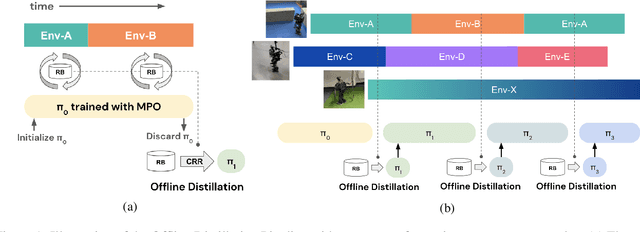
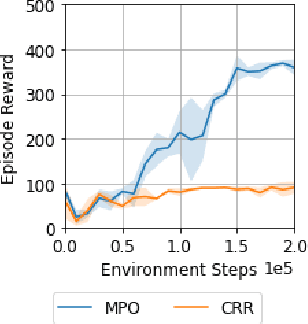
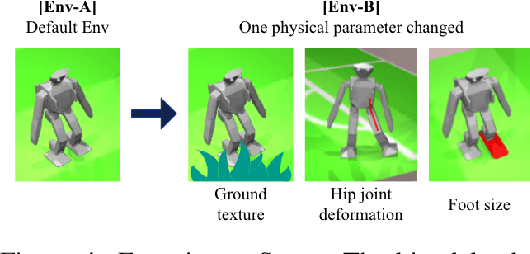
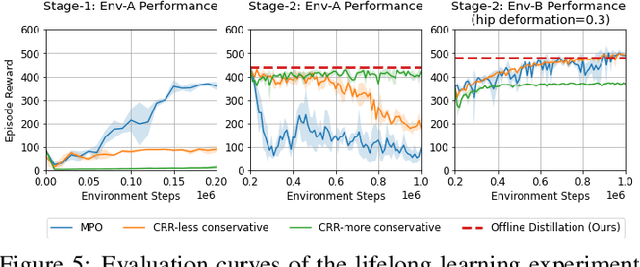
Robots will experience non-stationary environment dynamics throughout their lifetime: the robot dynamics can change due to wear and tear, or its surroundings may change over time. Eventually, the robots should perform well in all of the environment variations it has encountered. At the same time, it should still be able to learn fast in a new environment. We investigate two challenges in such a lifelong learning setting: first, existing off-policy algorithms struggle with the trade-off between being conservative to maintain good performance in the old environment and learning efficiently in the new environment. We propose the Offline Distillation Pipeline to break this trade-off by separating the training procedure into interleaved phases of online interaction and offline distillation. Second, training with the combined datasets from multiple environments across the lifetime might create a significant performance drop compared to training on the datasets individually. Our hypothesis is that both the imbalanced quality and size of the datasets exacerbate the extrapolation error of the Q-function during offline training over the "weaker" dataset. We propose a simple fix to the issue by keeping the policy closer to the dataset during the distillation phase. In the experiments, we demonstrate these challenges and the proposed solutions with a simulated bipedal robot walking task across various environment changes. We show that the Offline Distillation Pipeline achieves better performance across all the encountered environments without affecting data collection. We also provide a comprehensive empirical study to support our hypothesis on the data imbalance issue.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
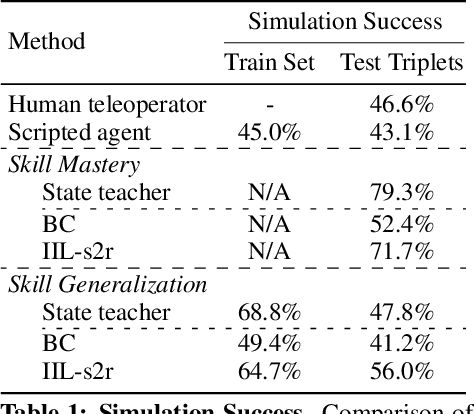
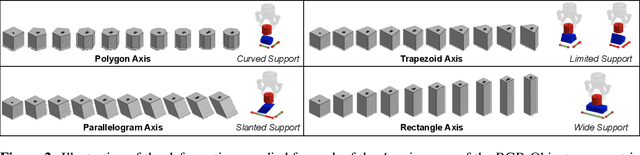
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
Evaluating model-based planning and planner amortization for continuous control
Oct 07, 2021
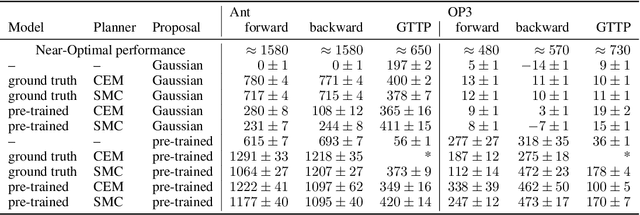
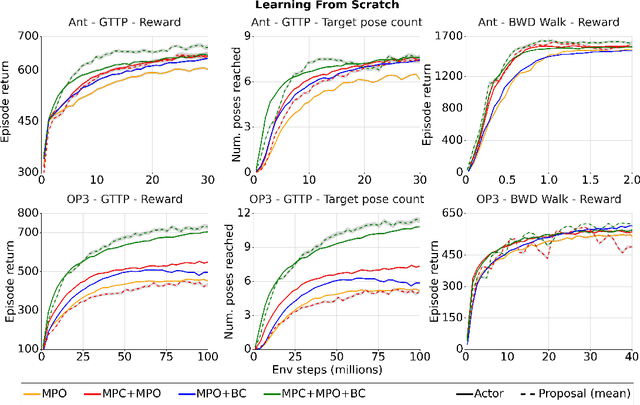
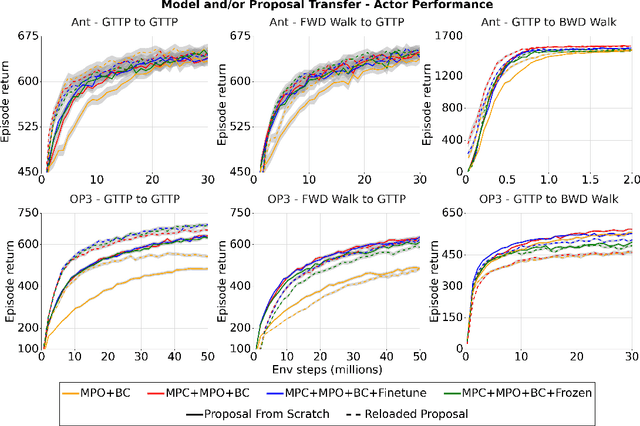
There is a widespread intuition that model-based control methods should be able to surpass the data efficiency of model-free approaches. In this paper we attempt to evaluate this intuition on various challenging locomotion tasks. We take a hybrid approach, combining model predictive control (MPC) with a learned model and model-free policy learning; the learned policy serves as a proposal for MPC. We find that well-tuned model-free agents are strong baselines even for high DoF control problems but MPC with learned proposals and models (trained on the fly or transferred from related tasks) can significantly improve performance and data efficiency in hard multi-task/multi-goal settings. Finally, we show that it is possible to distil a model-based planner into a policy that amortizes the planning computation without any loss of performance. Videos of agents performing different tasks can be seen at https://sites.google.com/view/mbrl-amortization/home.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021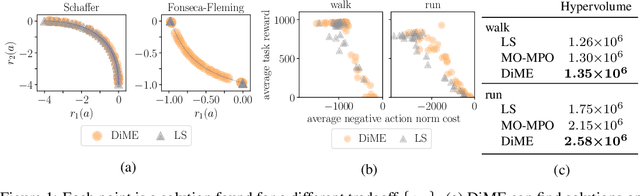
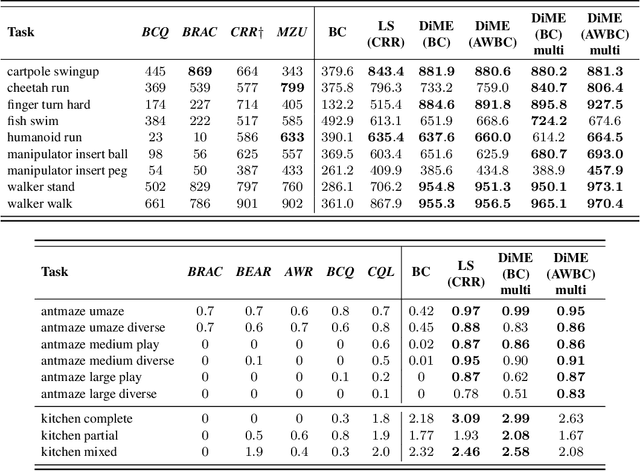
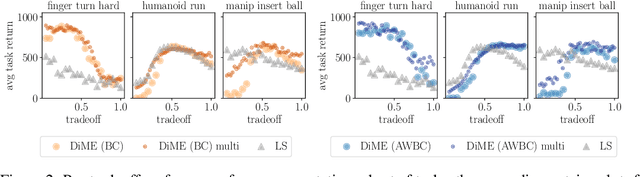

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021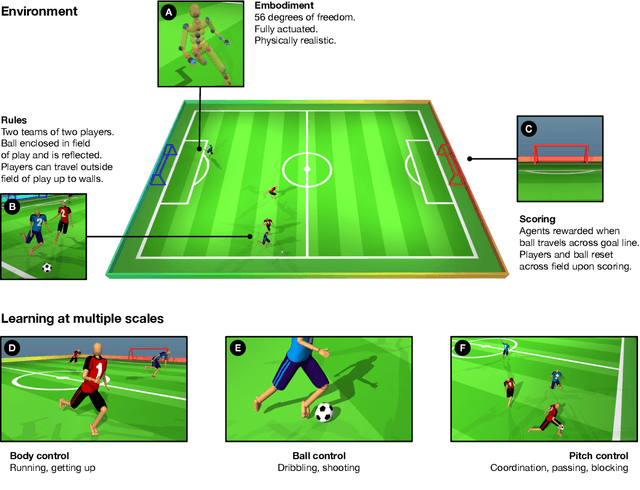

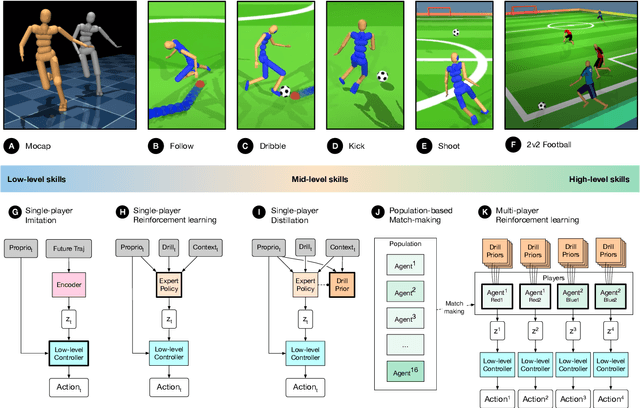

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Rethinking Exploration for Sample-Efficient Policy Learning
Jan 23, 2021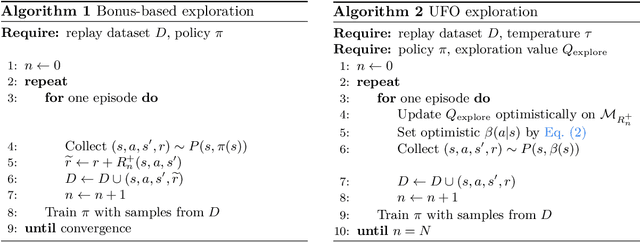
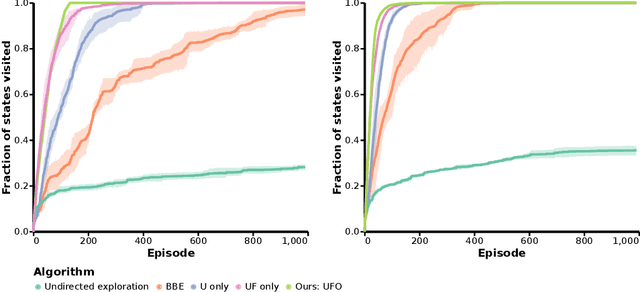
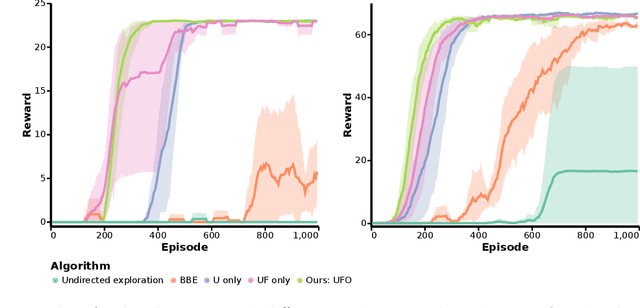
Off-policy reinforcement learning for control has made great strides in terms of performance and sample efficiency. We suggest that for many tasks the sample efficiency of modern methods is now limited by the richness of the data collected rather than the difficulty of policy fitting. We examine the reasons that directed exploration methods in the bonus-based exploration (BBE) family have not been more influential in the sample efficient control problem. Three issues have limited the applicability of BBE: bias with finite samples, slow adaptation to decaying bonuses, and lack of optimism on unseen transitions. We propose modifications to the bonus-based exploration recipe to address each of these limitations. The resulting algorithm, which we call UFO, produces policies that are Unbiased with finite samples, Fast-adapting as the exploration bonus changes, and Optimistic with respect to new transitions. We include experiments showing that rapid directed exploration is a promising direction to improve sample efficiency for control.
"What, not how": Solving an under-actuated insertion task from scratch
Oct 30, 2020

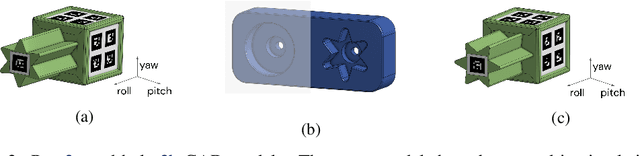
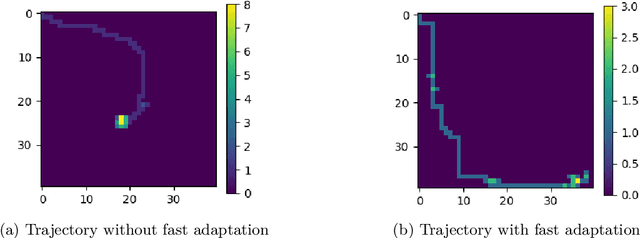
Robot manipulation requires a complex set of skills that need to be carefully combined and coordinated to solve a task. Yet, most ReinforcementLearning (RL) approaches in robotics study tasks which actually consist only of a single manipulation skill, such as grasping an object or inserting a pre-grasped object. As a result the skill ('how' to solve the task) but not the actual goal of a complete manipulation ('what' to solve) is specified. In contrast, we study a complex manipulation goal that requires an agent to learn and combine diverse manipulation skills. We propose a challenging, highly under-actuated peg-in-hole task with a free, rotational asymmetrical peg, requiring a broad range of manipulation skills. While correct peg (re-)orientation is a requirement for successful insertion, there is no reward associated with it. Hence an agent needs to understand this pre-condition and learn the skill to fulfil it. The final insertion reward is sparse, allowing freedom in the solution and leading to complex emerging behaviour not envisioned during the task design. We tackle the problem in a multi-task RL framework using Scheduled Auxiliary Control (SAC-X) combined with Regularized Hierarchical Policy Optimization (RHPO) which successfully solves the task in simulation and from scratch on a single robot where data is severely limited.