 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Global-Local Self-Distillation for Visual Representation Learning
Jul 29, 2022

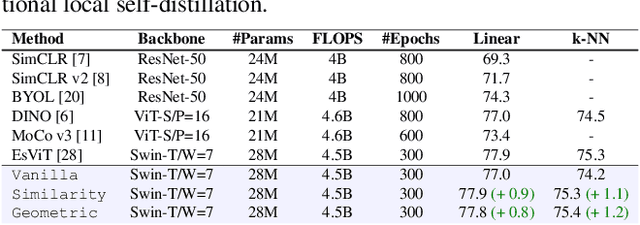

The downstream accuracy of self-supervised methods is tightly linked to the proxy task solved during training and the quality of the gradients extracted from it. Richer and more meaningful gradients updates are key to allow self-supervised methods to learn better and in a more efficient manner. In a typical self-distillation framework, the representation of two augmented images are enforced to be coherent at the global level. Nonetheless, incorporating local cues in the proxy task can be beneficial and improve the model accuracy on downstream tasks. This leads to a dual objective in which, on the one hand, coherence between global-representations is enforced and on the other, coherence between local-representations is enforced. Unfortunately, an exact correspondence mapping between two sets of local-representations does not exist making the task of matching local-representations from one augmentation to another non-trivial. We propose to leverage the spatial information in the input images to obtain geometric matchings and compare this geometric approach against previous methods based on similarity matchings. Our study shows that not only 1) geometric matchings perform better than similarity based matchings in low-data regimes but also 2) that similarity based matchings are highly hurtful in low-data regimes compared to the vanilla baseline without local self-distillation. The code will be released upon acceptance.
FedRel: An Adaptive Federated Relevance Framework for Spatial Temporal Graph Learning
Jun 07, 2022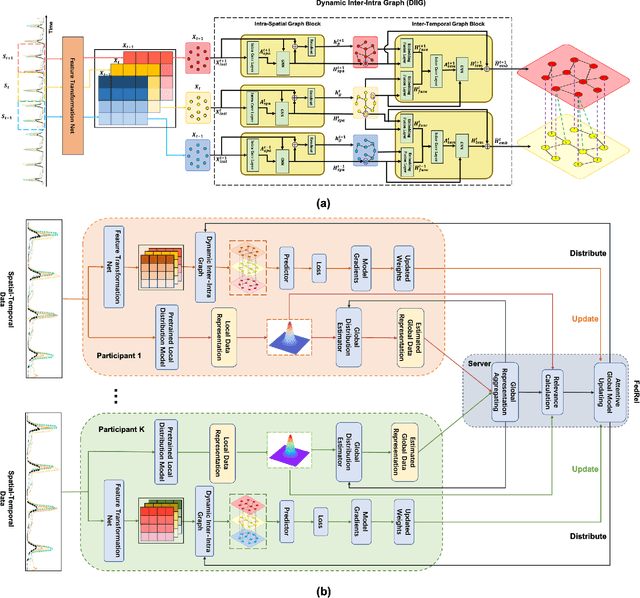
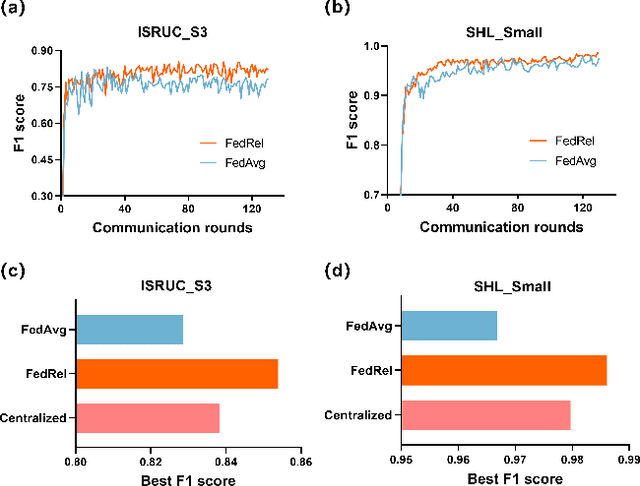

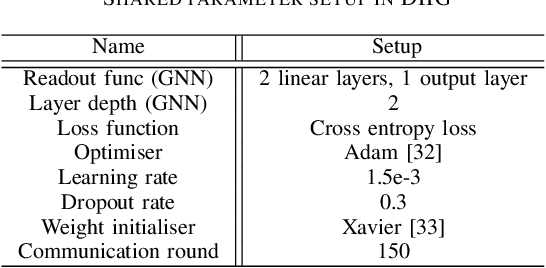
Spatial-temporal data contains rich information and has been widely studied in recent years due to the rapid development of relevant applications in many fields. For instance, medical institutions often use electrodes attached to different parts of a patient to analyse the electorencephal data rich with spatial and temporal features for health assessment and disease diagnosis. Existing research has mainly used deep learning techniques such as convolutional neural network (CNN) or recurrent neural network (RNN) to extract hidden spatial-temporal features. Yet, it is challenging to incorporate both inter-dependencies spatial information and dynamic temporal changes simultaneously. In reality, for a model that leverages these spatial-temporal features to fulfil complex prediction tasks, it often requires a colossal amount of training data in order to obtain satisfactory model performance. Considering the above-mentioned challenges, we propose an adaptive federated relevance framework, namely FedRel, for spatial-temporal graph learning in this paper. After transforming the raw spatial-temporal data into high quality features, the core Dynamic Inter-Intra Graph (DIIG) module in the framework is able to use these features to generate the spatial-temporal graphs capable of capturing the hidden topological and long-term temporal correlation information in these graphs. To improve the model generalization ability and performance while preserving the local data privacy, we also design a relevance-driven federated learning module in our framework to leverage diverse data distributions from different participants with attentive aggregations of their models.
Understanding the Information Needs and Practices of Human Supporters of an Online Mental Health Intervention to Inform Machine Learning Applications
Nov 12, 2021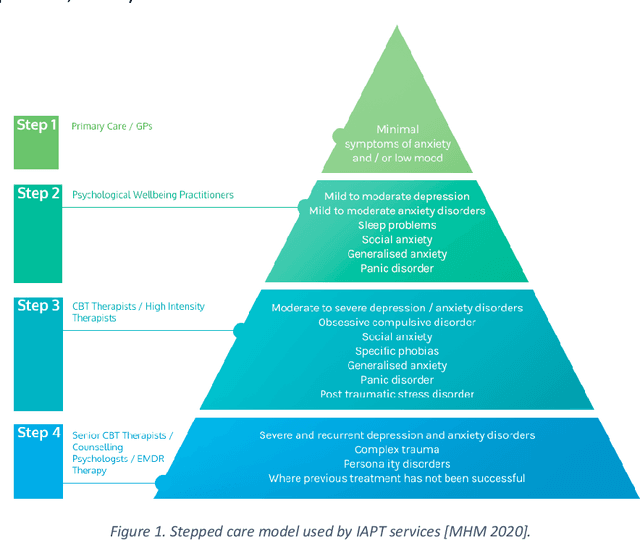
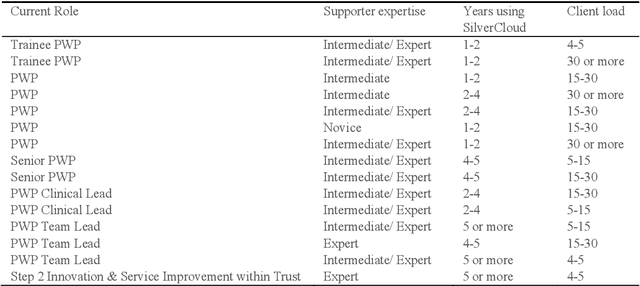
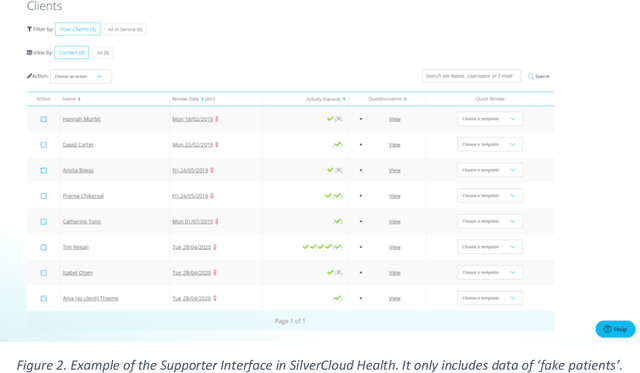

In the context of digital therapy interventions, such as internet-delivered Cognitive Behavioral Therapy (iCBT) for the treatment of depression and anxiety, extensive research has shown how the involvement of a human supporter or coach, who assists the person undergoing treatment, improves user engagement in therapy and leads to more effective health outcomes than unsupported interventions. Seeking to maximize the effects and outcomes of this human support, the research investigates how new opportunities provided through recent advances in the field of AI and machine learning (ML) can contribute useful data insights to effectively support the work practices of iCBT supporters. This paper reports detailed findings of an interview study with 15 iCBT supporters that deepens understanding of their existing work practices and information needs with the aim to meaningfully inform the development of useful, implementable ML applications particularly in the context of iCBT treatment for depression and anxiety. The analysis contributes (1) a set of six themes that summarize the strategies and challenges that iCBT supporters encounter in providing effective, personalized feedback to their mental health clients; and in response to these learnings, (2) presents for each theme concrete opportunities for how methods of ML could help support and address identified challenges and information needs. It closes with reflections on potential social, emotional and pragmatic implications of introducing new machine-generated data insights within supporter-led client review practices.
QASem Parsing: Text-to-text Modeling of QA-based Semantics
May 23, 2022
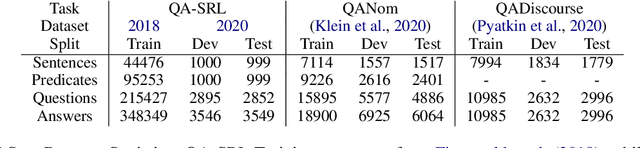
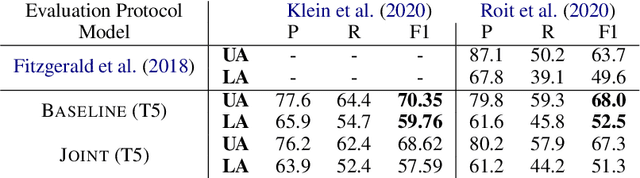
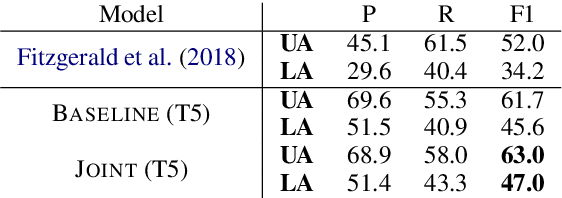
Several recent works have suggested to represent semantic relations with questions and answers, decomposing textual information into separate interrogative natural language statements. In this paper, we consider three QA-based semantic tasks - namely, QA-SRL, QANom and QADiscourse, each targeting a certain type of predication - and propose to regard them as jointly providing a comprehensive representation of textual information. To promote this goal, we investigate how to best utilize the power of sequence-to-sequence (seq2seq) pre-trained language models, within the unique setup of semi-structured outputs, consisting of an unordered set of question-answer pairs. We examine different input and output linearization strategies, and assess the effect of multitask learning and of simple data augmentation techniques in the setting of imbalanced training data. Consequently, we release the first unified QASem parsing tool, practical for downstream applications who can benefit from an explicit, QA-based account of information units in a text.
MTGFlow: Unsupervised Multivariate Time Series Anomaly Detection via Dynamic Graph and Entity-aware Normalizing Flow
Aug 03, 2022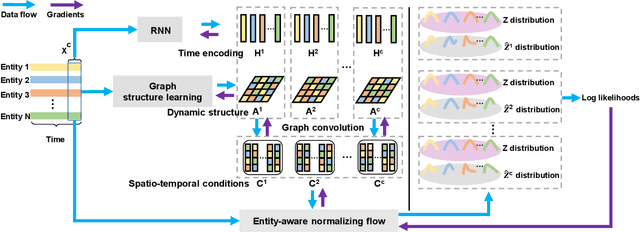

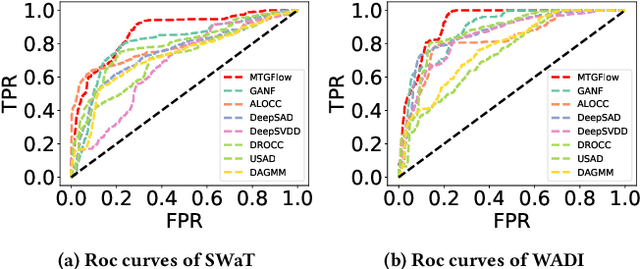

Multivariate time series anomaly detection has been extensively studied under the semi-supervised setting, where a training dataset with all normal instances is required. However, preparing such a dataset is very laborious since each single data instance should be fully guaranteed to be normal. It is, therefore, desired to explore multivariate time series anomaly detection methods based on the dataset without any label knowledge. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for Multivariate Time series anomaly detection via dynamic Graph and entity-aware normalizing Flow, leaning only on a widely accepted hypothesis that abnormal instances exhibit sparse densities than the normal. However, the complex interdependencies among entities and the diverse inherent characteristics of each entity pose significant challenges on the density estimation, let alone to detect anomalies based on the estimated possibility distribution. To tackle these problems, we propose to learn the mutual and dynamic relations among entities via a graph structure learning model, which helps to model accurate distribution of multivariate time series. Moreover, taking account of distinct characteristics of the individual entities, an entity-aware normalizing flow is developed to describe each entity into a parameterized normal distribution, thereby producing fine-grained density estimation. Incorporating these two strategies, MTGFlowachieves superior anomaly detection performance. Experiments on the real-world datasets are conducted, demonstrating that MTGFlow outperforms the state-of-the-art (SOTA) by 5.0% and 1.6% AUROC for SWaT and WADI datasets respectively. Also, through the anomaly scores contributed by individual entities, MTGFlow can provide explanation information for the detection results.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022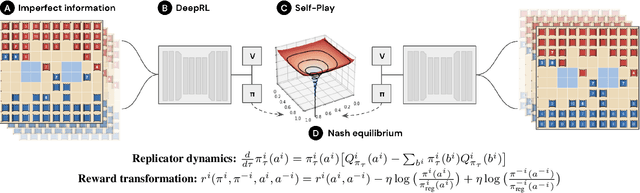
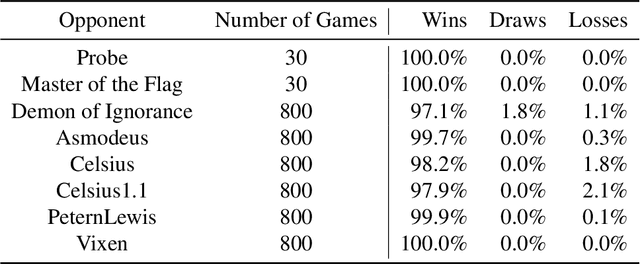
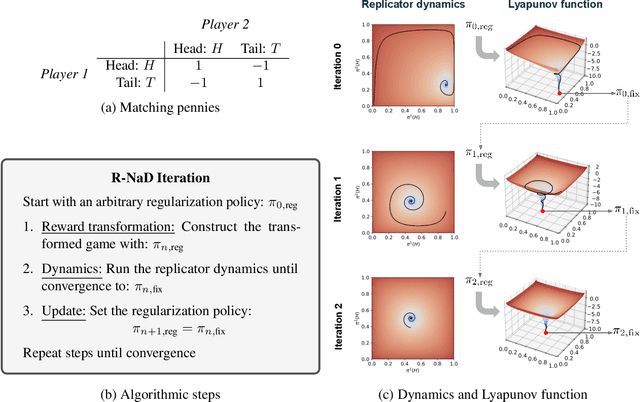

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Self-organized Polygon Formation Control based on Distributed Estimation
Aug 01, 2022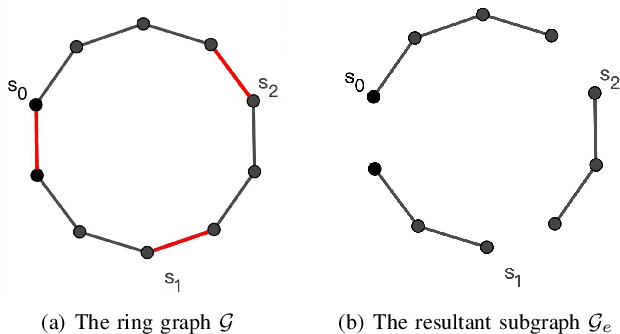
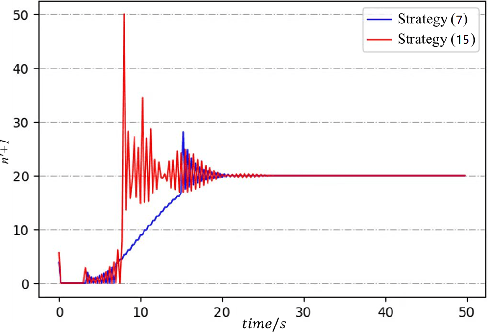
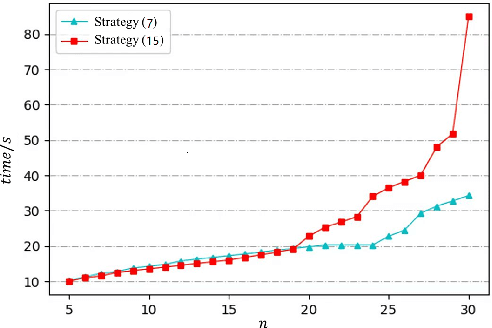
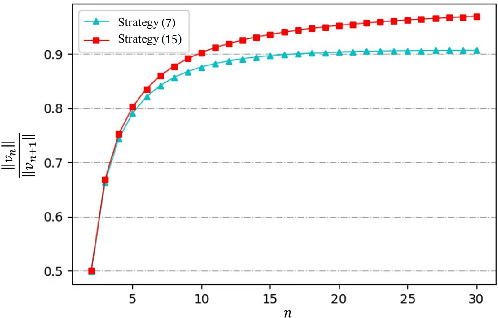
This paper studies the problem of controlling a multi-robot system to achieve a polygon formation in a self-organized manner. Different from the typical formation control strategies where robots are steered to satisfy the predefined control variables, such as pairwise distances, relative positions and bearings, the foremost idea of this paper is to achieve polygon formations by injecting control inputs randomly to a few robots (say, vertex robots) of the group, and the rest follow the simple principles of moving towards the midpoint of their two nearest neighbors in the ring graph without any external inputs. In our problem, a fleet of robots is initially distributed in the plane. The socalled vertex robots take the responsibility of determining the geometric shape of the entire formation and its overall size, while the others move so as to minimize the differences with two direct neighbors. In the first step, each vertex robot estimates the number of robots in its associated chain. Two types of control inputs that serve for the estimation are designed using the measurements from the latest and the last two time instants respectively. In the second step, the self-organized formation control law is proposed where only vertex robots receive external information. Comparisons between the two estimation strategies are carried out in terms of the convergence speed and robustness. The effectiveness of the whole control framework is further validated in both simulation and physical experiments.
Content-Aware Differential Privacy with Conditional Invertible Neural Networks
Jul 29, 2022
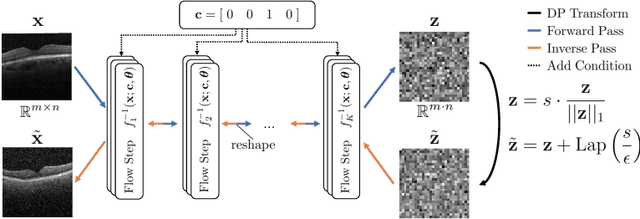

Differential privacy (DP) has arisen as the gold standard in protecting an individual's privacy in datasets by adding calibrated noise to each data sample. While the application to categorical data is straightforward, its usability in the context of images has been limited. Contrary to categorical data the meaning of an image is inherent in the spatial correlation of neighboring pixels making the simple application of noise infeasible. Invertible Neural Networks (INN) have shown excellent generative performance while still providing the ability to quantify the exact likelihood. Their principle is based on transforming a complicated distribution into a simple one e.g. an image into a spherical Gaussian. We hypothesize that adding noise to the latent space of an INN can enable differentially private image modification. Manipulation of the latent space leads to a modified image while preserving important details. Further, by conditioning the INN on meta-data provided with the dataset we aim at leaving dimensions important for downstream tasks like classification untouched while altering other parts that potentially contain identifying information. We term our method content-aware differential privacy (CADP). We conduct experiments on publicly available benchmarking datasets as well as dedicated medical ones. In addition, we show the generalizability of our method to categorical data. The source code is publicly available at https://github.com/Cardio-AI/CADP.
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022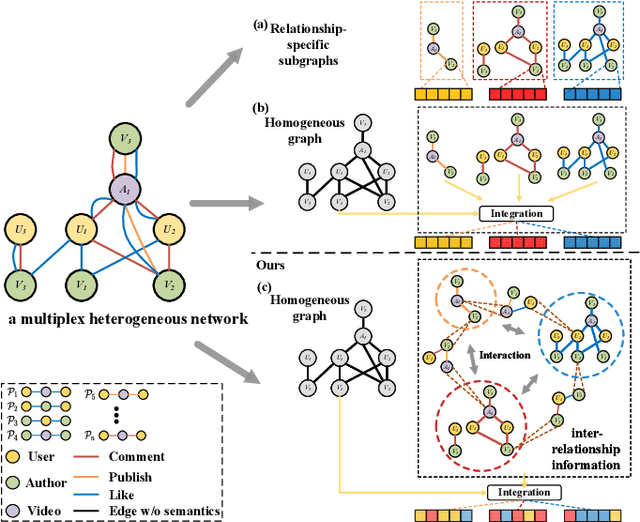
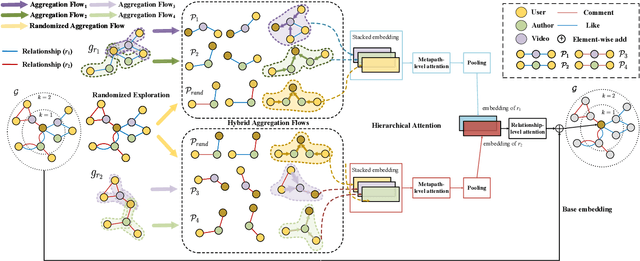
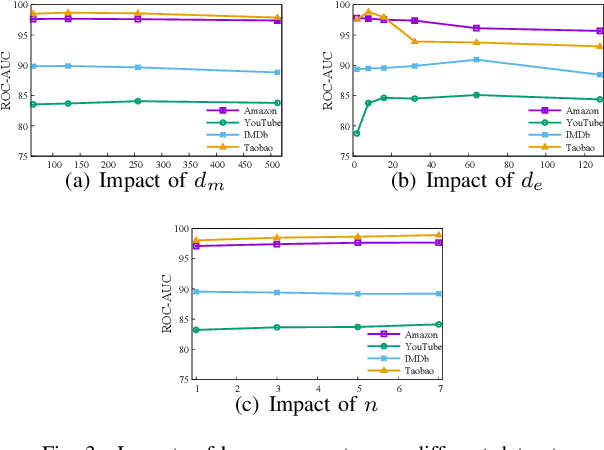
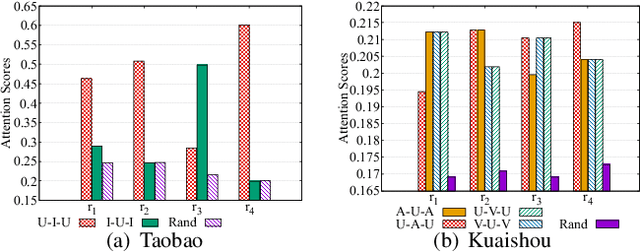
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.
OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers
Jul 08, 2022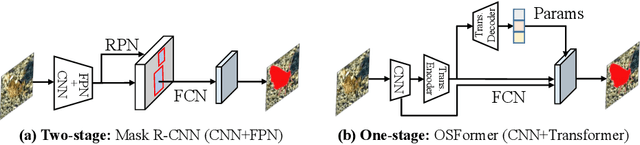
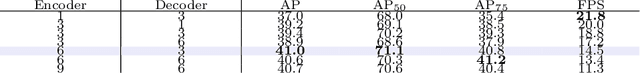

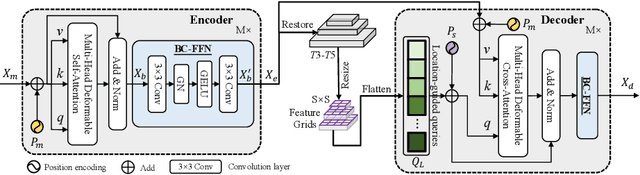
We present OSFormer, the first one-stage transformer framework for camouflaged instance segmentation (CIS). OSFormer is based on two key designs. First, we design a location-sensing transformer (LST) to obtain the location label and instance-aware parameters by introducing the location-guided queries and the blend-convolution feedforward network. Second, we develop a coarse-to-fine fusion (CFF) to merge diverse context information from the LST encoder and CNN backbone. Coupling these two components enables OSFormer to efficiently blend local features and long-range context dependencies for predicting camouflaged instances. Compared with two-stage frameworks, our OSFormer reaches 41% AP and achieves good convergence efficiency without requiring enormous training data, i.e., only 3,040 samples under 60 epochs. Code link: https://github.com/PJLallen/OSFormer.