 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective QA-driven Annotation of Predicate-Argument Relations Across Languages
Feb 26, 2026Explicit representations of predicate-argument relations form the basis of interpretable semantic analysis, supporting reasoning, generation, and evaluation. However, attaining such semantic structures requires costly annotation efforts and has remained largely confined to English. We leverage the Question-Answer driven Semantic Role Labeling (QA-SRL) framework -- a natural-language formulation of predicate-argument relations -- as the foundation for extending semantic annotation to new languages. To this end, we introduce a cross-linguistic projection approach that reuses an English QA-SRL parser within a constrained translation and word-alignment pipeline to automatically generate question-answer annotations aligned with target-language predicates. Applied to Hebrew, Russian, and French -- spanning diverse language families -- the method yields high-quality training data and fine-tuned, language-specific parsers that outperform strong multilingual LLM baselines (GPT-4o, LLaMA-Maverick). By leveraging QA-SRL as a transferable natural-language interface for semantics, our approach enables efficient and broadly accessible predicate-argument parsing across languages.
User-Centric Evidence Ranking for Attribution and Fact Verification
Jan 29, 2026Attribution and fact verification are critical challenges in natural language processing for assessing information reliability. While automated systems and Large Language Models (LLMs) aim to retrieve and select concise evidence to support or refute claims, they often present users with either insufficient or overly redundant information, leading to inefficient and error-prone verification. To address this, we propose Evidence Ranking, a novel task that prioritizes presenting sufficient information as early as possible in a ranked list. This minimizes user reading effort while still making all available evidence accessible for sequential verification. We compare two approaches for the new ranking task: one-shot ranking and incremental ranking. We introduce a new evaluation framework, inspired by information retrieval metrics, and construct a unified benchmark by aggregating existing fact verification datasets. Extensive experiments with diverse models show that incremental ranking strategies better capture complementary evidence and that LLM-based methods outperform shallower baselines, while still facing challenges in balancing sufficiency and redundancy. Compared to evidence selection, we conduct a controlled user study and demonstrate that evidence ranking both reduces reading effort and improves verification. This work provides a foundational step toward more interpretable, efficient, and user-aligned information verification systems.
QA-Noun: Representing Nominal Semantics via Natural Language Question-Answer Pairs
Nov 16, 2025
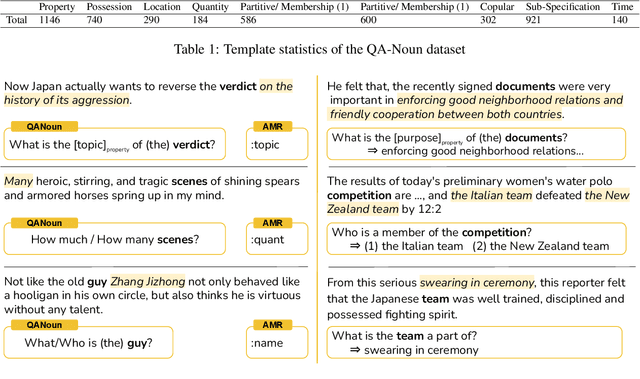
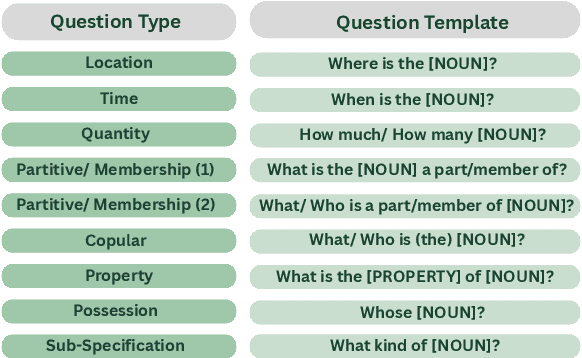
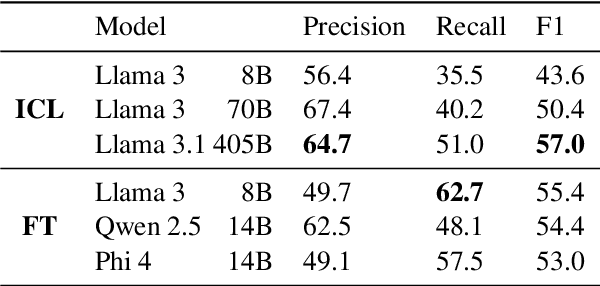
Decomposing sentences into fine-grained meaning units is increasingly used to model semantic alignment. While QA-based semantic approaches have shown effectiveness for representing predicate-argument relations, they have so far left noun-centered semantics largely unaddressed. We introduce QA-Noun, a QA-based framework for capturing noun-centered semantic relations. QA-Noun defines nine question templates that cover both explicit syntactical and implicit contextual roles for nouns, producing interpretable QA pairs that complement verbal QA-SRL. We release detailed guidelines, a dataset of over 2,000 annotated noun mentions, and a trained model integrated with QA-SRL to yield a unified decomposition of sentence meaning into individual, highly fine-grained, facts. Evaluation shows that QA-Noun achieves near-complete coverage of AMR's noun arguments while surfacing additional contextually implied relations, and that combining QA-Noun with QA-SRL yields over 130\% higher granularity than recent fact-based decomposition methods such as FactScore and DecompScore. QA-Noun thus complements the broader QA-based semantic framework, forming a comprehensive and scalable approach to fine-grained semantic decomposition for cross-text alignment.
Small Models, Big Results: Achieving Superior Intent Extraction through Decomposition
Sep 15, 2025Understanding user intents from UI interaction trajectories remains a challenging, yet crucial, frontier in intelligent agent development. While massive, datacenter-based, multi-modal large language models (MLLMs) possess greater capacity to handle the complexities of such sequences, smaller models which can run on-device to provide a privacy-preserving, low-cost, and low-latency user experience, struggle with accurate intent inference. We address these limitations by introducing a novel decomposed approach: first, we perform structured interaction summarization, capturing key information from each user action. Second, we perform intent extraction using a fine-tuned model operating on the aggregated summaries. This method improves intent understanding in resource-constrained models, even surpassing the base performance of large MLLMs.
Consensus or Conflict? Fine-Grained Evaluation of Conflicting Answers in Question-Answering
Aug 17, 2025Large Language Models (LLMs) have demonstrated strong performance in question answering (QA) tasks. However, Multi-Answer Question Answering (MAQA), where a question may have several valid answers, remains challenging. Traditional QA settings often assume consistency across evidences, but MAQA can involve conflicting answers. Constructing datasets that reflect such conflicts is costly and labor-intensive, while existing benchmarks often rely on synthetic data, restrict the task to yes/no questions, or apply unverified automated annotation. To advance research in this area, we extend the conflict-aware MAQA setting to require models not only to identify all valid answers, but also to detect specific conflicting answer pairs, if any. To support this task, we introduce a novel cost-effective methodology for leveraging fact-checking datasets to construct NATCONFQA, a new benchmark for realistic, conflict-aware MAQA, enriched with detailed conflict labels, for all answer pairs. We evaluate eight high-end LLMs on NATCONFQA, revealing their fragility in handling various types of conflicts and the flawed strategies they employ to resolve them.
A Unifying Scheme for Extractive Content Selection Tasks
Jul 22, 2025A broad range of NLP tasks involve selecting relevant text spans from given source texts. Despite this shared objective, such \textit{content selection} tasks have traditionally been studied in isolation, each with its own modeling approaches, datasets, and evaluation metrics. In this work, we propose \textit{instruction-guided content selection (IGCS)} as a beneficial unified framework for such settings, where the task definition and any instance-specific request are encapsulated as instructions to a language model. To promote this framework, we introduce \igcsbench{}, the first unified benchmark covering diverse content selection tasks. Further, we create a large generic synthetic dataset that can be leveraged for diverse content selection tasks, and show that transfer learning with these datasets often boosts performance, whether dedicated training for the targeted task is available or not. Finally, we address generic inference time issues that arise in LLM-based modeling of content selection, assess a generic evaluation metric, and overall propose the utility of our resources and methods for future content selection models. Models and datasets available at https://github.com/shmuelamar/igcs.
GenerationPrograms: Fine-grained Attribution with Executable Programs
Jun 17, 2025



Recent large language models (LLMs) achieve impressive performance in source-conditioned text generation but often fail to correctly provide fine-grained attributions for their outputs, undermining verifiability and trust. Moreover, existing attribution methods do not explain how and why models leverage the provided source documents to generate their final responses, limiting interpretability. To overcome these challenges, we introduce a modular generation framework, GenerationPrograms, inspired by recent advancements in executable "code agent" architectures. Unlike conventional generation methods that simultaneously generate outputs and attributions or rely on post-hoc attribution, GenerationPrograms decomposes the process into two distinct stages: first, creating an executable program plan composed of modular text operations (such as paraphrasing, compression, and fusion) explicitly tailored to the query, and second, executing these operations following the program's specified instructions to produce the final response. Empirical evaluations demonstrate that GenerationPrograms significantly improves attribution quality at both the document level and sentence level across two long-form question-answering tasks and a multi-document summarization task. We further demonstrate that GenerationPrograms can effectively function as a post-hoc attribution method, outperforming traditional techniques in recovering accurate attributions. In addition, the interpretable programs generated by GenerationPrograms enable localized refinement through modular-level improvements that further enhance overall attribution quality.
CLATTER: Comprehensive Entailment Reasoning for Hallucination Detection
Jun 05, 2025A common approach to hallucination detection casts it as a natural language inference (NLI) task, often using LLMs to classify whether the generated text is entailed by corresponding reference texts. Since entailment classification is a complex reasoning task, one would expect that LLMs could benefit from generating an explicit reasoning process, as in CoT reasoning or the explicit ``thinking'' of recent reasoning models. In this work, we propose that guiding such models to perform a systematic and comprehensive reasoning process -- one that both decomposes the text into smaller facts and also finds evidence in the source for each fact -- allows models to execute much finer-grained and accurate entailment decisions, leading to increased performance. To that end, we define a 3-step reasoning process, consisting of (i) claim decomposition, (ii) sub-claim attribution and entailment classification, and (iii) aggregated classification, showing that such guided reasoning indeed yields improved hallucination detection. Following this reasoning framework, we introduce an analysis scheme, consisting of several metrics that measure the quality of the intermediate reasoning steps, which provided additional empirical evidence for the improved quality of our guided reasoning scheme.
EventFull: Complete and Consistent Event Relation Annotation
Dec 17, 2024



Event relation detection is a fundamental NLP task, leveraged in many downstream applications, whose modeling requires datasets annotated with event relations of various types. However, systematic and complete annotation of these relations is costly and challenging, due to the quadratic number of event pairs that need to be considered. Consequently, many current event relation datasets lack systematicity and completeness. In response, we introduce \textit{EventFull}, the first tool that supports consistent, complete and efficient annotation of temporal, causal and coreference relations via a unified and synergetic process. A pilot study demonstrates that EventFull accelerates and simplifies the annotation process while yielding high inter-annotator agreement.
QAPyramid: Fine-grained Evaluation of Content Selection for Text Summarization
Dec 10, 2024



How to properly conduct human evaluations for text summarization is a longstanding challenge. The Pyramid human evaluation protocol, which assesses content selection by breaking the reference summary into sub-units and verifying their presence in the system summary, has been widely adopted. However, it suffers from a lack of systematicity in the definition and granularity of the sub-units. We address these problems by proposing QAPyramid, which decomposes each reference summary into finer-grained question-answer (QA) pairs according to the QA-SRL framework. We collect QA-SRL annotations for reference summaries from CNN/DM and evaluate 10 summarization systems, resulting in 8.9K QA-level annotations. We show that, compared to Pyramid, QAPyramid provides more systematic and fine-grained content selection evaluation while maintaining high inter-annotator agreement without needing expert annotations. Furthermore, we propose metrics that automate the evaluation pipeline and achieve higher correlations with QAPyramid than other widely adopted metrics, allowing future work to accurately and efficiently benchmark summarization systems.