 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of AI Data Transparency Policy: Three Disclosure Fallacies
Jan 26, 2026Data transparency has emerged as a rallying cry for addressing concerns about AI: data quality, privacy, and copyright chief among them. Yet while these calls are crucial for accountability, current transparency policies often fall short of their intended aims. Similar to nutrition facts for food, policies aimed at nutrition facts for AI currently suffer from a limited consideration of research on effective disclosures. We offer an institutional perspective and identify three common fallacies in policy implementations of data disclosures for AI. First, many data transparency proposals exhibit a specification gap between the stated goals of data transparency and the actual disclosures necessary to achieve such goals. Second, reform attempts exhibit an enforcement gap between required disclosures on paper and enforcement to ensure compliance in fact. Third, policy proposals manifest an impact gap between disclosed information and meaningful changes in developer practices and public understanding. Informed by the social science on transparency, our analysis identifies affirmative paths for transparency that are effective rather than merely symbolic.
AI Supply Chains: An Emerging Ecosystem of AI Actors, Products, and Services
Apr 28, 2025The widespread adoption of AI in recent years has led to the emergence of AI supply chains: complex networks of AI actors contributing models, datasets, and more to the development of AI products and services. AI supply chains have many implications yet are poorly understood. In this work, we take a first step toward a formal study of AI supply chains and their implications, providing two illustrative case studies indicating that both AI development and regulation are complicated in the presence of supply chains. We begin by presenting a brief historical perspective on AI supply chains, discussing how their rise reflects a longstanding shift towards specialization and outsourcing that signals the healthy growth of the AI industry. We then model AI supply chains as directed graphs and demonstrate the power of this abstraction by connecting examples of AI issues to graph properties. Finally, we examine two case studies in detail, providing theoretical and empirical results in both. In the first, we show that information passing (specifically, of explanations) along the AI supply chains is imperfect, which can result in misunderstandings that have real-world implications. In the second, we show that upstream design choices (e.g., by base model providers) have downstream consequences (e.g., on AI products fine-tuned on the base model). Together, our findings motivate further study of AI supply chains and their increasingly salient social, economic, regulatory, and technical implications.
From Transparency to Accountability and Back: A Discussion of Access and Evidence in AI Auditing
Oct 07, 2024Artificial intelligence (AI) is increasingly intervening in our lives, raising widespread concern about its unintended and undeclared side effects. These developments have brought attention to the problem of AI auditing: the systematic evaluation and analysis of an AI system, its development, and its behavior relative to a set of predetermined criteria. Auditing can take many forms, including pre-deployment risk assessments, ongoing monitoring, and compliance testing. It plays a critical role in providing assurances to various AI stakeholders, from developers to end users. Audits may, for instance, be used to verify that an algorithm complies with the law, is consistent with industry standards, and meets the developer's claimed specifications. However, there are many operational challenges to AI auditing that complicate its implementation. In this work, we examine a key operational issue in AI auditing: what type of access to an AI system is needed to perform a meaningful audit? Addressing this question has direct policy relevance, as it can inform AI audit guidelines and requirements. We begin by discussing the factors that auditors balance when determining the appropriate type of access, and unpack the benefits and drawbacks of four types of access. We conclude that, at minimum, black-box access -- providing query access to a model without exposing its internal implementation -- should be granted to auditors, as it balances concerns related to trade secrets, data privacy, audit standardization, and audit efficiency. We then suggest a framework for determining how much further access (in addition to black-box access) to grant auditors. We show that auditing can be cast as a natural hypothesis test, draw parallels hypothesis testing and legal procedure, and argue that this framing provides clear and interpretable guidance on audit implementation.
Measuring Strategization in Recommendation: Users Adapt Their Behavior to Shape Future Content
May 09, 2024



Most modern recommendation algorithms are data-driven: they generate personalized recommendations by observing users' past behaviors. A common assumption in recommendation is that how a user interacts with a piece of content (e.g., whether they choose to "like" it) is a reflection of the content, but not of the algorithm that generated it. Although this assumption is convenient, it fails to capture user strategization: that users may attempt to shape their future recommendations by adapting their behavior to the recommendation algorithm. In this work, we test for user strategization by conducting a lab experiment and survey. To capture strategization, we adopt a model in which strategic users select their engagement behavior based not only on the content, but also on how their behavior affects downstream recommendations. Using a custom music player that we built, we study how users respond to different information about their recommendation algorithm as well as to different incentives about how their actions affect downstream outcomes. We find strong evidence of strategization across outcome metrics, including participants' dwell time and use of "likes." For example, participants who are told that the algorithm mainly pays attention to "likes" and "dislikes" use those functions 1.9x more than participants told that the algorithm mainly pays attention to dwell time. A close analysis of participant behavior (e.g., in response to our incentive conditions) rules out experimenter demand as the main driver of these trends. Further, in our post-experiment survey, nearly half of participants self-report strategizing "in the wild," with some stating that they ignore content they actually like to avoid over-recommendation of that content in the future. Together, our findings suggest that user strategization is common and that platforms cannot ignore the effect of their algorithms on user behavior.
User Strategization and Trustworthy Algorithms
Dec 29, 2023



Many human-facing algorithms -- including those that power recommender systems or hiring decision tools -- are trained on data provided by their users. The developers of these algorithms commonly adopt the assumption that the data generating process is exogenous: that is, how a user reacts to a given prompt (e.g., a recommendation or hiring suggestion) depends on the prompt and not on the algorithm that generated it. For example, the assumption that a person's behavior follows a ground-truth distribution is an exogeneity assumption. In practice, when algorithms interact with humans, this assumption rarely holds because users can be strategic. Recent studies document, for example, TikTok users changing their scrolling behavior after learning that TikTok uses it to curate their feed, and Uber drivers changing how they accept and cancel rides in response to changes in Uber's algorithm. Our work studies the implications of this strategic behavior by modeling the interactions between a user and their data-driven platform as a repeated, two-player game. We first find that user strategization can actually help platforms in the short term. We then show that it corrupts platforms' data and ultimately hurts their ability to make counterfactual decisions. We connect this phenomenon to user trust, and show that designing trustworthy algorithms can go hand in hand with accurate estimation. Finally, we provide a formalization of trustworthiness that inspires potential interventions.
A User-Driven Framework for Regulating and Auditing Social Media
Apr 20, 2023



People form judgments and make decisions based on the information that they observe. A growing portion of that information is not only provided, but carefully curated by social media platforms. Although lawmakers largely agree that platforms should not operate without any oversight, there is little consensus on how to regulate social media. There is consensus, however, that creating a strict, global standard of "acceptable" content is untenable (e.g., in the US, it is incompatible with Section 230 of the Communications Decency Act and the First Amendment). In this work, we propose that algorithmic filtering should be regulated with respect to a flexible, user-driven baseline. We provide a concrete framework for regulating and auditing a social media platform according to such a baseline. In particular, we introduce the notion of a baseline feed: the content that a user would see without filtering (e.g., on Twitter, this could be the chronological timeline). We require that the feeds a platform filters contain "similar" informational content as their respective baseline feeds, and we design a principled way to measure similarity. This approach is motivated by related suggestions that regulations should increase user agency. We present an auditing procedure that checks whether a platform honors this requirement. Notably, the audit needs only black-box access to a platform's filtering algorithm, and it does not access or infer private user information. We provide theoretical guarantees on the strength of the audit. We further show that requiring closeness between filtered and baseline feeds does not impose a large performance cost, nor does it create echo chambers.
Matrix Estimation for Individual Fairness
Feb 04, 2023In recent years, multiple notions of algorithmic fairness have arisen. One such notion is individual fairness (IF), which requires that individuals who are similar receive similar treatment. In parallel, matrix estimation (ME) has emerged as a natural paradigm for handling noisy data with missing values. In this work, we connect the two concepts. We show that pre-processing data using ME can improve an algorithm's IF without sacrificing performance. Specifically, we show that using a popular ME method known as singular value thresholding (SVT) to pre-process the data provides a strong IF guarantee under appropriate conditions. We then show that, under analogous conditions, SVT pre-processing also yields estimates that are consistent and approximately minimax optimal. As such, the ME pre-processing step does not, under the stated conditions, increase the prediction error of the base algorithm, i.e., does not impose a fairness-performance trade-off. We verify these results on synthetic and real data.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022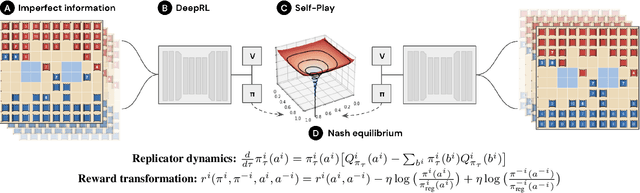
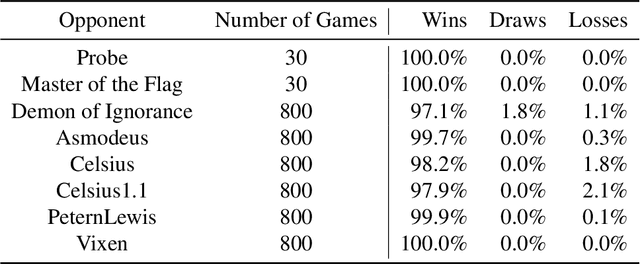
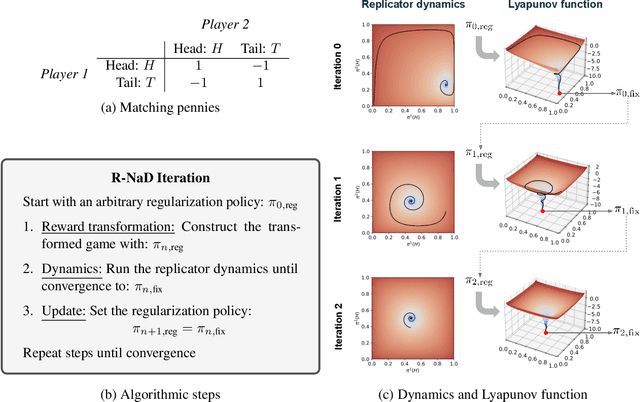

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Regret, stability, and fairness in matching markets with bandit learners
Feb 11, 2021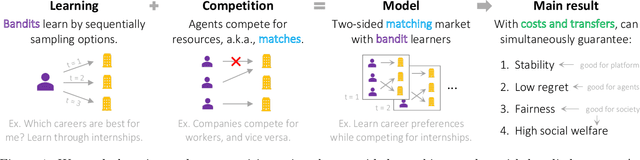
We consider the two-sided matching market with bandit learners. In the standard matching problem, users and providers are matched to ensure incentive compatibility via the notion of stability. However, contrary to the core assumption of the matching problem, users and providers do not know their true preferences a priori and must learn them. To address this assumption, recent works propose to blend the matching and multi-armed bandit problems. They establish that it is possible to assign matchings that are stable (i.e., incentive-compatible) at every time step while also allowing agents to learn enough so that the system converges to matchings that are stable under the agents' true preferences. However, while some agents may incur low regret under these matchings, others can incur high regret -- specifically, $\Omega(T)$ optimal regret where $T$ is the time horizon. In this work, we incorporate costs and transfers in the two-sided matching market with bandit learners in order to faithfully model competition between agents. We prove that, under our framework, it is possible to simultaneously guarantee four desiderata: (1) incentive compatibility, i.e., stability, (2) low regret, i.e., $O(\log(T))$ optimal regret, (3) fairness in the distribution of regret among agents, and (4) high social welfare.
Radar-only ego-motion estimation in difficult settings via graph matching
Apr 25, 2019
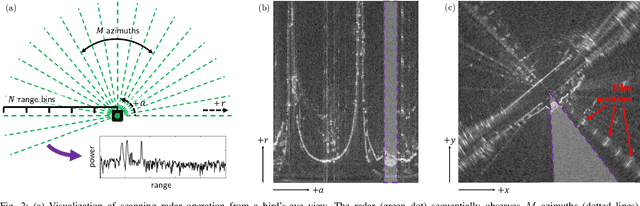

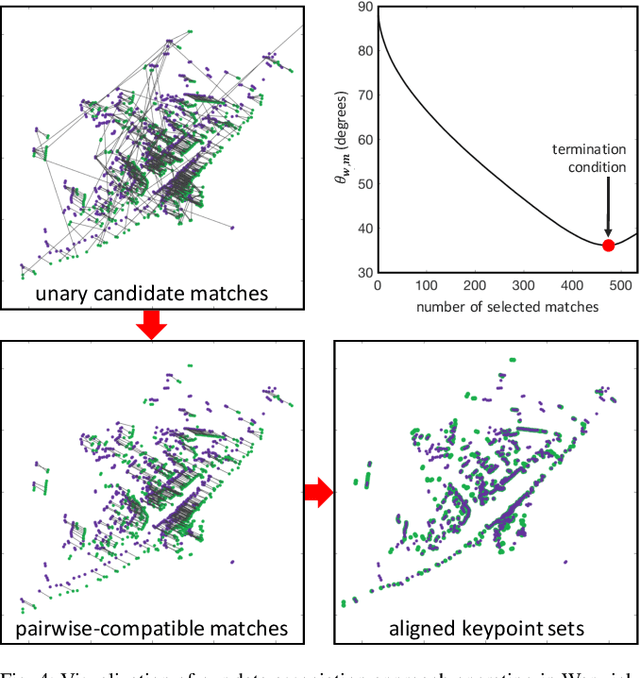
Radar detects stable, long-range objects under variable weather and lighting conditions, making it a reliable and versatile sensor well suited for ego-motion estimation. In this work, we propose a radar-only odometry pipeline that is highly robust to radar artifacts (e.g., speckle noise and false positives) and requires only one input parameter. We demonstrate its ability to adapt across diverse settings, from urban UK to off-road Iceland, achieving a scan matching accuracy of approximately 5.20 cm and 0.0929 deg when using GPS as ground truth (compared to visual odometry's 5.77 cm and 0.1032 deg). We present algorithms for keypoint extraction and data association, framing the latter as a graph matching optimization problem, and provide an in-depth system analysis.