 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022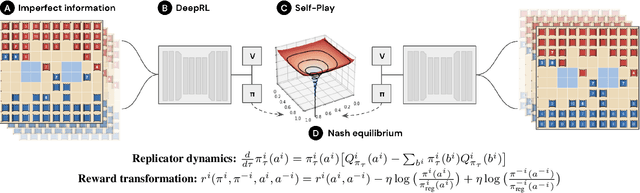
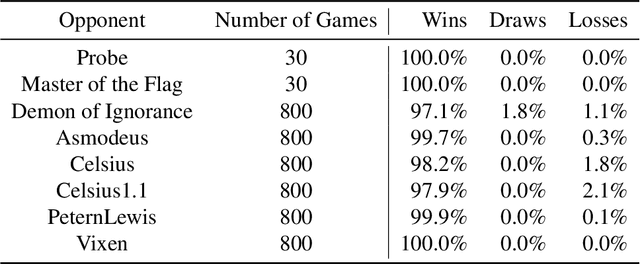

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Navigating the Landscape of Games
May 04, 2020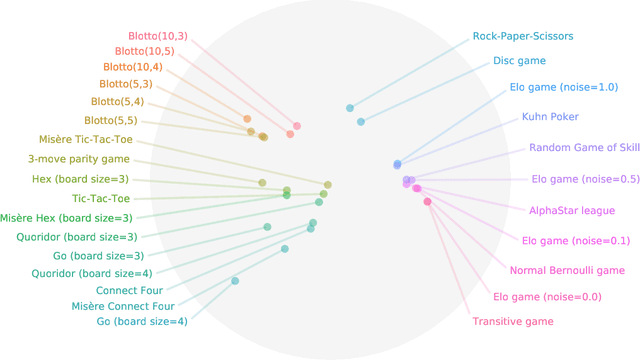
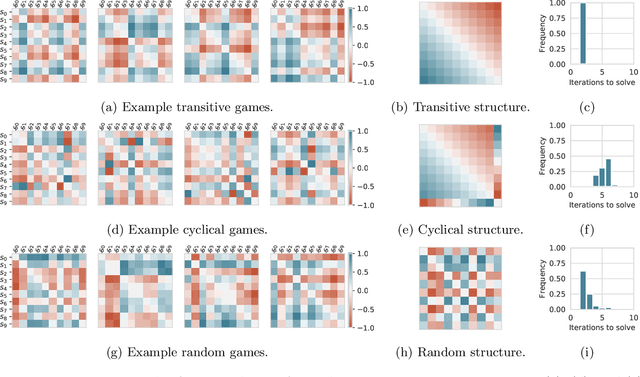
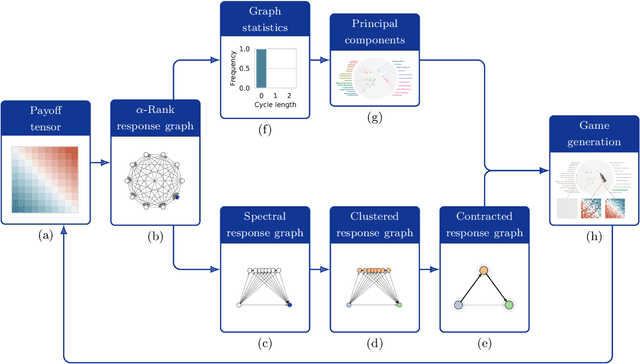

Games are traditionally recognized as one of the key testbeds underlying progress in artificial intelligence (AI), aptly referred to as the "Drosophila of AI". Traditionally, researchers have focused on using games to build strong AI agents that, e.g., achieve human-level performance. This progress, however, also requires a classification of how 'interesting' a game is for an artificial agent. Tackling this latter question not only facilitates an understanding of the characteristics of learnt AI agents in games, but also helps to determine what game an AI should address next as part of its training. Here, we show how network measures applied to so-called response graphs of large-scale games enable the creation of a useful landscape of games, quantifying the relationships between games of widely varying sizes, characteristics, and complexities. We illustrate our findings in various domains, ranging from well-studied canonical games to significantly more complex empirical games capturing the performance of trained AI agents pitted against one another. Our results culminate in a demonstration of how one can leverage this information to automatically generate new and interesting games, including mixtures of empirical games synthesized from real world games.
Neural Replicator Dynamics
Jun 01, 2019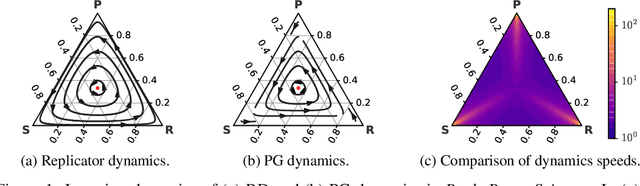

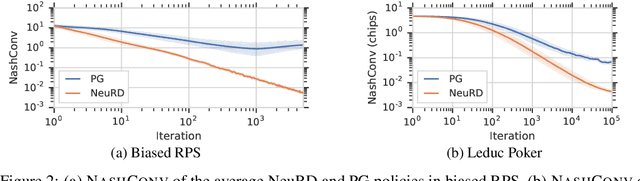
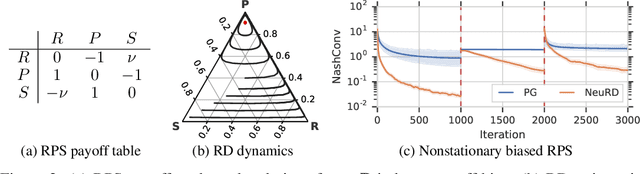
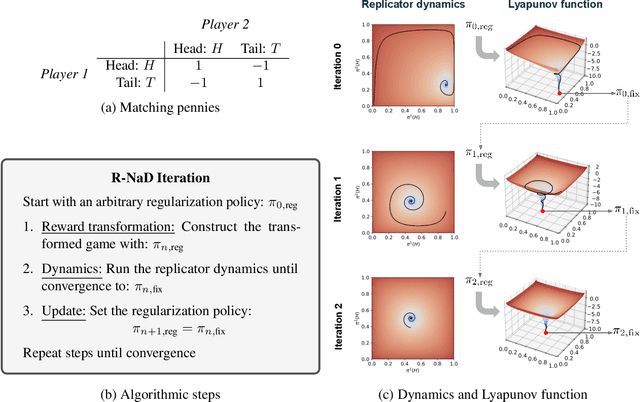
In multiagent learning, agents interact in inherently nonstationary environments due to their concurrent policy updates. It is, therefore, paramount to develop and analyze algorithms that learn effectively despite these nonstationarities. A number of works have successfully conducted this analysis under the lens of evolutionary game theory (EGT), wherein a population of individuals interact and evolve based on biologically-inspired operators. These studies have mainly focused on establishing connections to value-iteration based approaches in stateless or tabular games. We extend this line of inquiry to formally establish links between EGT and policy gradient (PG) methods, which have been extensively applied in single and multiagent learning. We pinpoint weaknesses of the commonly-used softmax PG algorithm in adversarial and nonstationary settings and contrast PG's behavior to that predicted by replicator dynamics (RD), a central model in EGT. We consequently provide theoretical results that establish links between EGT and PG methods, then derive Neural Replicator Dynamics (NeuRD), a parameterized version of RD that constitutes a novel method with several advantages. First, as NeuRD reduces to the well-studied no-regret Hedge algorithm in the tabular setting, it inherits no-regret guarantees that enable convergence to equilibria in games. Second, NeuRD is shown to be more adaptive to nonstationarity, in comparison to PG, when learning in canonical games and imperfect information benchmarks including Poker. Thirdly, modifying any PG-based algorithm to use the NeuRD update rule is straightforward and incurs no added computational costs. Finally, while single-agent learning is not the main focus of the paper, we verify empirically that NeuRD is competitive in these settings with a recent baseline algorithm.
The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning
Jun 19, 2018



In this work we present a new agent architecture, called Reactor, which combines multiple algorithmic and architectural contributions to produce an agent with higher sample-efficiency than Prioritized Dueling DQN (Wang et al., 2016) and Categorical DQN (Bellemare et al., 2017), while giving better run-time performance than A3C (Mnih et al., 2016). Our first contribution is a new policy evaluation algorithm called Distributional Retrace, which brings multi-step off-policy updates to the distributional reinforcement learning setting. The same approach can be used to convert several classes of multi-step policy evaluation algorithms designed for expected value evaluation into distributional ones. Next, we introduce the \b{eta}-leave-one-out policy gradient algorithm which improves the trade-off between variance and bias by using action values as a baseline. Our final algorithmic contribution is a new prioritized replay algorithm for sequences, which exploits the temporal locality of neighboring observations for more efficient replay prioritization. Using the Atari 2600 benchmarks, we show that each of these innovations contribute to both the sample efficiency and final agent performance. Finally, we demonstrate that Reactor reaches state-of-the-art performance after 200 million frames and less than a day of training.
Psychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents
Feb 04, 2018


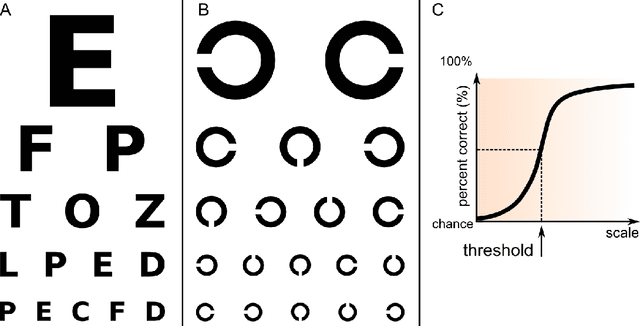
Psychlab is a simulated psychology laboratory inside the first-person 3D game world of DeepMind Lab (Beattie et al. 2016). Psychlab enables implementations of classical laboratory psychological experiments so that they work with both human and artificial agents. Psychlab has a simple and flexible API that enables users to easily create their own tasks. As examples, we are releasing Psychlab implementations of several classical experimental paradigms including visual search, change detection, random dot motion discrimination, and multiple object tracking. We also contribute a study of the visual psychophysics of a specific state-of-the-art deep reinforcement learning agent: UNREAL (Jaderberg et al. 2016). This study leads to the surprising conclusion that UNREAL learns more quickly about larger target stimuli than it does about smaller stimuli. In turn, this insight motivates a specific improvement in the form of a simple model of foveal vision that turns out to significantly boost UNREAL's performance, both on Psychlab tasks, and on standard DeepMind Lab tasks. By open-sourcing Psychlab we hope to facilitate a range of future such studies that simultaneously advance deep reinforcement learning and improve its links with cognitive science.
Deep Q-learning from Demonstrations
Nov 22, 2017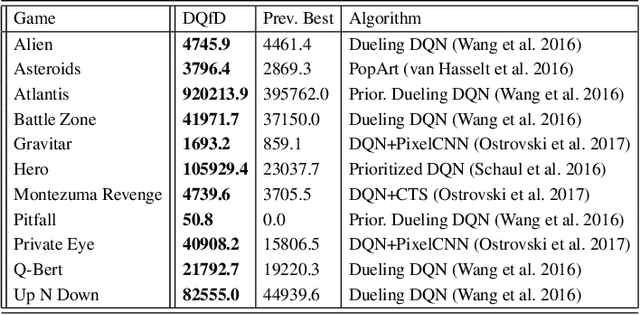
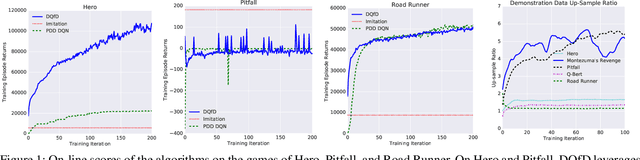
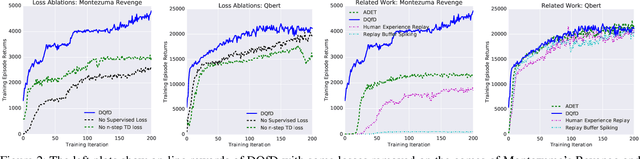
Deep reinforcement learning (RL) has achieved several high profile successes in difficult decision-making problems. However, these algorithms typically require a huge amount of data before they reach reasonable performance. In fact, their performance during learning can be extremely poor. This may be acceptable for a simulator, but it severely limits the applicability of deep RL to many real-world tasks, where the agent must learn in the real environment. In this paper we study a setting where the agent may access data from previous control of the system. We present an algorithm, Deep Q-learning from Demonstrations (DQfD), that leverages small sets of demonstration data to massively accelerate the learning process even from relatively small amounts of demonstration data and is able to automatically assess the necessary ratio of demonstration data while learning thanks to a prioritized replay mechanism. DQfD works by combining temporal difference updates with supervised classification of the demonstrator's actions. We show that DQfD has better initial performance than Prioritized Dueling Double Deep Q-Networks (PDD DQN) as it starts with better scores on the first million steps on 41 of 42 games and on average it takes PDD DQN 83 million steps to catch up to DQfD's performance. DQfD learns to out-perform the best demonstration given in 14 of 42 games. In addition, DQfD leverages human demonstrations to achieve state-of-the-art results for 11 games. Finally, we show that DQfD performs better than three related algorithms for incorporating demonstration data into DQN.
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning
Nov 07, 2017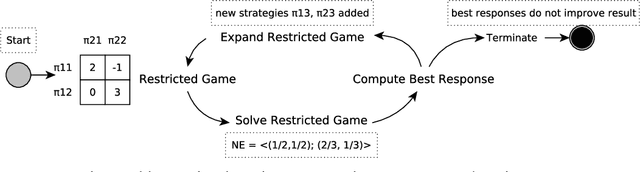
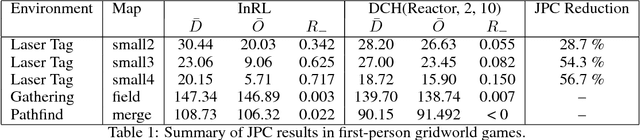
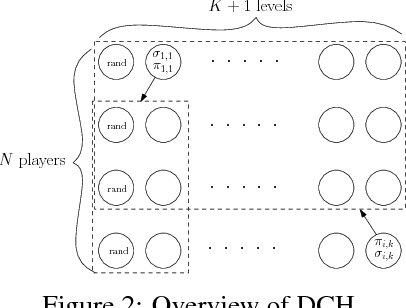
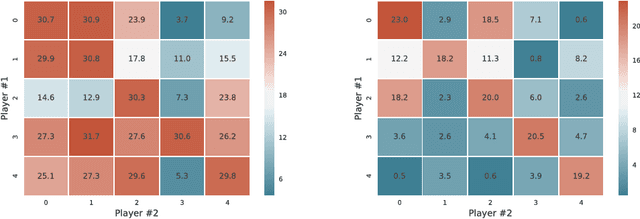
To achieve general intelligence, agents must learn how to interact with others in a shared environment: this is the challenge of multiagent reinforcement learning (MARL). The simplest form is independent reinforcement learning (InRL), where each agent treats its experience as part of its (non-stationary) environment. In this paper, we first observe that policies learned using InRL can overfit to the other agents' policies during training, failing to sufficiently generalize during execution. We introduce a new metric, joint-policy correlation, to quantify this effect. We describe an algorithm for general MARL, based on approximate best responses to mixtures of policies generated using deep reinforcement learning, and empirical game-theoretic analysis to compute meta-strategies for policy selection. The algorithm generalizes previous ones such as InRL, iterated best response, double oracle, and fictitious play. Then, we present a scalable implementation which reduces the memory requirement using decoupled meta-solvers. Finally, we demonstrate the generality of the resulting policies in two partially observable settings: gridworld coordination games and poker.
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Jun 16, 2017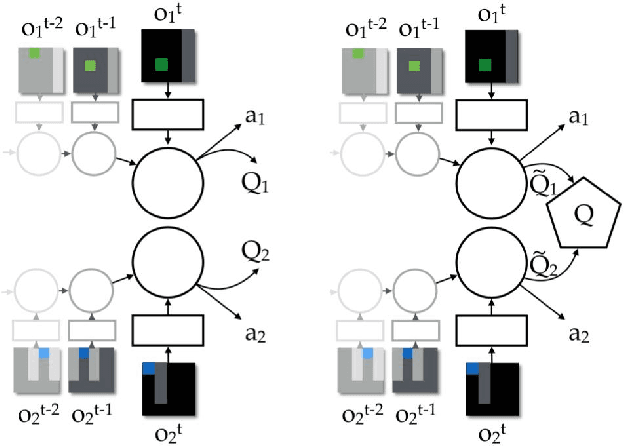
We study the problem of cooperative multi-agent reinforcement learning with a single joint reward signal. This class of learning problems is difficult because of the often large combined action and observation spaces. In the fully centralized and decentralized approaches, we find the problem of spurious rewards and a phenomenon we call the "lazy agent" problem, which arises due to partial observability. We address these problems by training individual agents with a novel value decomposition network architecture, which learns to decompose the team value function into agent-wise value functions. We perform an experimental evaluation across a range of partially-observable multi-agent domains and show that learning such value-decompositions leads to superior results, in particular when combined with weight sharing, role information and information channels.