 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLATTER: Comprehensive Entailment Reasoning for Hallucination Detection
Jun 05, 2025A common approach to hallucination detection casts it as a natural language inference (NLI) task, often using LLMs to classify whether the generated text is entailed by corresponding reference texts. Since entailment classification is a complex reasoning task, one would expect that LLMs could benefit from generating an explicit reasoning process, as in CoT reasoning or the explicit ``thinking'' of recent reasoning models. In this work, we propose that guiding such models to perform a systematic and comprehensive reasoning process -- one that both decomposes the text into smaller facts and also finds evidence in the source for each fact -- allows models to execute much finer-grained and accurate entailment decisions, leading to increased performance. To that end, we define a 3-step reasoning process, consisting of (i) claim decomposition, (ii) sub-claim attribution and entailment classification, and (iii) aggregated classification, showing that such guided reasoning indeed yields improved hallucination detection. Following this reasoning framework, we introduce an analysis scheme, consisting of several metrics that measure the quality of the intermediate reasoning steps, which provided additional empirical evidence for the improved quality of our guided reasoning scheme.
Explain Yourself, Briefly! Self-Explaining Neural Networks with Concise Sufficient Reasons
Feb 05, 2025



Minimal sufficient reasons represent a prevalent form of explanation - the smallest subset of input features which, when held constant at their corresponding values, ensure that the prediction remains unchanged. Previous post-hoc methods attempt to obtain such explanations but face two main limitations: (1) Obtaining these subsets poses a computational challenge, leading most scalable methods to converge towards suboptimal, less meaningful subsets; (2) These methods heavily rely on sampling out-of-distribution input assignments, potentially resulting in counterintuitive behaviors. To tackle these limitations, we propose in this work a self-supervised training approach, which we term *sufficient subset training* (SST). Using SST, we train models to generate concise sufficient reasons for their predictions as an integral part of their output. Our results indicate that our framework produces succinct and faithful subsets substantially more efficiently than competing post-hoc methods, while maintaining comparable predictive performance.
Semantic uncertainty guides the extension of conventions to new referents
May 11, 2023



A long tradition of studies in psycholinguistics has examined the formation and generalization of ad hoc conventions in reference games, showing how newly acquired conventions for a given target transfer to new referential contexts. However, another axis of generalization remains understudied: how do conventions formed for one target transfer to completely distinct targets, when specific lexical choices are unlikely to repeat? This paper presents two dyadic studies (N = 240) that address this axis of generalization, focusing on the role of nameability -- the a priori likelihood that two individuals will share the same label. We leverage the recently-released KiloGram dataset, a collection of abstract tangram images that is orders of magnitude larger than previously available, exhibiting high diversity of properties like nameability. Our first study asks how nameability shapes convention formation, while the second asks how new conventions generalize to entirely new targets of reference. Our results raise new questions about how ad hoc conventions extend beyond target-specific re-use of specific lexical choices.
QASem Parsing: Text-to-text Modeling of QA-based Semantics
May 23, 2022
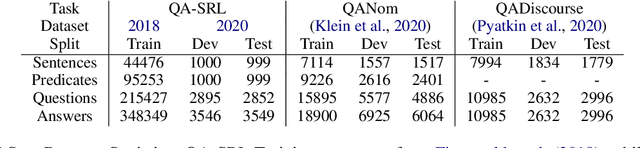
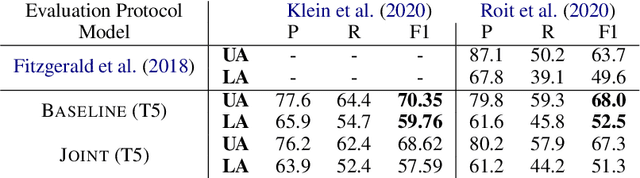
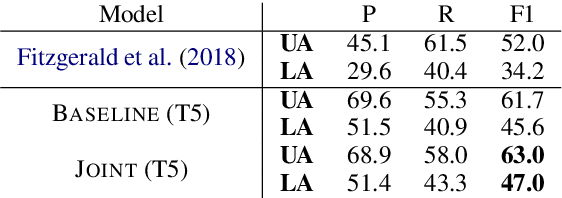
Several recent works have suggested to represent semantic relations with questions and answers, decomposing textual information into separate interrogative natural language statements. In this paper, we consider three QA-based semantic tasks - namely, QA-SRL, QANom and QADiscourse, each targeting a certain type of predication - and propose to regard them as jointly providing a comprehensive representation of textual information. To promote this goal, we investigate how to best utilize the power of sequence-to-sequence (seq2seq) pre-trained language models, within the unique setup of semi-structured outputs, consisting of an unordered set of question-answer pairs. We examine different input and output linearization strategies, and assess the effect of multitask learning and of simple data augmentation techniques in the setting of imbalanced training data. Consequently, we release the first unified QASem parsing tool, practical for downstream applications who can benefit from an explicit, QA-based account of information units in a text.