 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022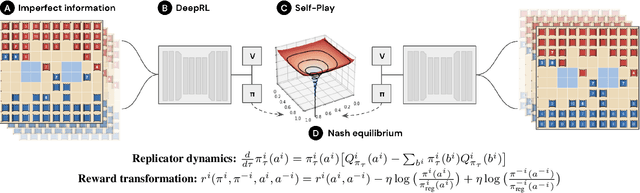
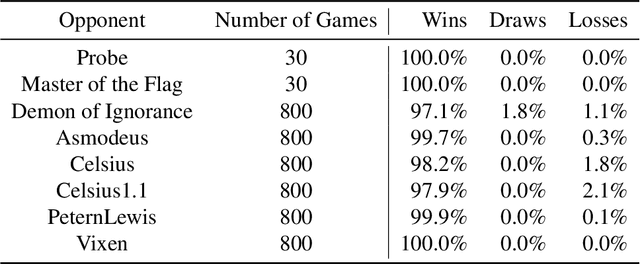
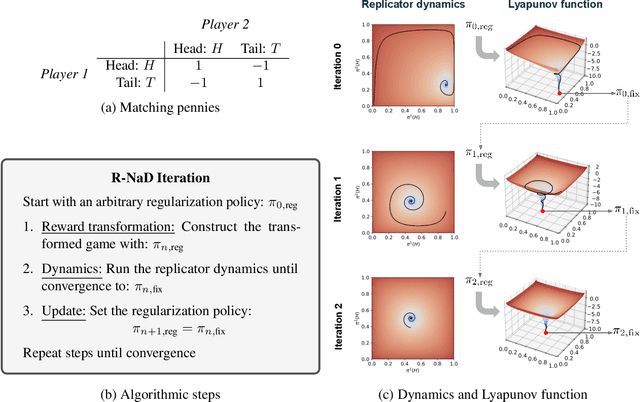

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
A Generalist Agent
May 19, 2022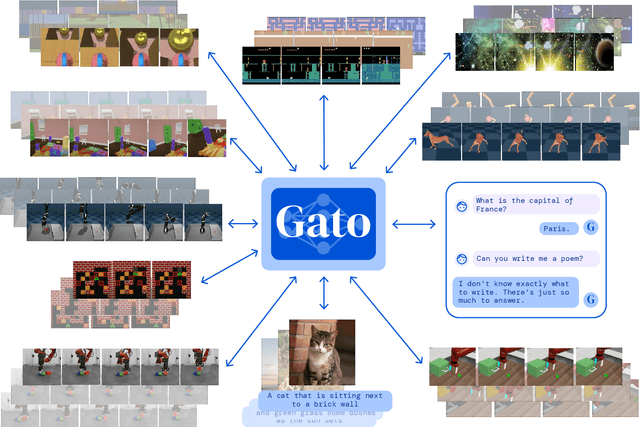
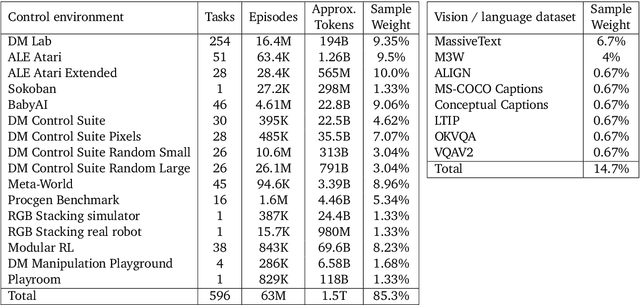
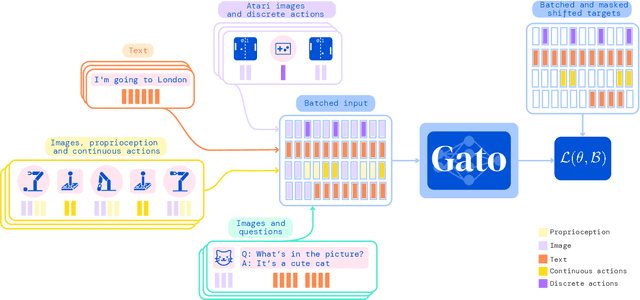

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Human-Agent Cooperation in Bridge Bidding
Nov 28, 2020
We introduce a human-compatible reinforcement-learning approach to a cooperative game, making use of a third-party hand-coded human-compatible bot to generate initial training data and to perform initial evaluation. Our learning approach consists of imitation learning, search, and policy iteration. Our trained agents achieve a new state-of-the-art for bridge bidding in three settings: an agent playing in partnership with a copy of itself; an agent partnering a pre-existing bot; and an agent partnering a human player.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020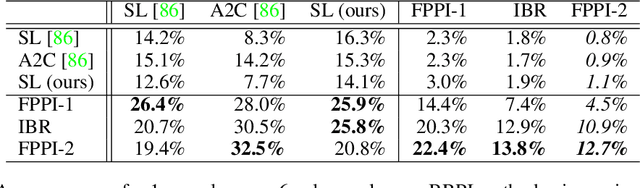
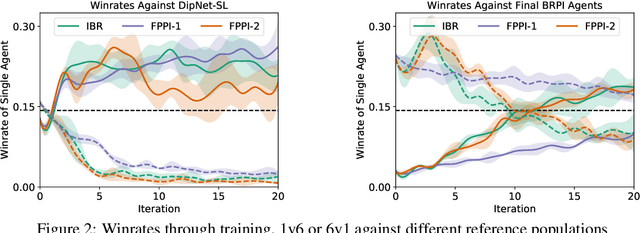
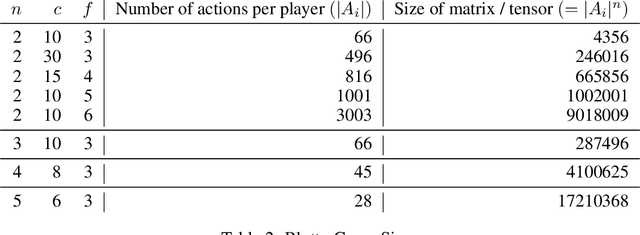
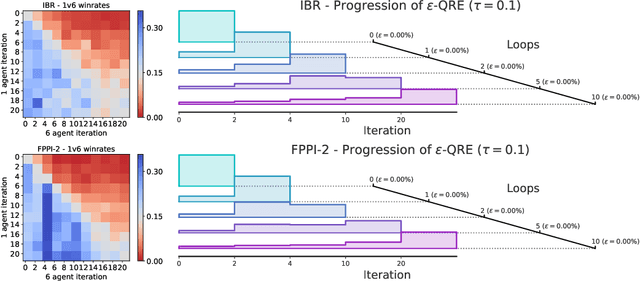
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.
Learning to Resolve Alliance Dilemmas in Many-Player Zero-Sum Games
Feb 27, 2020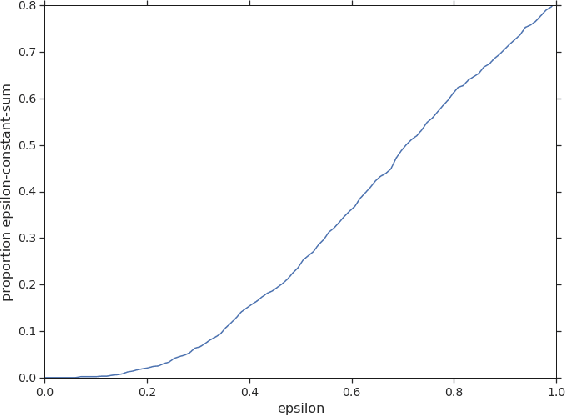
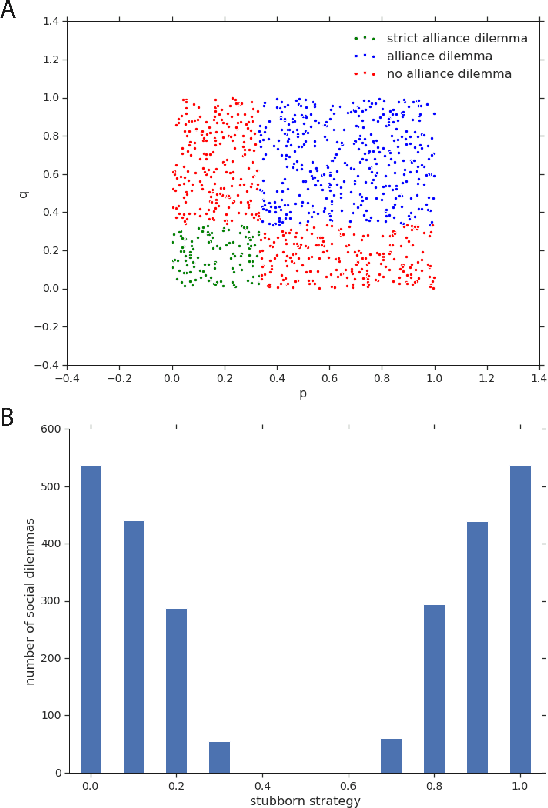
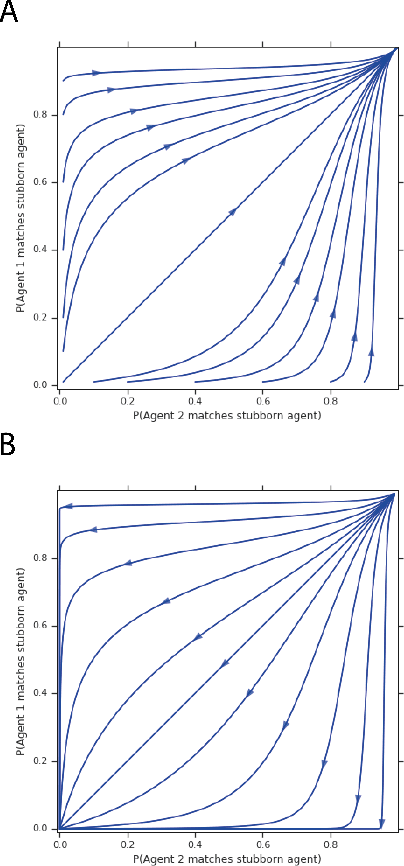
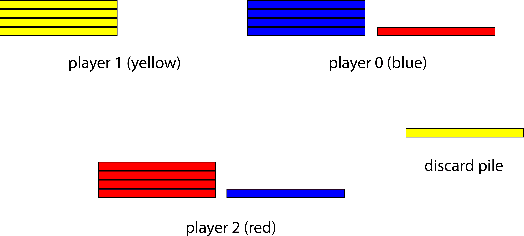
Zero-sum games have long guided artificial intelligence research, since they possess both a rich strategy space of best-responses and a clear evaluation metric. What's more, competition is a vital mechanism in many real-world multi-agent systems capable of generating intelligent innovations: Darwinian evolution, the market economy and the AlphaZero algorithm, to name a few. In two-player zero-sum games, the challenge is usually viewed as finding Nash equilibrium strategies, safeguarding against exploitation regardless of the opponent. While this captures the intricacies of chess or Go, it avoids the notion of cooperation with co-players, a hallmark of the major transitions leading from unicellular organisms to human civilization. Beyond two players, alliance formation often confers an advantage; however this requires trust, namely the promise of mutual cooperation in the face of incentives to defect. Successful play therefore requires adaptation to co-players rather than the pursuit of non-exploitability. Here we argue that a systematic study of many-player zero-sum games is a crucial element of artificial intelligence research. Using symmetric zero-sum matrix games, we demonstrate formally that alliance formation may be seen as a social dilemma, and empirically that na\"ive multi-agent reinforcement learning therefore fails to form alliances. We introduce a toy model of economic competition, and show how reinforcement learning may be augmented with a peer-to-peer contract mechanism to discover and enforce alliances. Finally, we generalize our agent model to incorporate temporally-extended contracts, presenting opportunities for further work.
Biases for Emergent Communication in Multi-agent Reinforcement Learning
Dec 11, 2019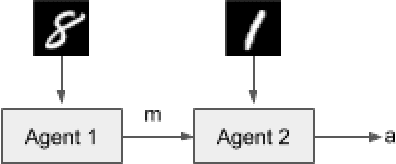
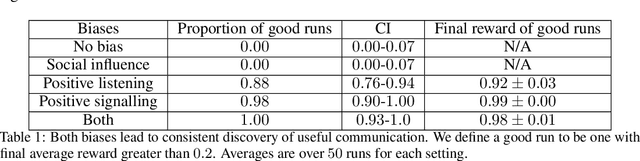
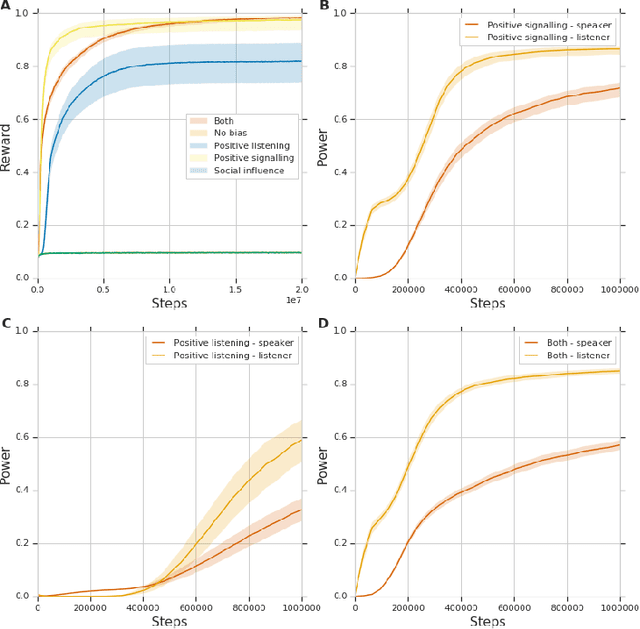
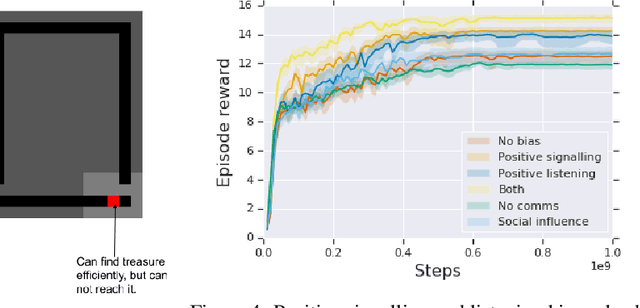
We study the problem of emergent communication, in which language arises because speakers and listeners must communicate information in order to solve tasks. In temporally extended reinforcement learning domains, it has proved hard to learn such communication without centralized training of agents, due in part to a difficult joint exploration problem. We introduce inductive biases for positive signalling and positive listening, which ease this problem. In a simple one-step environment, we demonstrate how these biases ease the learning problem. We also apply our methods to a more extended environment, showing that agents with these inductive biases achieve better performance, and analyse the resulting communication protocols.
Learning Reciprocity in Complex Sequential Social Dilemmas
Mar 19, 2019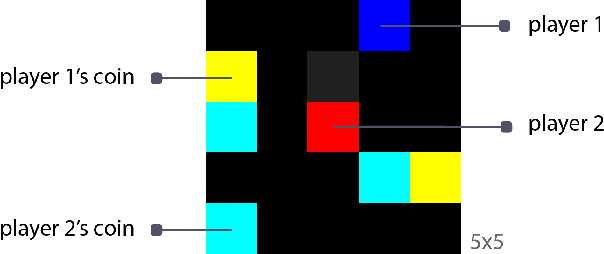
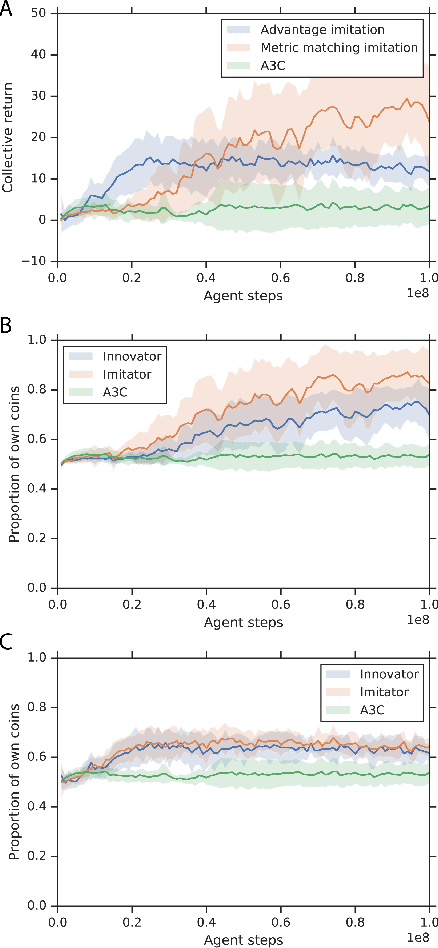
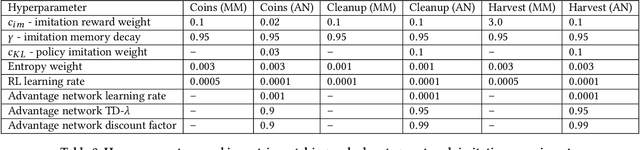
Reciprocity is an important feature of human social interaction and underpins our cooperative nature. What is more, simple forms of reciprocity have proved remarkably resilient in matrix game social dilemmas. Most famously, the tit-for-tat strategy performs very well in tournaments of Prisoner's Dilemma. Unfortunately this strategy is not readily applicable to the real world, in which options to cooperate or defect are temporally and spatially extended. Here, we present a general online reinforcement learning algorithm that displays reciprocal behavior towards its co-players. We show that it can induce pro-social outcomes for the wider group when learning alongside selfish agents, both in a $2$-player Markov game, and in $5$-player intertemporal social dilemmas. We analyse the resulting policies to show that the reciprocating agents are strongly influenced by their co-players' behavior.
An investigation of model-free planning
Jan 11, 2019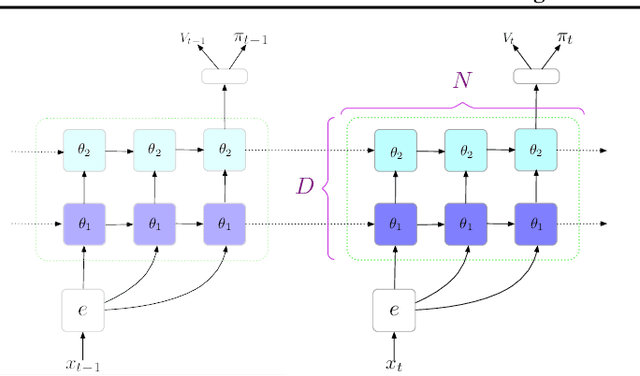
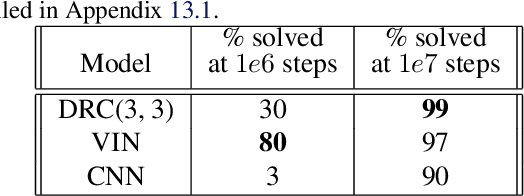
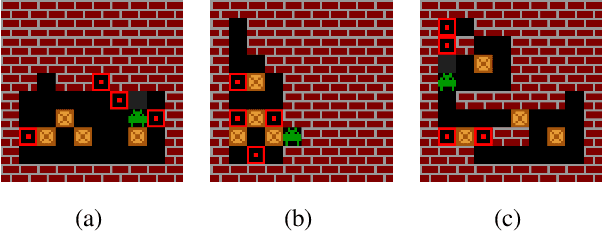
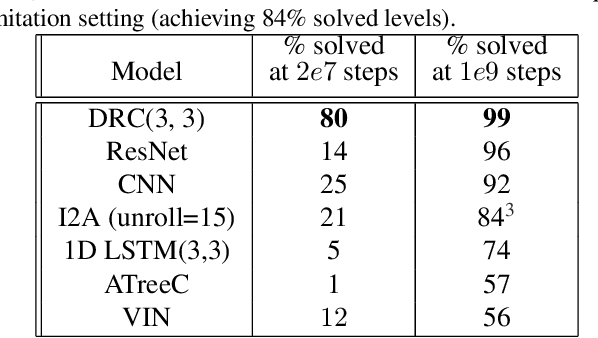
The field of reinforcement learning (RL) is facing increasingly challenging domains with combinatorial complexity. For an RL agent to address these challenges, it is essential that it can plan effectively. Prior work has typically utilized an explicit model of the environment, combined with a specific planning algorithm (such as tree search). More recently, a new family of methods have been proposed that learn how to plan, by providing the structure for planning via an inductive bias in the function approximator (such as a tree structured neural network), trained end-to-end by a model-free RL algorithm. In this paper, we go even further, and demonstrate empirically that an entirely model-free approach, without special structure beyond standard neural network components such as convolutional networks and LSTMs, can learn to exhibit many of the characteristics typically associated with a model-based planner. We measure our agent's effectiveness at planning in terms of its ability to generalize across a combinatorial and irreversible state space, its data efficiency, and its ability to utilize additional thinking time. We find that our agent has many of the characteristics that one might expect to find in a planning algorithm. Furthermore, it exceeds the state-of-the-art in challenging combinatorial domains such as Sokoban and outperforms other model-free approaches that utilize strong inductive biases toward planning.