 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DataComp: In search of the next generation of multimodal datasets
May 03, 2023
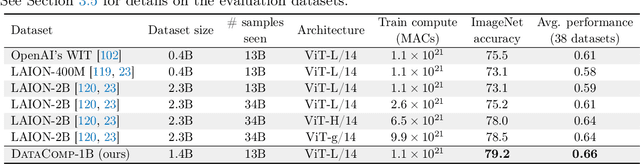
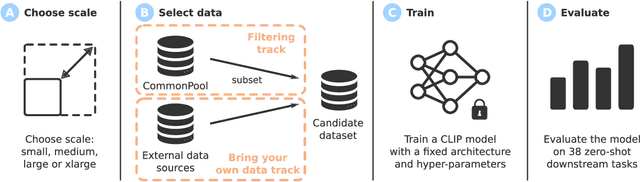


Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
MagicFusion: Boosting Text-to-Image Generation Performance by Fusing Diffusion Models
Mar 25, 2023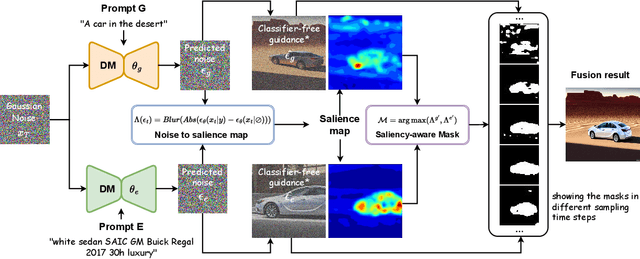



The advent of open-source AI communities has produced a cornucopia of powerful text-guided diffusion models that are trained on various datasets. While few explorations have been conducted on ensembling such models to combine their strengths. In this work, we propose a simple yet effective method called Saliency-aware Noise Blending (SNB) that can empower the fused text-guided diffusion models to achieve more controllable generation. Specifically, we experimentally find that the responses of classifier-free guidance are highly related to the saliency of generated images. Thus we propose to trust different models in their areas of expertise by blending the predicted noises of two diffusion models in a saliency-aware manner. SNB is training-free and can be completed within a DDIM sampling process. Additionally, it can automatically align the semantics of two noise spaces without requiring additional annotations such as masks. Extensive experiments show the impressive effectiveness of SNB in various applications. Project page is available at https://magicfusion.github.io/.
LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images
Apr 16, 2023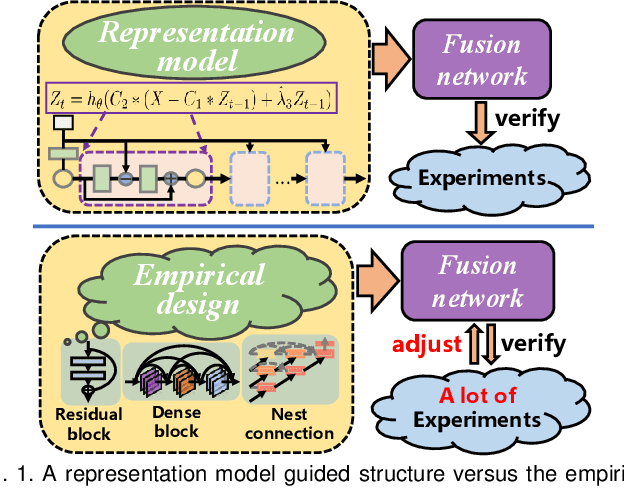
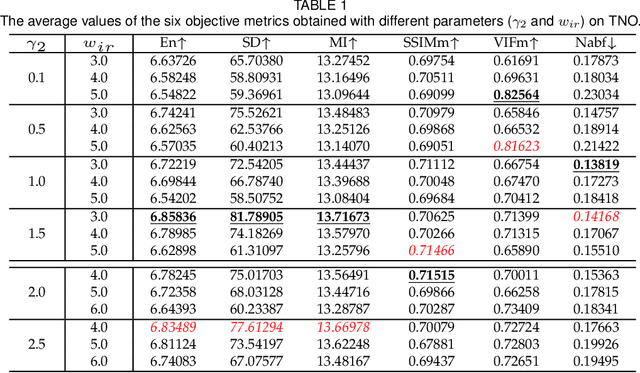

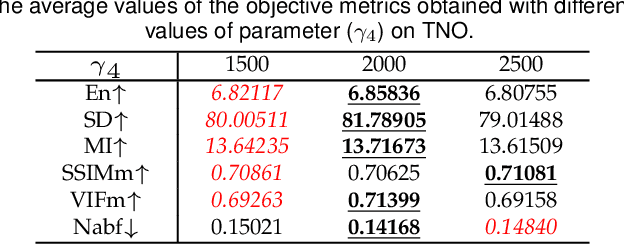
Deep learning based fusion methods have been achieving promising performance in image fusion tasks. This is attributed to the network architecture that plays a very important role in the fusion process. However, in general, it is hard to specify a good fusion architecture, and consequently, the design of fusion networks is still a black art, rather than science. To address this problem, we formulate the fusion task mathematically, and establish a connection between its optimal solution and the network architecture that can implement it. This approach leads to a novel method proposed in the paper of constructing a lightweight fusion network. It avoids the time-consuming empirical network design by a trial-and-test strategy. In particular we adopt a learnable representation approach to the fusion task, in which the construction of the fusion network architecture is guided by the optimisation algorithm producing the learnable model. The low-rank representation (LRR) objective is the foundation of our learnable model. The matrix multiplications, which are at the heart of the solution are transformed into convolutional operations, and the iterative process of optimisation is replaced by a special feed-forward network. Based on this novel network architecture, an end-to-end lightweight fusion network is constructed to fuse infrared and visible light images. Its successful training is facilitated by a detail-to-semantic information loss function proposed to preserve the image details and to enhance the salient features of the source images. Our experiments show that the proposed fusion network exhibits better fusion performance than the state-of-the-art fusion methods on public datasets. Interestingly, our network requires a fewer training parameters than other existing methods. The codes are available at https://github.com/hli1221/imagefusion-LRRNet
DLGSANet: Lightweight Dynamic Local and Global Self-Attention Networks for Image Super-Resolution
Jan 05, 2023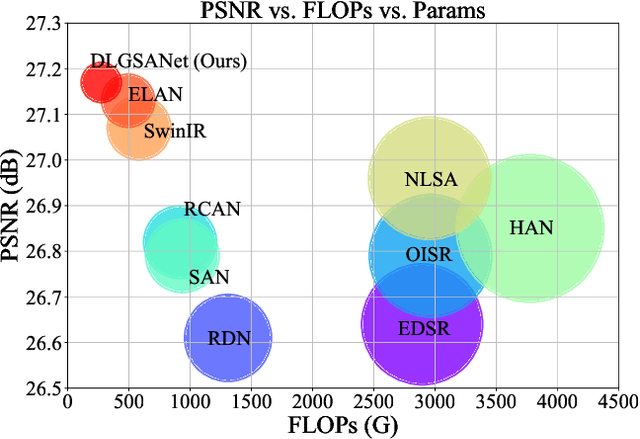
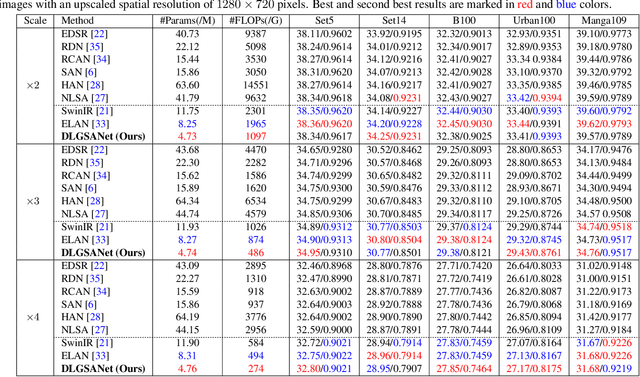
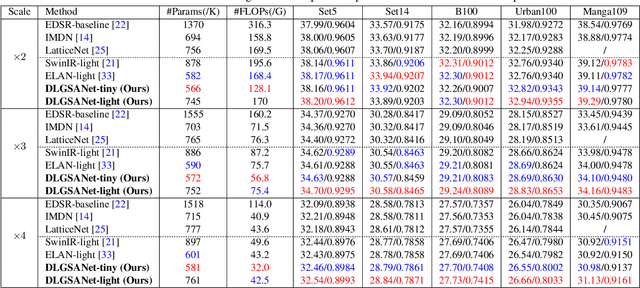
We propose an effective lightweight dynamic local and global self-attention network (DLGSANet) to solve image super-resolution. Our method explores the properties of Transformers while having low computational costs. Motivated by the network designs of Transformers, we develop a simple yet effective multi-head dynamic local self-attention (MHDLSA) module to extract local features efficiently. In addition, we note that existing Transformers usually explore all similarities of the tokens between the queries and keys for the feature aggregation. However, not all the tokens from the queries are relevant to those in keys, using all the similarities does not effectively facilitate the high-resolution image reconstruction. To overcome this problem, we develop a sparse global self-attention (SparseGSA) module to select the most useful similarity values so that the most useful global features can be better utilized for the high-resolution image reconstruction. We develop a hybrid dynamic-Transformer block(HDTB) that integrates the MHDLSA and SparseGSA for both local and global feature exploration. To ease the network training, we formulate the HDTBs into a residual hybrid dynamic-Transformer group (RHDTG). By embedding the RHDTGs into an end-to-end trainable network, we show that our proposed method has fewer network parameters and lower computational costs while achieving competitive performance against state-of-the-art ones in terms of accuracy. More information is available at https://neonleexiang.github.io/DLGSANet/
Fully Sparse Fusion for 3D Object Detection
Apr 25, 2023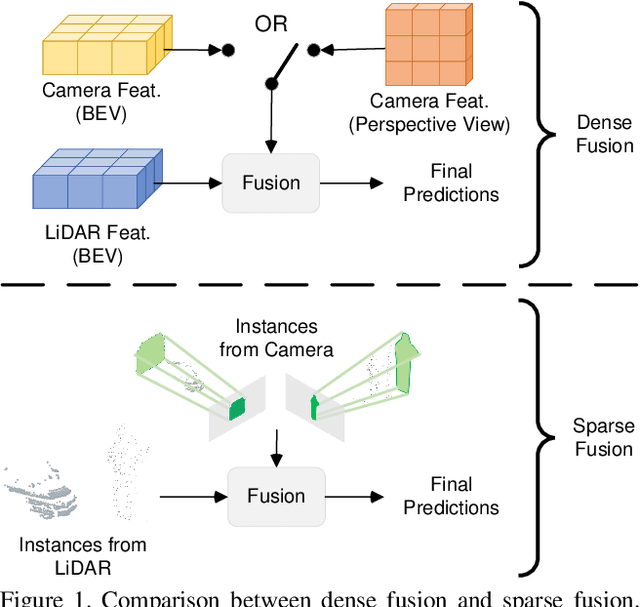
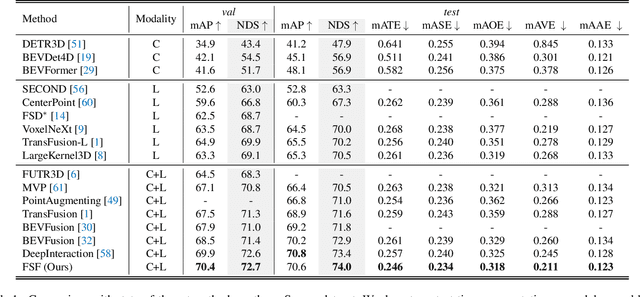
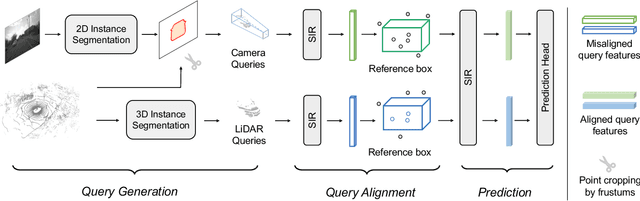

Currently prevalent multimodal 3D detection methods are built upon LiDAR-based detectors that usually use dense Bird's-Eye-View (BEV) feature maps. However, the cost of such BEV feature maps is quadratic to the detection range, making it not suitable for long-range detection. Fully sparse architecture is gaining attention as they are highly efficient in long-range perception. In this paper, we study how to effectively leverage image modality in the emerging fully sparse architecture. Particularly, utilizing instance queries, our framework integrates the well-studied 2D instance segmentation into the LiDAR side, which is parallel to the 3D instance segmentation part in the fully sparse detector. This design achieves a uniform query-based fusion framework in both the 2D and 3D sides while maintaining the fully sparse characteristic. Extensive experiments showcase state-of-the-art results on the widely used nuScenes dataset and the long-range Argoverse 2 dataset. Notably, the inference speed of the proposed method under the long-range LiDAR perception setting is 2.7 $\times$ faster than that of other state-of-the-art multimodal 3D detection methods. Code will be released at \url{https://github.com/BraveGroup/FullySparseFusion}.
Context-Aware Classification of Legal Document Pages
Apr 25, 2023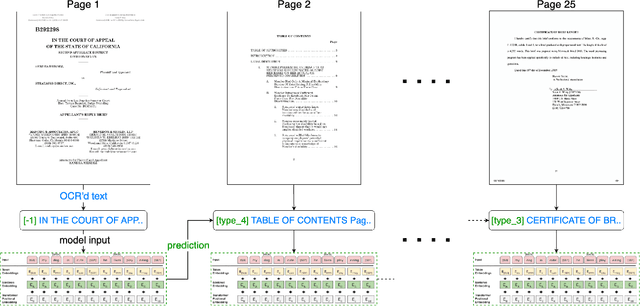
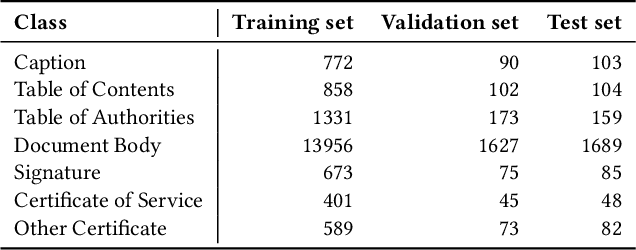


For many business applications that require the processing, indexing, and retrieval of professional documents such as legal briefs (in PDF format etc.), it is often essential to classify the pages of any given document into their corresponding types beforehand. Most existing studies in the field of document image classification either focus on single-page documents or treat multiple pages in a document independently. Although in recent years a few techniques have been proposed to exploit the context information from neighboring pages to enhance document page classification, they typically cannot be utilized with large pre-trained language models due to the constraint on input length. In this paper, we present a simple but effective approach that overcomes the above limitation. Specifically, we enhance the input with extra tokens carrying sequential information about previous pages - introducing recurrence - which enables the usage of pre-trained Transformer models like BERT for context-aware page classification. Our experiments conducted on two legal datasets in English and Portuguese respectively show that the proposed approach can significantly improve the performance of document page classification compared to the non-recurrent setup as well as the other context-aware baselines.
RobCaps: Evaluating the Robustness of Capsule Networks against Affine Transformations and Adversarial Attacks
Apr 25, 2023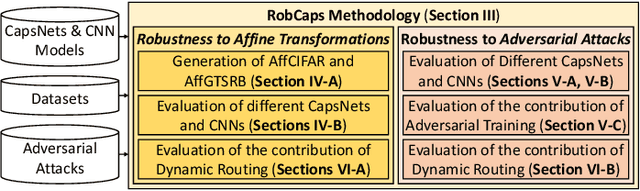

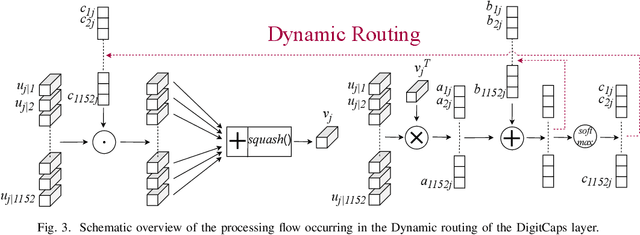
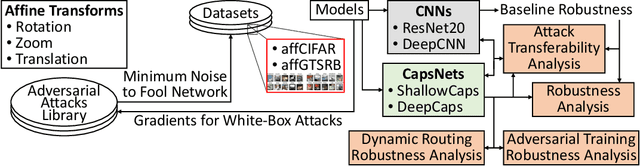
Capsule Networks (CapsNets) are able to hierarchically preserve the pose relationships between multiple objects for image classification tasks. Other than achieving high accuracy, another relevant factor in deploying CapsNets in safety-critical applications is the robustness against input transformations and malicious adversarial attacks. In this paper, we systematically analyze and evaluate different factors affecting the robustness of CapsNets, compared to traditional Convolutional Neural Networks (CNNs). Towards a comprehensive comparison, we test two CapsNet models and two CNN models on the MNIST, GTSRB, and CIFAR10 datasets, as well as on the affine-transformed versions of such datasets. With a thorough analysis, we show which properties of these architectures better contribute to increasing the robustness and their limitations. Overall, CapsNets achieve better robustness against adversarial examples and affine transformations, compared to a traditional CNN with a similar number of parameters. Similar conclusions have been derived for deeper versions of CapsNets and CNNs. Moreover, our results unleash a key finding that the dynamic routing does not contribute much to improving the CapsNets' robustness. Indeed, the main generalization contribution is due to the hierarchical feature learning through capsules.
iMixer: hierarchical Hopfield network implies an invertible, implicit and iterative MLP-Mixer
Apr 25, 2023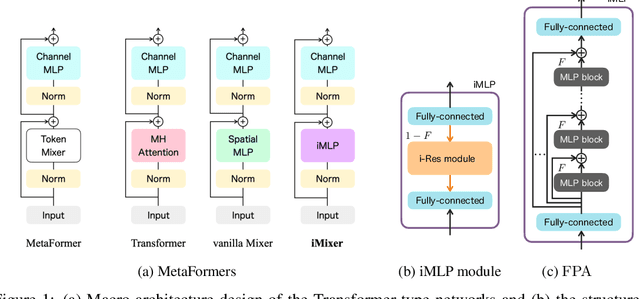

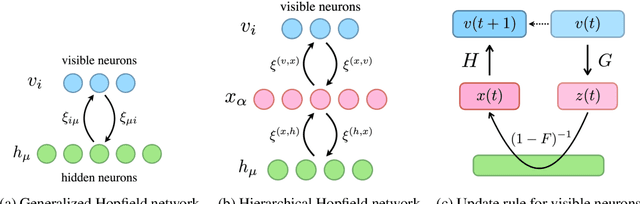
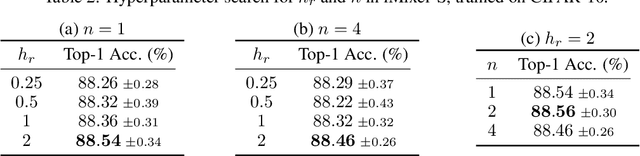
In the last few years, the success of Transformers in computer vision has stimulated the discovery of many alternative models that compete with Transformers, such as the MLP-Mixer. Despite their weak induced bias, these models have achieved performance comparable to well-studied convolutional neural networks. Recent studies on modern Hopfield networks suggest the correspondence between certain energy-based associative memory models and Transformers or MLP-Mixer, and shed some light on the theoretical background of the Transformer-type architectures design. In this paper we generalize the correspondence to the recently introduced hierarchical Hopfield network, and find iMixer, a novel generalization of MLP-Mixer model. Unlike ordinary feedforward neural networks, iMixer involves MLP layers that propagate forward from the output side to the input side. We characterize the module as an example of invertible, implicit, and iterative mixing module. We evaluate the model performance with various datasets on image classification tasks, and find that iMixer reasonably achieves the improvement compared to the baseline vanilla MLP-Mixer. The results imply that the correspondence between the Hopfield networks and the Mixer models serves as a principle for understanding a broader class of Transformer-like architecture designs.
On the Use of Singular Value Decomposition as a Clutter Filter for Ultrasound Flow Imaging
Apr 25, 2023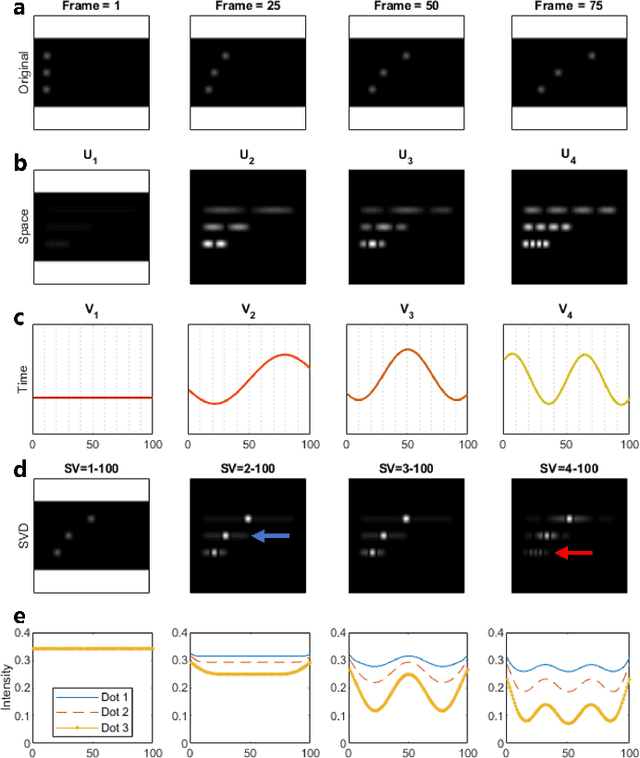
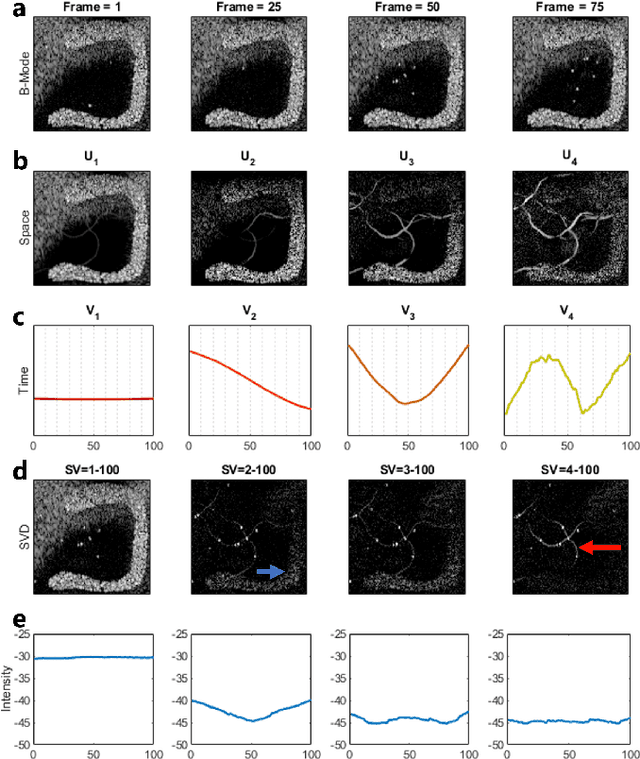
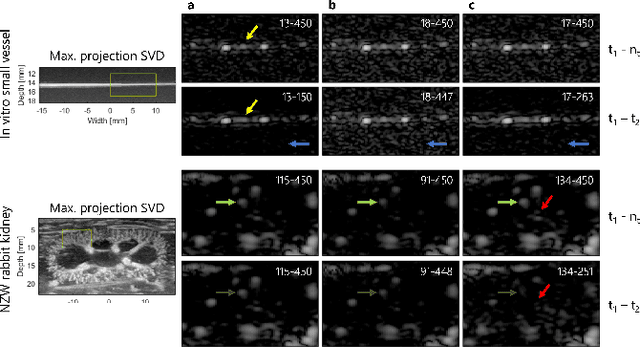
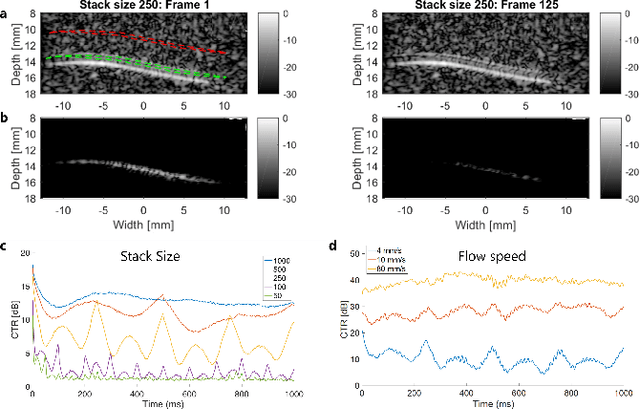
Filtering based on Singular Value Decomposition (SVD) provides substantial separation of clutter, flow and noise in high frame rate ultrasound flow imaging. The use of SVD as a clutter filter has greatly improved techniques such as vector flow imaging, functional ultrasound and super-resolution ultrasound localization microscopy. The removal of clutter and noise relies on the assumption that tissue, flow and noise are each represented by different subsets of singular values, so that their signals are uncorrelated and lay on orthogonal sub-spaces. This assumption fails in the presence of tissue motion, for near-wall or microvascular flow, and can be influenced by an incorrect choice of singular value thresholds. Consequently, separation of flow, clutter and noise is imperfect, which can lead to image artefacts not present in the original data. Temporal and spatial fluctuation in intensity are the commonest artefacts, which vary in appearance and strengths. Ghosting and splitting artefacts are observed in the microvasculature where the flow signal is sparsely distributed. Singular value threshold selection, tissue motion, frame rate, flow signal amplitude and acquisition length affect the prevalence of these artefacts. Understanding what causes artefacts due to SVD clutter and noise removal is necessary for their interpretation.
Text-guided Eyeglasses Manipulation with Spatial Constraints
Apr 25, 2023



Virtual try-on of eyeglasses involves placing eyeglasses of different shapes and styles onto a face image without physically trying them on. While existing methods have shown impressive results, the variety of eyeglasses styles is limited and the interactions are not always intuitive or efficient. To address these limitations, we propose a Text-guided Eyeglasses Manipulation method that allows for control of the eyeglasses shape and style based on a binary mask and text, respectively. Specifically, we introduce a mask encoder to extract mask conditions and a modulation module that enables simultaneous injection of text and mask conditions. This design allows for fine-grained control of the eyeglasses' appearance based on both textual descriptions and spatial constraints. Our approach includes a disentangled mapper and a decoupling strategy that preserves irrelevant areas, resulting in better local editing. We employ a two-stage training scheme to handle the different convergence speeds of the various modality conditions, successfully controlling both the shape and style of eyeglasses. Extensive comparison experiments and ablation analyses demonstrate the effectiveness of our approach in achieving diverse eyeglasses styles while preserving irrelevant areas.