 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024



Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
Inverse Problems Leveraging Pre-trained Contrastive Representations
Oct 26, 2021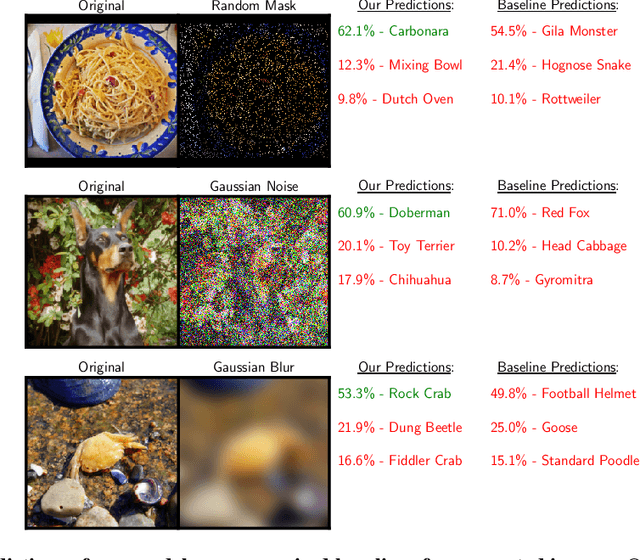
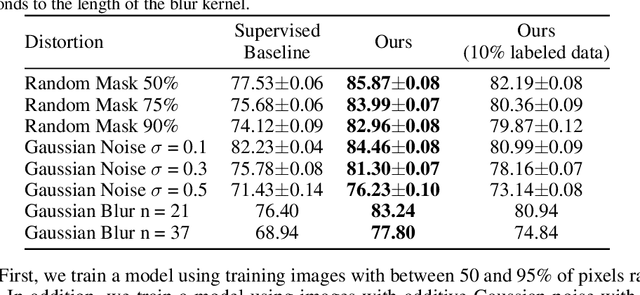
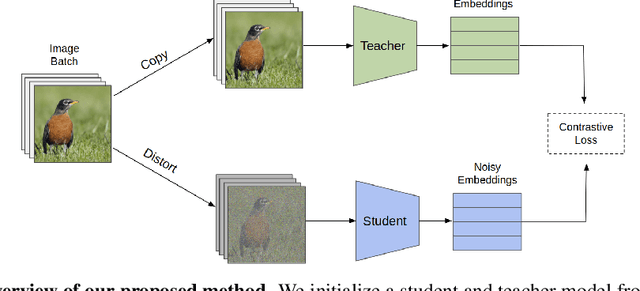
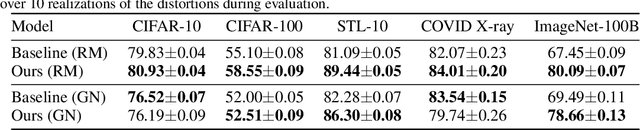
We study a new family of inverse problems for recovering representations of corrupted data. We assume access to a pre-trained representation learning network R(x) that operates on clean images, like CLIP. The problem is to recover the representation of an image R(x), if we are only given a corrupted version A(x), for some known forward operator A. We propose a supervised inversion method that uses a contrastive objective to obtain excellent representations for highly corrupted images. Using a linear probe on our robust representations, we achieve a higher accuracy than end-to-end supervised baselines when classifying images with various types of distortions, including blurring, additive noise, and random pixel masking. We evaluate on a subset of ImageNet and observe that our method is robust to varying levels of distortion. Our method outperforms end-to-end baselines even with a fraction of the labeled data in a wide range of forward operators.
Tropical Polynomial Division and Neural Networks
Nov 29, 2019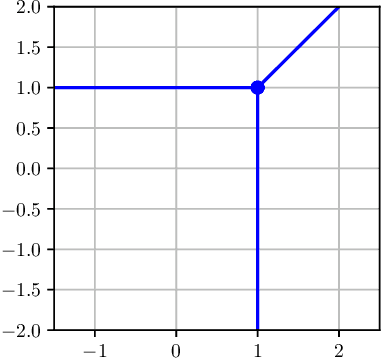
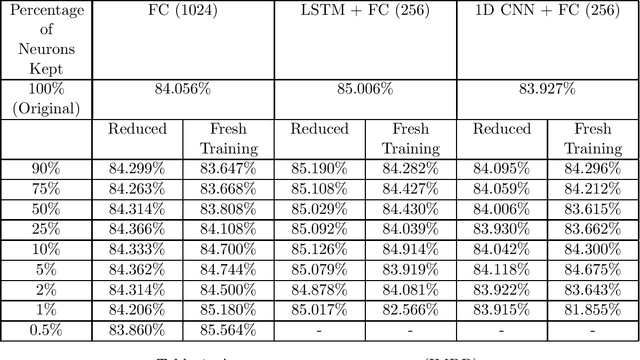
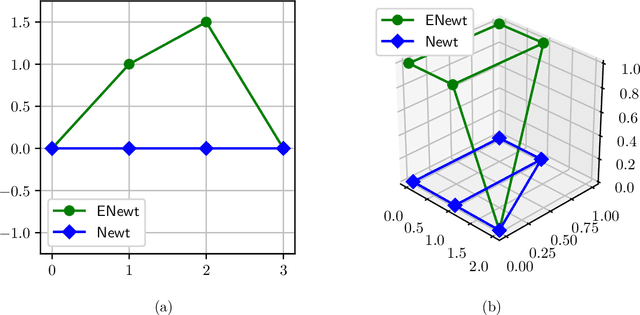
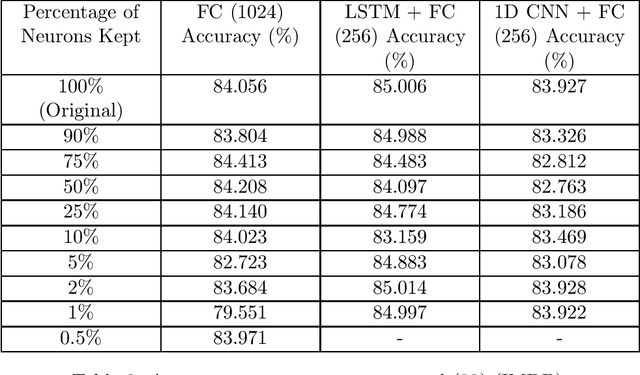
In this work, we examine the process of Tropical Polynomial Division, a geometric method which seeks to emulate the division of regular polynomials, when applied to those of the max-plus semiring. This is done via the approximation of the Newton Polytope of the dividend polynomial by that of the divisor. This process is afterwards generalized and applied in the context of neural networks with ReLU activations. In particular, we make use of the intuition it provides, in order to minimize a two-layer fully connected network, trained for a binary classification problem. This method is later evaluated on a variety of experiments, demonstrating its capability to approximate a network, with minimal loss in performance.