 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Cinemetrics : Structured Taxonomy and Evaluation for Professional Video Generation
Sep 30, 2025Recent advances in video generation have enabled high-fidelity video synthesis from user provided prompts. However, existing models and benchmarks fail to capture the complexity and requirements of professional video generation. Towards that goal, we introduce Stable Cinemetrics, a structured evaluation framework that formalizes filmmaking controls into four disentangled, hierarchical taxonomies: Setup, Event, Lighting, and Camera. Together, these taxonomies define 76 fine-grained control nodes grounded in industry practices. Using these taxonomies, we construct a benchmark of prompts aligned with professional use cases and develop an automated pipeline for prompt categorization and question generation, enabling independent evaluation of each control dimension. We conduct a large-scale human study spanning 10+ models and 20K videos, annotated by a pool of 80+ film professionals. Our analysis, both coarse and fine-grained reveal that even the strongest current models exhibit significant gaps, particularly in Events and Camera-related controls. To enable scalable evaluation, we train an automatic evaluator, a vision-language model aligned with expert annotations that outperforms existing zero-shot baselines. SCINE is the first approach to situate professional video generation within the landscape of video generative models, introducing taxonomies centered around cinematic controls and supporting them with structured evaluation pipelines and detailed analyses to guide future research.
Unlocking Intrinsic Fairness in Stable Diffusion
Aug 22, 2024



Recent text-to-image models like Stable Diffusion produce photo-realistic images but often show demographic biases. Previous debiasing methods focused on training-based approaches, failing to explore the root causes of bias and overlooking Stable Diffusion's potential for unbiased image generation. In this paper, we demonstrate that Stable Diffusion inherently possesses fairness, which can be unlocked to achieve debiased outputs. Through carefully designed experiments, we identify the excessive bonding between text prompts and the diffusion process as a key source of bias. To address this, we propose a novel approach that perturbs text conditions to unleash Stable Diffusion's intrinsic fairness. Our method effectively mitigates bias without additional tuning, while preserving image-text alignment and image quality.
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Mar 05, 2024



Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
The Role of Pre-training Data in Transfer Learning
Mar 01, 2023



The transfer learning paradigm of model pre-training and subsequent fine-tuning produces high-accuracy models. While most studies recommend scaling the pre-training size to benefit most from transfer learning, a question remains: what data and method should be used for pre-training? We investigate the impact of pre-training data distribution on the few-shot and full fine-tuning performance using 3 pre-training methods (supervised, contrastive language-image and image-image), 7 pre-training datasets, and 9 downstream datasets. Through extensive controlled experiments, we find that the choice of the pre-training data source is essential for the few-shot transfer, but its role decreases as more data is made available for fine-tuning. Additionally, we explore the role of data curation and examine the trade-offs between label noise and the size of the pre-training dataset. We find that using 2000X more pre-training data from LAION can match the performance of supervised ImageNet pre-training. Furthermore, we investigate the effect of pre-training methods, comparing language-image contrastive vs. image-image contrastive, and find that the latter leads to better downstream accuracy
REPAIR: REnormalizing Permuted Activations for Interpolation Repair
Nov 15, 2022



In this paper we look into the conjecture of Entezari et al.(2021) which states that if the permutation invariance of neural networks is taken into account, then there is likely no loss barrier to the linear interpolation between SGD solutions. First, we observe that neuron alignment methods alone are insufficient to establish low-barrier linear connectivity between SGD solutions due to a phenomenon we call variance collapse: interpolated deep networks suffer a collapse in the variance of their activations, causing poor performance. Next, we propose REPAIR (REnormalizing Permuted Activations for Interpolation Repair) which mitigates variance collapse by rescaling the preactivations of such interpolated networks. We explore the interaction between our method and the choice of normalization layer, network width, and depth, and demonstrate that using REPAIR on top of neuron alignment methods leads to 60%-100% relative barrier reduction across a wide variety of architecture families and tasks. In particular, we report a 74% barrier reduction for ResNet50 on ImageNet and 90% barrier reduction for ResNet18 on CIFAR10.
Studying the impact of magnitude pruning on contrastive learning methods
Jul 01, 2022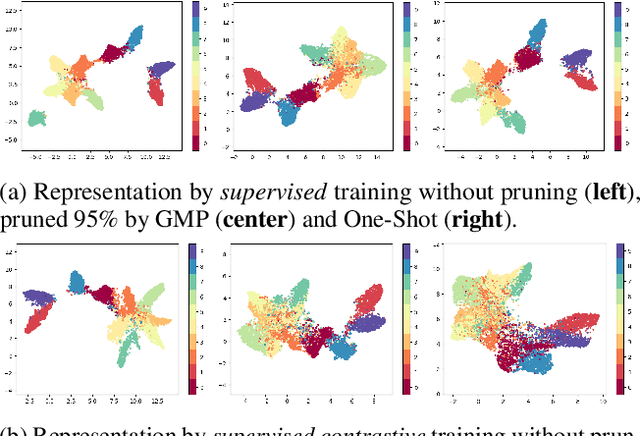
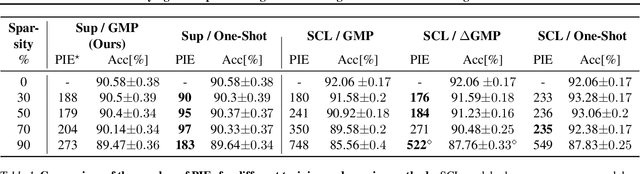

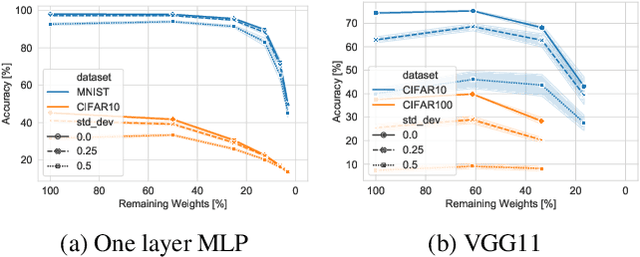
We study the impact of different pruning techniques on the representation learned by deep neural networks trained with contrastive loss functions. Our work finds that at high sparsity levels, contrastive learning results in a higher number of misclassified examples relative to models trained with traditional cross-entropy loss. To understand this pronounced difference, we use metrics such as the number of PIEs (Hooker et al., 2019), Q-Score (Kalibhat et al., 2022), and PD-Score (Baldock et al., 2021) to measure the impact of pruning on the learned representation quality. Our analysis suggests the schedule of the pruning method implementation matters. We find that the negative impact of sparsity on the quality of the learned representation is the highest when pruning is introduced early on in the training phase.
Understanding the effect of sparsity on neural networks robustness
Jun 22, 2022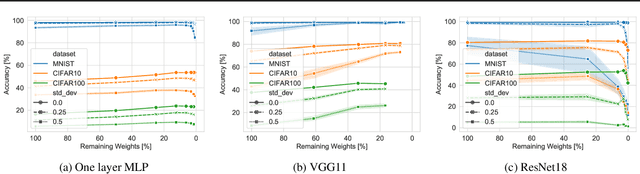
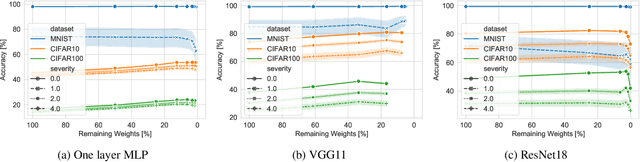
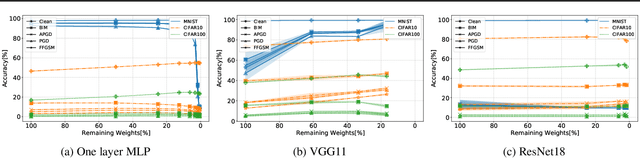
This paper examines the impact of static sparsity on the robustness of a trained network to weight perturbations, data corruption, and adversarial examples. We show that, up to a certain sparsity achieved by increasing network width and depth while keeping the network capacity fixed, sparsified networks consistently match and often outperform their initially dense versions. Robustness and accuracy decline simultaneously for very high sparsity due to loose connectivity between network layers. Our findings show that a rapid robustness drop caused by network compression observed in the literature is due to a reduced network capacity rather than sparsity.
Deep Neural Network Pruning for Nuclei Instance Segmentation in Hematoxylin & Eosin-Stained Histological Images
Jun 15, 2022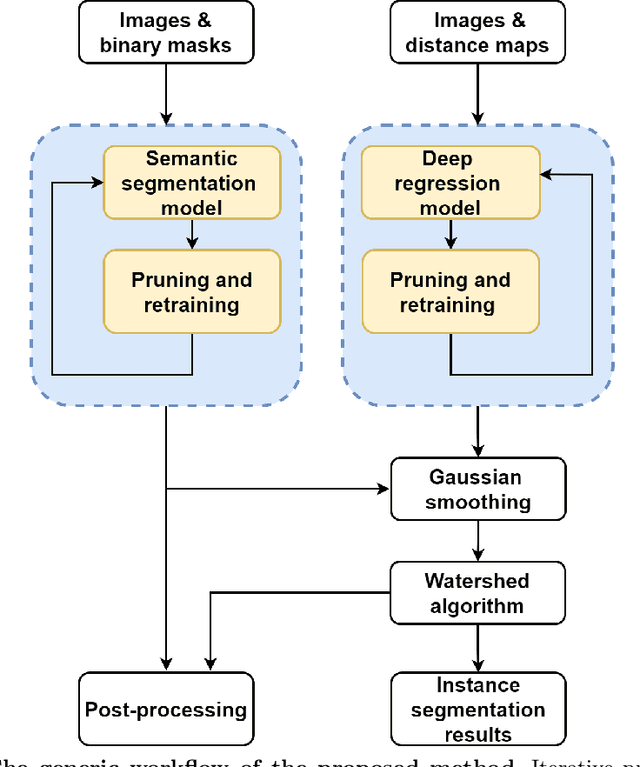

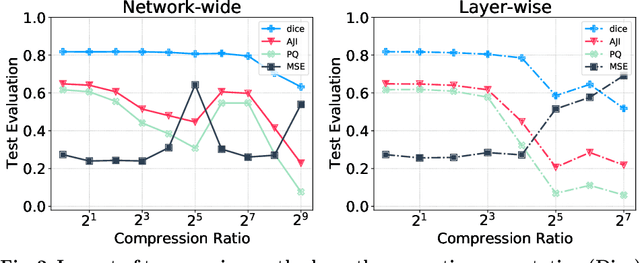
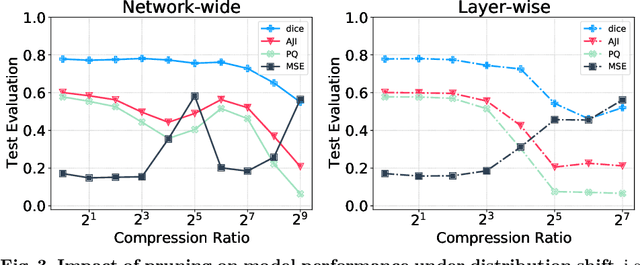
Recently, pruning deep neural networks (DNNs) has received a lot of attention for improving accuracy and generalization power, reducing network size, and increasing inference speed on specialized hardwares. Although pruning was mainly tested on computer vision tasks, its application in the context of medical image analysis has hardly been explored. This work investigates the impact of well-known pruning techniques, namely layer-wise and network-wide magnitude pruning, on the nuclei instance segmentation performance in histological images. Our utilized instance segmentation model consists of two main branches: (1) a semantic segmentation branch, and (2) a deep regression branch. We investigate the impact of weight pruning on the performance of both branches separately and on the final nuclei instance segmentation result. Evaluated on two publicly available datasets, our results show that layer-wise pruning delivers slightly better performance than networkwide pruning for small compression ratios (CRs) while for large CRs, network-wide pruning yields superior performance. For semantic segmentation, deep regression and final instance segmentation, 93.75 %, 95 %, and 80 % of the model weights can be pruned by layer-wise pruning with less than 2 % reduction in the performance of respective models.
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks
Oct 12, 2021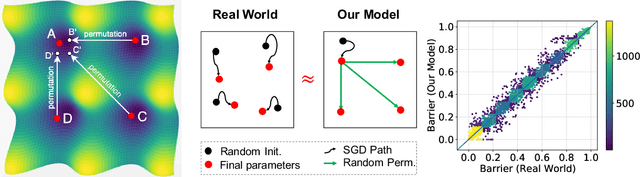
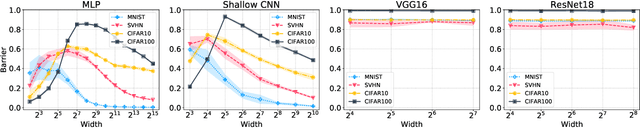
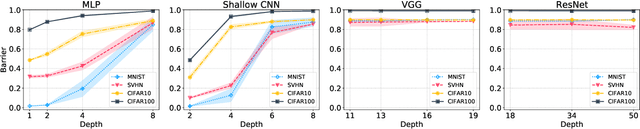
In this paper, we conjecture that if the permutation invariance of neural networks is taken into account, SGD solutions will likely have no barrier in the linear interpolation between them. Although it is a bold conjecture, we show how extensive empirical attempts fall short of refuting it. We further provide a preliminary theoretical result to support our conjecture. Our conjecture has implications for lottery ticket hypothesis, distributed training, and ensemble methods.