 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Level Costs for Nuanced Classifier Evaluation
May 04, 2026Standard classification treats all errors equally, but in content moderation, medical screening, and safety-critical applications, mistakes on clear-cut cases are far more costly than errors on ambiguous ones. We propose normalized excess cost (NEC), a metric that weights classification errors by per-example costs and reduces to standard error rate when costs are uniform. Costs can derive from annotator vote margins, distance from decision thresholds, or confidence ratings. Across text, image, and tabular benchmarks, we find that NEC is often substantially lower than error rate -- models with 5\% error rate can achieve 1.8\% NEC -- revealing that most mistakes concentrate on ambiguous, low-cost examples. However, incorporating costs into training via loss weighting, sampling strategies, or regression yields inconsistent benefits: improvements appear only when costs are predictable from input features, as in our synthetic control, while real-world datasets show mixed or negligible gains. Our framework provides a practical methodology for deriving and evaluating instance-level misclassification costs, even when cost-sensitive training offers limited benefit.
An Experimental Design Framework for Label-Efficient Supervised Finetuning of Large Language Models
Jan 12, 2024



Supervised finetuning (SFT) on instruction datasets has played a crucial role in achieving the remarkable zero-shot generalization capabilities observed in modern large language models (LLMs). However, the annotation efforts required to produce high quality responses for instructions are becoming prohibitively expensive, especially as the number of tasks spanned by instruction datasets continues to increase. Active learning is effective in identifying useful subsets of samples to annotate from an unlabeled pool, but its high computational cost remains a barrier to its widespread applicability in the context of LLMs. To mitigate the annotation cost of SFT and circumvent the computational bottlenecks of active learning, we propose using experimental design. Experimental design techniques select the most informative samples to label, and typically maximize some notion of uncertainty and/or diversity. In our work, we implement a framework that evaluates several existing and novel experimental design techniques and find that these methods consistently yield significant gains in label efficiency with little computational overhead. On generative tasks, our methods achieve the same generalization performance with only $50\%$ of annotation cost required by random sampling.
LabelBench: A Comprehensive Framework for Benchmarking Label-Efficient Learning
Jun 16, 2023



Labeled data are critical to modern machine learning applications, but obtaining labels can be expensive. To mitigate this cost, machine learning methods, such as transfer learning, semi-supervised learning and active learning, aim to be label-efficient: achieving high predictive performance from relatively few labeled examples. While obtaining the best label-efficiency in practice often requires combinations of these techniques, existing benchmark and evaluation frameworks do not capture a concerted combination of all such techniques. This paper addresses this deficiency by introducing LabelBench, a new computationally-efficient framework for joint evaluation of multiple label-efficient learning techniques. As an application of LabelBench, we introduce a novel benchmark of state-of-the-art active learning methods in combination with semi-supervised learning for fine-tuning pretrained vision transformers. Our benchmark demonstrates better label-efficiencies than previously reported in active learning. LabelBench's modular codebase is open-sourced for the broader community to contribute label-efficient learning methods and benchmarks. The repository can be found at: https://github.com/EfficientTraining/LabelBench.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
VOCALExplore: Pay-as-You-Go Video Data Exploration and Model Building
Mar 07, 2023



We introduce VOCALExplore, a system designed to support users in building domain-specific models over video datasets. VOCALExplore supports interactive labeling sessions and trains models using user-supplied labels. VOCALExplore maximizes model quality by automatically deciding how to select samples based on observed skew in the collected labels. It also selects the optimal video representations to use when training models by casting feature selection as a rising bandit problem. Finally, VOCALExplore implements optimizations to achieve low latency without sacrificing model performance. We demonstrate that VOCALExplore achieves close to the best possible model quality given candidate acquisition functions and feature extractors, and it does so with low visible latency (~1 second per iteration) and no expensive preprocessing.
Active Learning with Expected Error Reduction
Nov 17, 2022Active learning has been studied extensively as a method for efficient data collection. Among the many approaches in literature, Expected Error Reduction (EER) (Roy and McCallum) has been shown to be an effective method for active learning: select the candidate sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model to be retrained for every candidate sample and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper we reformulate EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method (such as arXiv:1506.02142). We then compare the empirical performance of our method using Monte Carlo dropout for parameter sampling against state of the art methods in the deep active learning literature. Experiments are performed on four standard benchmark datasets and three WILDS datasets (arXiv:2012.07421). The results indicate that our method outperforms all other methods except one in the data shift scenario: a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost (arXiv:1906.03671).
Comparing the Value of Labeled and Unlabeled Data in Method-of-Moments Latent Variable Estimation
Mar 03, 2021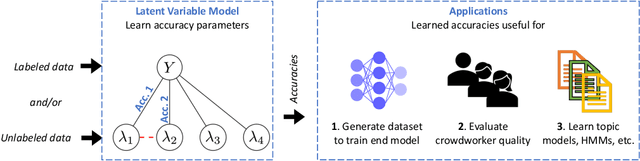
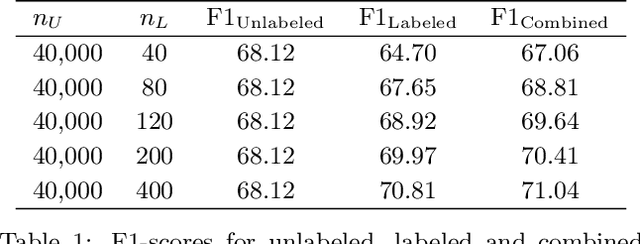
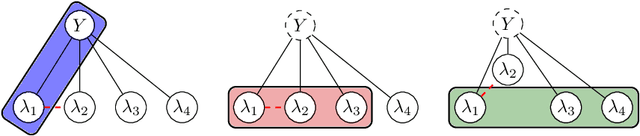

Labeling data for modern machine learning is expensive and time-consuming. Latent variable models can be used to infer labels from weaker, easier-to-acquire sources operating on unlabeled data. Such models can also be trained using labeled data, presenting a key question: should a user invest in few labeled or many unlabeled points? We answer this via a framework centered on model misspecification in method-of-moments latent variable estimation. Our core result is a bias-variance decomposition of the generalization error, which shows that the unlabeled-only approach incurs additional bias under misspecification. We then introduce a correction that provably removes this bias in certain cases. We apply our decomposition framework to three scenarios -- well-specified, misspecified, and corrected models -- to 1) choose between labeled and unlabeled data and 2) learn from their combination. We observe theoretically and with synthetic experiments that for well-specified models, labeled points are worth a constant factor more than unlabeled points. With misspecification, however, their relative value is higher due to the additional bias but can be reduced with correction. We also apply our approach to study real-world weak supervision techniques for dataset construction.
On the Importance of Adaptive Data Collection for Extremely Imbalanced Pairwise Tasks
Oct 10, 2020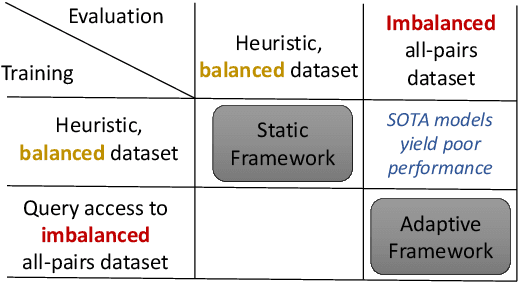
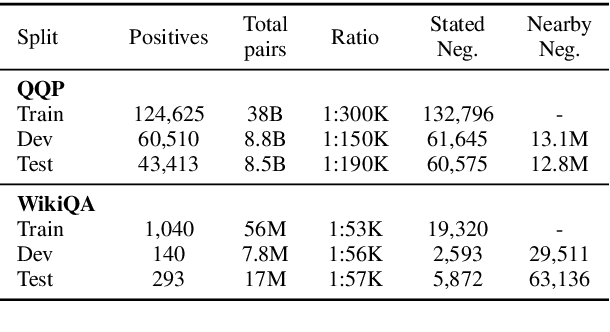
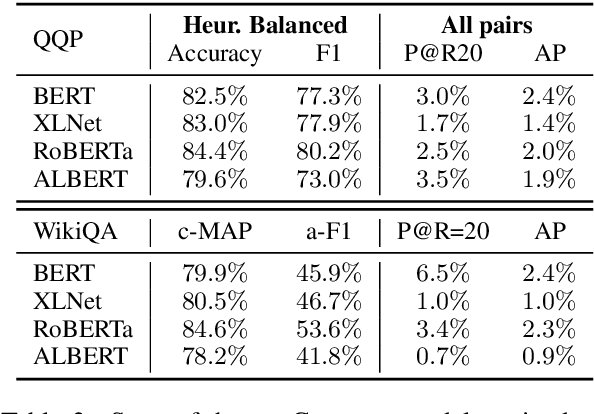
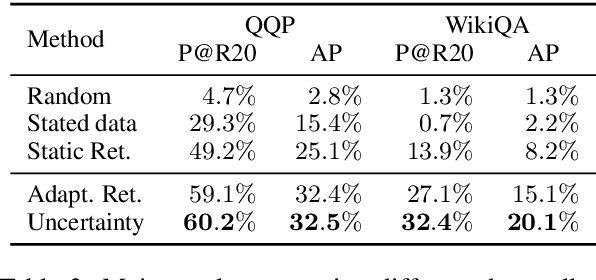
Many pairwise classification tasks, such as paraphrase detection and open-domain question answering, naturally have extreme label imbalance (e.g., $99.99\%$ of examples are negatives). In contrast, many recent datasets heuristically choose examples to ensure label balance. We show that these heuristics lead to trained models that generalize poorly: State-of-the art models trained on QQP and WikiQA each have only $2.4\%$ average precision when evaluated on realistically imbalanced test data. We instead collect training data with active learning, using a BERT-based embedding model to efficiently retrieve uncertain points from a very large pool of unlabeled utterance pairs. By creating balanced training data with more informative negative examples, active learning greatly improves average precision to $32.5\%$ on QQP and $20.1\%$ on WikiQA.
Concept Bottleneck Models
Jul 09, 2020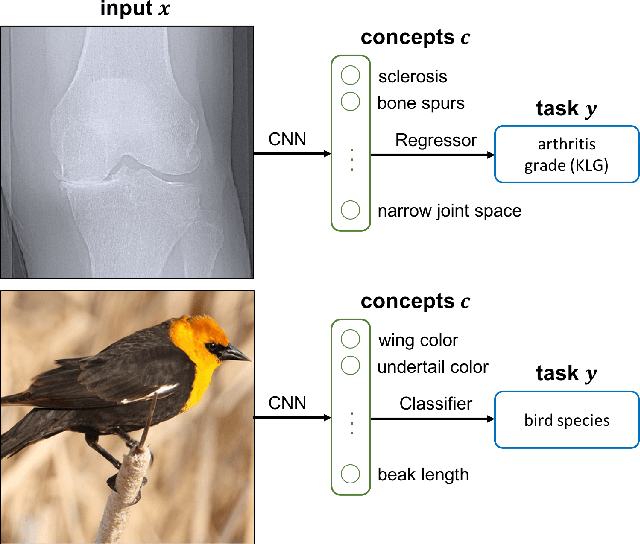
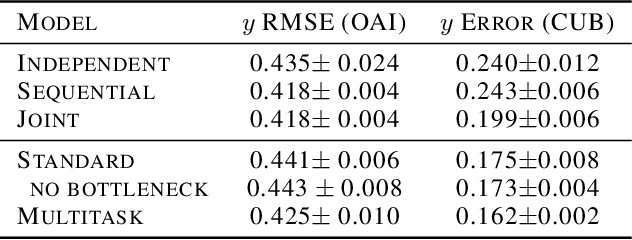
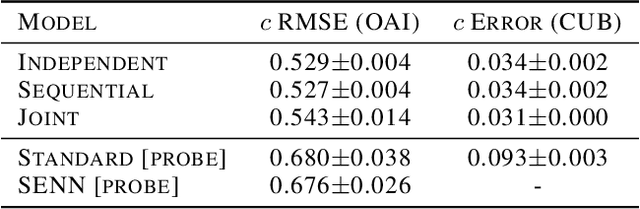
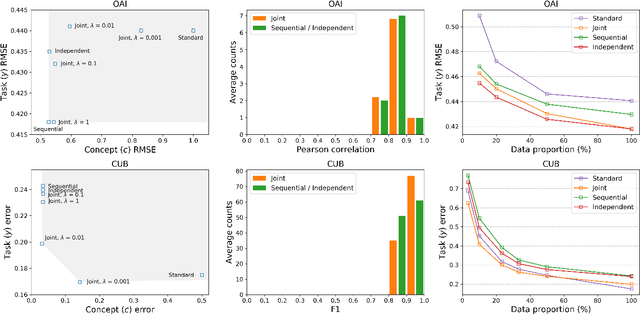
We seek to learn models that we can interact with using high-level concepts: if the model did not think there was a bone spur in the x-ray, would it still predict severe arthritis? State-of-the-art models today do not typically support the manipulation of concepts like "the existence of bone spurs", as they are trained end-to-end to go directly from raw input (e.g., pixels) to output (e.g., arthritis severity). We revisit the classic idea of first predicting concepts that are provided at training time, and then using these concepts to predict the label. By construction, we can intervene on these \emph{concept bottleneck models} by editing their predicted concept values and propagating these changes to the final prediction. On x-ray grading and bird identification, concept bottleneck models achieve competitive accuracy with standard end-to-end models, while enabling interpretation in terms of high-level clinical concepts ("bone spurs") or bird attributes ("wing color"). These models also allow for richer human-model interaction: accuracy improves significantly if we can correct model mistakes on concepts at test time.
A Tight Analysis of Greedy Yields Subexponential Time Approximation for Uniform Decision Tree
Jun 26, 2019
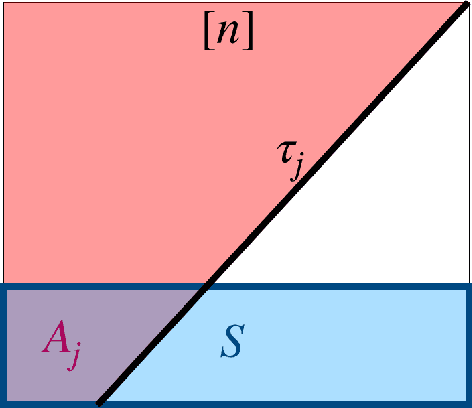
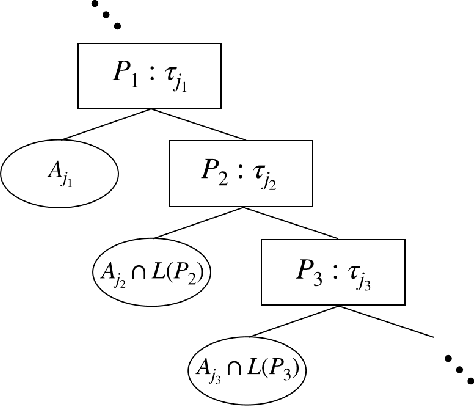
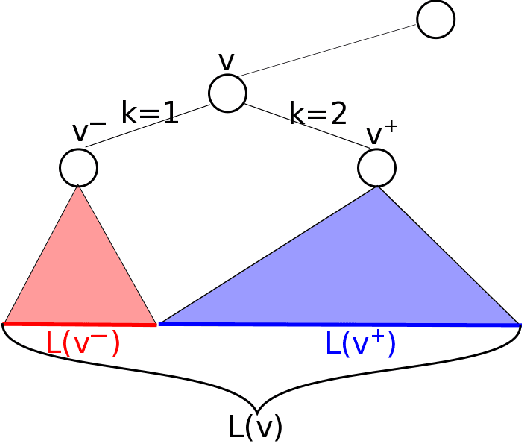
Decision Tree is a classic formulation of active learning: given $n$ hypotheses with nonnegative weights summing to 1 and a set of tests that each partition the hypotheses, output a decision tree using the provided tests that uniquely identifies each hypothesis and has minimum (weighted) average depth. Previous works showed that the greedy algorithm achieves a $O(\log n)$ approximation ratio for this problem and it is NP-hard beat a $O(\log n)$ approximation, settling the complexity of the problem. However, for Uniform Decision Tree, i.e. Decision Tree with uniform weights, the story is more subtle. The greedy algorithm's $O(\log n)$ approximation ratio is the best known, but the largest approximation ratio known to be NP-hard is $4-\varepsilon$. We prove that the greedy algorithm gives a $O(\frac{\log n}{\log C_{OPT}})$ approximation for Uniform Decision Tree, where $C_{OPT}$ is the cost of the optimal tree and show this is best possible for the greedy algorithm. As a corollary, this resolves a conjecture of Kosaraju, Przytycka, and Borgstrom. Our results also hold for instances of Decision Tree whose weights are not too far from uniform. Leveraging this result, we exhibit a subexponential algorithm that yields an $O(1/\alpha)$ approximation to Uniform Decision Tree in time $2^{O(n^\alpha)}$. As a corollary, achieving any super-constant approximation ratio on Uniform Decision Tree is not NP-hard, assuming the Exponential Time Hypothesis. This work therefore adds approximating Uniform Decision Tree to a small list of natural problems that have subexponential algorithms but no known polynomial time algorithms. Like the greedy algorithm, our subexponential algorithm gives similar guarantees even for slightly nonuniform weights.