 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePennySynth: RAG-Driven Data Synthesis for Automated Quantum Code Generation
May 25, 2026The growing complexity of quantum programming frameworks has exposed a critical limitation in existing large language model (LLM)-based code assistants: general-purpose models hallucinate PennyLane-specific gate names, misplace device configurations, and produce structurally invalid circuits when faced with specialized quantum coding challenges. We present PennySynth, a retrieval-augmented generation framework that addresses this gap by conditioning LLM inference on a curated knowledge base of 13,389 PennyLane instruction-code pairs, built via a three-stage extraction, verification, and deduplication pipeline over official PennyLane repositories, community GitHub sources, and QHack competition archives. PennySynth introduces a code-aware embedding strategy using st-codesearch-distilroberta-base, trained for natural-language-to-code retrieval, increasing average retrieval cosine similarity from 0.45 to 0.726 compared to a general-purpose baseline. Evaluated across 74 challenges spanning three years of the QHack competition (2022, 2023, 2024), PennySynth achieves 64%, 68%, and 52% pass@5 on QHack 2022, 2023, and 2024, respectively, improving over Claude Sonnet 4.6 without retrieval by +28, +25, and +28 percentage points. We further introduce a quantum-adapted CodeBLEU metric that upweights qml.* token patterns and show that structural code similarity and functional correctness capture distinct aspects of quantum code quality. Controlled ablations reveal that code-aware embeddings are the primary driver of retrieval performance, while dataset expansion and source composition provide additional gains when retrieval quality is sufficiently precise.
Enhancing Blood Cells Classification using Hybrid Quantum Neural Networks
May 22, 2026Accurate classification of microscopic blood cells is still a critical task in medical image analysis, where subtle variations and limited data can challenge conventional deep learning models. As such, we investigate in this work the potential of Hybrid Quantum-Classical Neural Networks (HQNNs) to enhance feature representation and improve classification performance in this domain. We propose a modular architecture combining a pre-trained ResNet-50 backbone with a low-dimensional latent bottleneck and a variational quantum circuit, enabling a direct comparison between quantum-enhanced and purely classical transformation mechanisms. To isolate the contribution of the quantum component, we evaluate three architectures: a HQNN model, a Classical Matched Model with an additional nonlinear transformation layer of comparable capacity, and a baseline model without an intermediate transformation stage. Experiments conducted on two publicly available blood cell datasets, namely the Blood Cell Images dataset and the PBC dataset, demonstrate that HQNNs consistently achieve superior or more balanced performance across evaluation metrics. In the Blood Cell Images Dataset, the proposed approach improves macro F1-score by up to 3.7% compared to classical baselines, while improving the F1-score from 98.54% to 98.69% in the more challenging 8-class scenario with near-saturated performance. Additional evaluation on IBM quantum hardware shows that the model remains robust under noise, with only a modest performance degradation relative to simulated results. These results indicate that quantum feature transformations can enhance discriminative representations, particularly in challenging classification scenarios, and highlight the practical potential of HQNN models for medical imaging tasks.
Q-PhotoNAS: Hybrid Quantum Neural Architecture Search Framework on Photonic Devices
May 21, 2026Photonic quantum computing is a promising platform for scalable quantum machine learning, but designing effective hybrid architectures remains challenging under hardware and optimization constraints. Existing approaches rely on manually tuned architectures that fail to account for the collaboration between classical preprocessing, phase encoding, and photonic circuit structure, limiting both accuracy and hardware compatibility. In this paper, we propose a neural architecture search framework for hybrid photonic quantum-classical models that combines genetic algorithm-based search with learnable quantum phase encoding to systematically explore the joint design space of classical and quantum components. Our framework encodes 19 hyperparameters across six gene groups and evolves a population of hybrid architectures using group-based crossover, per-gene mutation, and elitism, evaluating each candidate on a short training budget before full retraining of the best found design. We evaluate our framework on two image classification benchmarks, Digits and MNIST, achieving final validation accuracies of 99.44% and 98.78%, respectively, with first-principles execution time estimates on the Quandela Ascella photonic QPU projecting single-image inference at 67 ms (Digits) and 149 ms (MNIST). Our quantum contribution analysis further shows that the photonic layer extracts non-redundant features orthogonal to the classical pathway, providing a measurable accuracy advantage over classical-only baselines. Our results demonstrate that automated architecture search is both practical and impactful for hybrid photonic systems, opening the way for systematic design space exploration of quantum AI on photonic devices.
Q-SpiRL: Quantum Spiking Reinforcement Learning for Adaptive Robot Navigation
May 20, 2026Adaptive robot navigation in dynamic environments requires policies that can reach the target reliably while producing efficient and stable trajectories. This paper presents Q-SpiRL, a quantum spiking reinforcement learning framework for obstacle-aware robot navigation. The framework develops and evaluates five agent families: tabular Q-learning, classical MLP, classical SNN, quantum-enhanced MLP (QMLP), and quantum-enhanced spiking neural network (QSNN). While all models are implemented under a unified training and evaluation pipeline, the QSNN is the central architecture of interest, as it combines spike-based temporal processing with variational quantum feature transformation. Experiments are conducted across three grid-world environments of increasing size, namely 20x20, 30x30, and 40x40, with both static and dynamic obstacles. Performance is assessed using success rate, success-weighted path length, path length, and turn rate under deterministic inference. Results show that QSNN achieves the strongest overall trade-off between task completion, trajectory efficiency, and motion smoothness, reaching up to 99% success rate while maintaining high path efficiency in the most challenging setting. Execution on IBM quantum hardware further demonstrates the feasibility of deploying the proposed hybrid policy under real-device conditions.
QLIF-CAST: Quantum Leaky-Integrate-and-Fire for Time-Series Weather Forecasting
May 18, 2026Accurate and efficient time-series forecasting remains a challenging problem for both classical and quantum neural architectures, particularly in multivariate environmental settings. This work adapts the Quantum Leaky Integrate-and-Fire (QLIF) spiking neural network for time-series regression tasks, specifically short-term multivariate weather forecasting. We extend QLIF beyond classification and demonstrate its applicability to continuous-valued prediction problems. The QLIF-CAST model encodes neuron excitation states as single-qubit quantum superpositions, driven by Rx rotation gates and T1 relaxation decay, and is embedded within a hybrid quantum-classical recurrent architecture. We conduct two distinct evaluations. First, a controlled comparison against a parameter-matched classical LIF baseline on a multivariate weather dataset shows that QLIF-CAST achieves 15.4% lower MSE and 4.4% lower MAE, demonstrating that quantum neuronal dynamics reduce prediction error over classical equivalents. Second, a cross-domain comparative analysis with state-of-the-art quantum LSTM (QLSTM) and quantum neural network (QNN) models on air quality and wind speed benchmarks reveals that QLIF-CAST converges in up to 94% less training time, occupying a distinct position in the speed-error trade-off space. Hardware verification on IBM Marrakesh (156-qubit QPU) confirms reliable circuit execution with only 1.2% average deviation from simulation.
Hybrid Quantum-Classical Neural Architecture Search
May 18, 2026Hybrid quantum-classical neural networks (HQNNs) are emerging as a practical approach for quantum machine learning in the noisy intermediate-scale quantum (NISQ) era, as they combine classical learning components with parameterized quantum circuits in an end-to-end trainable framework. However, their performance and efficiency depend strongly on architectural choices such as data encoding, circuit structure, measurement design, and the coupling between classical and quantum modules. This makes manual design increasingly difficult, especially when hardware limitations and resource constraints must also be taken into account. In this paper, we study the foundations of HQNNs and neural architecture search (NAS), discuss how NAS extends to quantum and hybrid settings, and demonstrate FLOPs-aware search (where FLOPs serve as a proxy for computational complexity), as an important hardware-aware direction for building HQNNs that are not only accurate but also computationally efficient and practically deployable.
How Embeddings Shape Graph Neural Networks: Classical vs Quantum-Oriented Node Representations
Apr 16, 2026Node embeddings act as the information interface for graph neural networks, yet their empirical impact is often reported under mismatched backbones, splits, and training budgets. This paper provides a controlled benchmark of embedding choices for graph classification, comparing classical baselines with quantum-oriented node representations under a unified pipeline. We evaluate two classical baselines alongside quantum-oriented alternatives, including a circuit-defined variational embedding and quantum-inspired embeddings computed via graph operators and linear-algebraic constructions. All variants are trained and tested with the same backbone, stratified splits, identical optimization and early stopping, and consistent metrics. Experiments on five different TU datasets and on QM9 converted to classification via target binning show clear dataset dependence: quantum-oriented embeddings yield the most consistent gains on structure-driven benchmarks, while social graphs with limited node attributes remain well served by classical baselines. The study highlights practical trade-offs between inductive bias, trainability, and stability under a fixed training budget, and offers a reproducible reference point for selecting quantum-oriented embeddings in graph learning.
Design Space Exploration of Hybrid Quantum Neural Networks for Chronic Kidney Disease
Apr 15, 2026Hybrid Quantum Neural Networks (HQNNs) have recently emerged as a promising paradigm for near-term quantum machine learning. However, their practical performance strongly depends on design choices such as classical-to-quantum data encoding, quantum circuit architecture, measurement strategy and shots. In this paper, we present a comprehensive design space exploration of HQNNs for Chronic Kidney Disease (CKD) diagnosis. Using a carefully curated and preprocessed clinical dataset, we benchmark 625 different HQNN models obtained by combining five encoding schemes, five entanglement architectures, five measurement strategies, and five different shot settings. To ensure fair and robust evaluation, all models are trained using 10-fold stratified cross-validation and assessed on a test set using a comprehensive set of metrics, including accuracy, area under the curve (AUC), F1-score, and a composite performance score. Our results reveal strong and non-trivial interactions between encoding choices and circuit architectures, showing that high performance does not necessarily require large parameter counts or complex circuits. In particular, we find that compact architectures combined with appropriate encodings (e.g., IQP with Ring entanglement) can achieve the best trade-off between accuracy, robustness, and efficiency. Beyond absolute performance analysis, we also provide actionable insights into how different design dimensions influence learning behavior in HQNNs.
QNAS: A Neural Architecture Search Framework for Accurate and Efficient Quantum Neural Networks
Apr 08, 2026Designing quantum neural networks (QNNs) that are both accurate and deployable on NISQ hardware is challenging. Handcrafted ansatze must balance expressivity, trainability, and resource use, while limited qubits often necessitate circuit cutting. Existing quantum architecture search methods primarily optimize accuracy while only heuristically controlling quantum and mostly ignore the exponential overhead of circuit cutting. We introduce QNAS, a neural architecture search framework that unifies hardware aware evaluation, multi objective optimization, and cutting overhead awareness for hybrid quantum classical neural networks (HQNNs). QNAS trains a shared parameter SuperCircuit and uses NSGA-II to optimize three objectives jointly: (i) validation error, (ii) a runtime cost proxy measuring wall clock evaluation time, and (iii) the estimated number of subcircuits under a target qubit budget. QNAS evaluates candidate HQNNs under a few epochs of training and discovers clear Pareto fronts that reveal tradeoffs between accuracy, efficiency, and cutting overhead. Across MNIST, Fashion-MNIST, and Iris benchmarks, we observe that embedding type and CNOT mode selection significantly impact both accuracy and efficiency, with angle-y embedding and sparse entangling patterns outperforming other configurations on image datasets, and amplitude embedding excelling on tabular data (Iris). On MNIST, the best architecture achieves 97.16% test accuracy with a compact 8 qubit, 2 layer circuit; on the more challenging Fashion-MNIST, 87.38% with a 5 qubit, 2 layer circuit; and on Iris, 100% validation accuracy with a 4 qubit, 2 layer circuit. QNAS surfaces these design insights automatically during search, guiding practitioners toward architectures that balance accuracy, resource efficiency, and practical deployability on current hardware.
FAQNAS: FLOPs-aware Hybrid Quantum Neural Architecture Search using Genetic Algorithm
Nov 13, 2025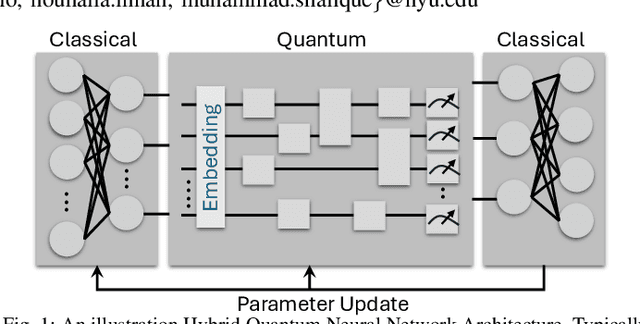
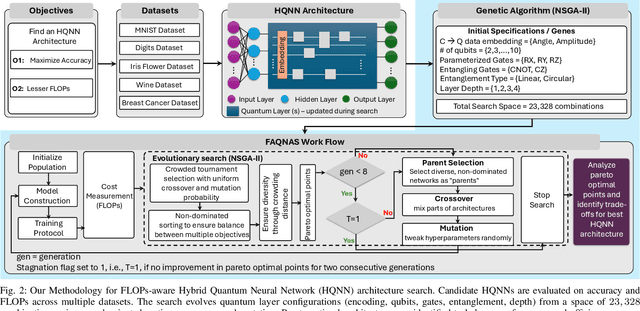
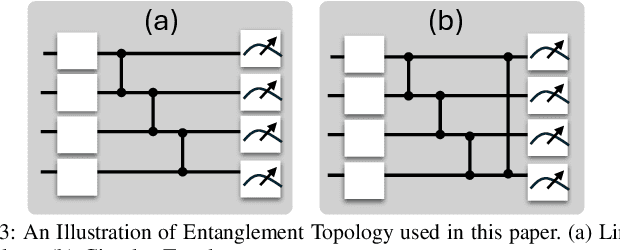
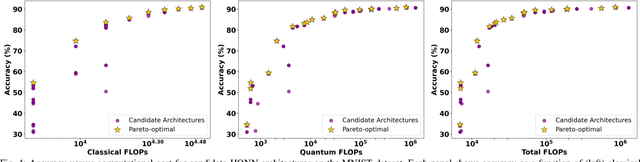
Hybrid Quantum Neural Networks (HQNNs), which combine parameterized quantum circuits with classical neural layers, are emerging as promising models in the noisy intermediate-scale quantum (NISQ) era. While quantum circuits are not naturally measured in floating point operations (FLOPs), most HQNNs (in NISQ era) are still trained on classical simulators where FLOPs directly dictate runtime and scalability. Hence, FLOPs represent a practical and viable metric to measure the computational complexity of HQNNs. In this work, we introduce FAQNAS, a FLOPs-aware neural architecture search (NAS) framework that formulates HQNN design as a multi-objective optimization problem balancing accuracy and FLOPs. Unlike traditional approaches, FAQNAS explicitly incorporates FLOPs into the optimization objective, enabling the discovery of architectures that achieve strong performance while minimizing computational cost. Experiments on five benchmark datasets (MNIST, Digits, Wine, Breast Cancer, and Iris) show that quantum FLOPs dominate accuracy improvements, while classical FLOPs remain largely fixed. Pareto-optimal solutions reveal that competitive accuracy can often be achieved with significantly reduced computational cost compared to FLOPs-agnostic baselines. Our results establish FLOPs-awareness as a practical criterion for HQNN design in the NISQ era and as a scalable principle for future HQNN systems.